基本块对齐(Basic Block Alignment)
有时,性能会因指令在内存中的布局偏移量不同而显著变化。考虑代码清单 LoopAlignment 中展示的一个简单函数,以及使用 -O3 -march=core-avx2 -fno-unroll-loops 编译后对应的机器码(禁用循环展开以便说明问题)。
代码清单:基本块对齐
void benchmark_func(int* a) { │ 00000000004046a0 <_Z14benchmark_funcPi>:
for (int i = 0; i < 32; ++i) │ 4046a0: mov rax,0xffffffffffffff80
a[i] += 1; │ 4046a7: vpcmpeqd ymm0,ymm0,ymm0
} │ 4046ab: nop DWORD [rax+rax+0x0]
│ 4046b0: vmovdqu ymm1,[rdi+rax+0x80] # loop begins
│ 4046b9: vpsubd ymm1,ymm1,ymm0
│ 4046bd: vmovdqu [rdi+rax+0x80],ymm1
│ 4046c6: add rax,0x20
│ 4046ca: jne 4046b0 # loop ends
│ 4046cc: vzeroupper
│ 4046cf: ret
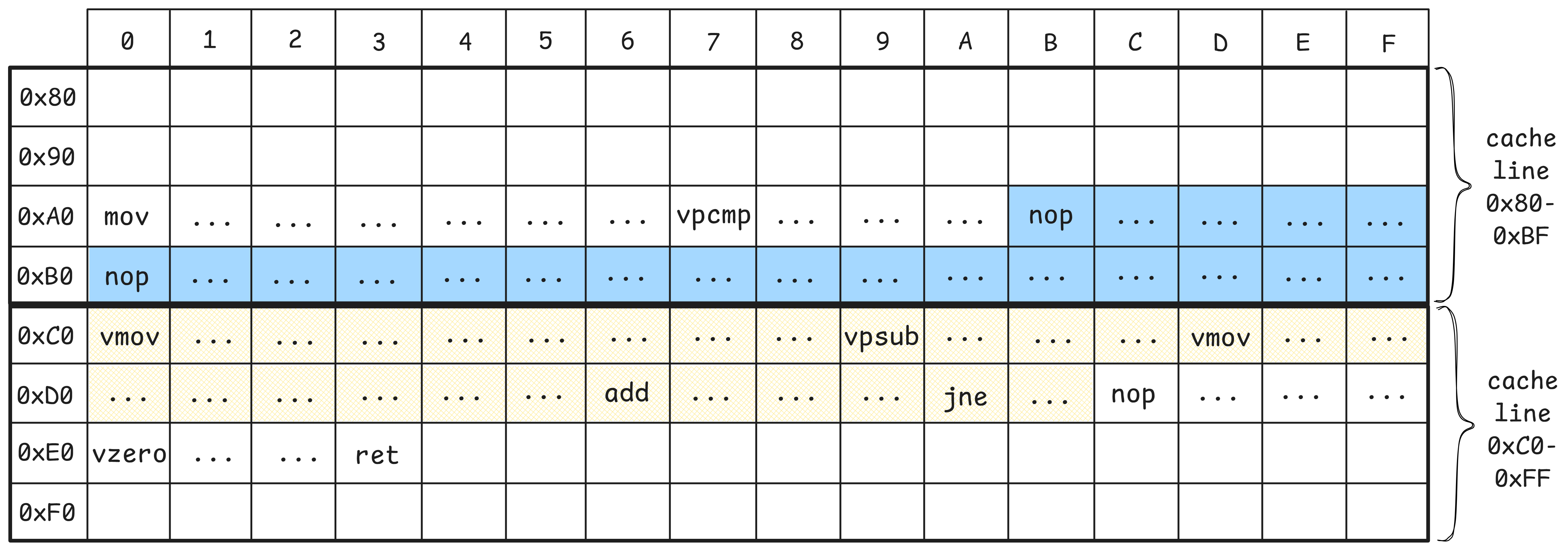
代码本身是合理的,但其布局并不完美(见图 Loop_default)。对应循环的指令以黄色高亮显示。粗框表示缓存行边界。缓存行长度为 64 字节。
default layout
improved layout
代码清单 LoopAlignment 中循环的两种不同代码布局。注意,循环跨越了多条缓存行:它从缓存行 0x80-0xBF 开始,在缓存行 0xC0-0xFF 中结束。为了获取循环中执行的指令,处理器需要读取两条缓存行。这类情况有时会给 CPU 前端带来性能问题,尤其是对于代码清单 LoopAlignment 中这样的小循环。
为了解决这个问题,我们可以使用一条 NOP 指令将循环指令向前移动 16 字节,使整个循环驻留在一条缓存行中。图 Loop_better 展示了使用 NOP 指令(以蓝色高亮)实现这一效果的结果。
有趣的是,即使你只在微基准测试中运行这个热循环,性能影响也是可见的。这有些令人困惑,因为代码量很少,不应该使任何现代 CPU 的 L1 I-cache 容量饱和。图 Loop_better 布局性能更好的原因并不简单,涉及相当多的微架构细节,本书不作讨论。感兴趣的读者可以在 Easyperf 博客的相关文章中找到更多信息。1
默认情况下,LLVM 编译器会识别循环并将其对齐到 16 字节边界,如图 Loop_default 所示。要为本示例实现如图 Loop_better 所示的期望代码放置,可以使用 -mllvm -align-all-blocks=5 选项,该选项会将目标文件中的每个基本块对齐到 32 字节边界。但是,我不建议使用此选项及类似选项,因为它们会影响翻译单元中所有函数的代码布局。还有其他侵入性更小的选项。
LLVM 编译器最近新增了 [[clang::code_align()]] 循环属性,允许开发者在源代码中指定循环的对齐方式。这为机器码布局提供了非常细粒度的控制。以下代码展示了如何使用新的 Clang 属性将循环对齐到 64 字节边界:
void benchmark_func(int* a) {
[[clang::code_align(64)]]
for (int i = 0; i < 32; ++i)
a[i] += 1;
}
在引入该属性之前,开发者不得不借助一些不太实用的解决方案,例如在源代码中注入 asm(".align 64;") 内联汇编语句。
尽管 CPU 架构师努力将机器码布局的影响降到最低,但仍有一些情况下代码放置(对齐)可能对性能产生差异。机器码布局也是性能测量中噪声的主要来源之一。这使得区分真正的性能提升或回退与因代码布局变化而意外造成的影响变得更加困难。
1. "代码对齐问题" - https://easyperf.net/blog/2018/01/18/Code_alignment_issues ↩