函数拆分(Function Splitting)
函数拆分背后的思想是将热代码与冷代码分离。这种变换也常被称为函数外联(function outlining)。此优化对于具有复杂控制流图(CFG)且热路径中包含大块冷代码的较大函数特别有效。代码清单 FunctionSplitting1 展示了一个可能从此变换中受益的代码示例。为了从热路径中移除冷基本块,我们将其剪切并粘贴到一个新函数中,并创建对它的调用。
代码清单:函数拆分:冷代码被外联到新函数中。
void foo(bool cond1, void foo(bool cond1,
bool cond2) { bool cond2) {
// hot path // hot path
if (cond1) { if (cond1) {
/* cold code (1) */ cold1();
} }
// hot path // hot path
if (cond2) { => if (cond2) {
/* cold code (2) */ cold2();
} }
} }
void cold1() __attribute__((noinline))
{ /* cold code (1) */ }
void cold2() __attribute__((noinline))
{ /* cold code (2) */ }
注意,我们使用 noinline 属性禁止冷函数被内联。因为如果不这样做,编译器可能会决定将其内联,这实际上会撤销我们的变换。或者,我们可以在 cond1 和 cond2 两个分支上都应用 [[unlikely]] 宏(参见 [secLIKELY]),向编译器传达不希望内联 cold1 和 cold2 函数的意图。
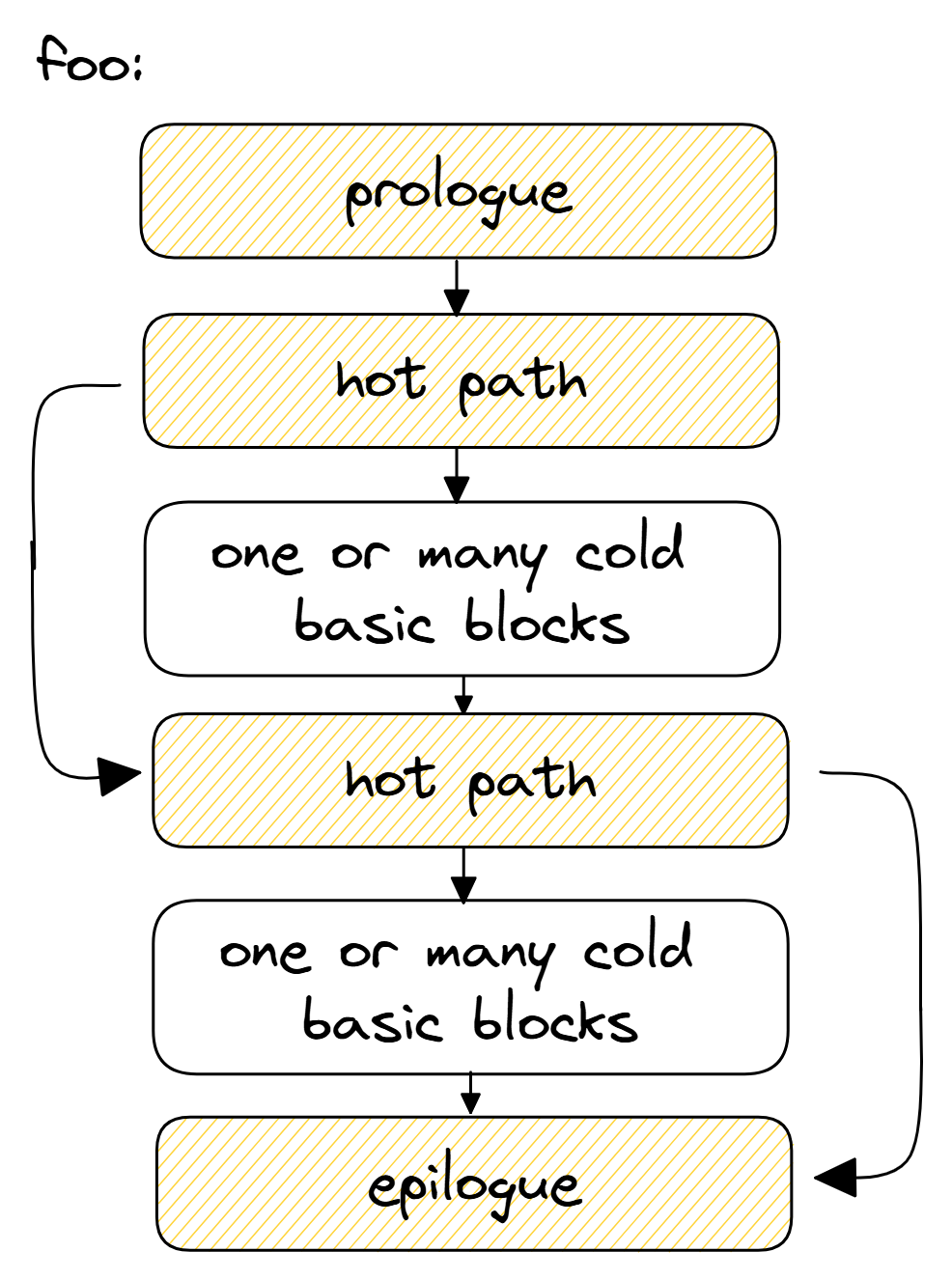
default layout
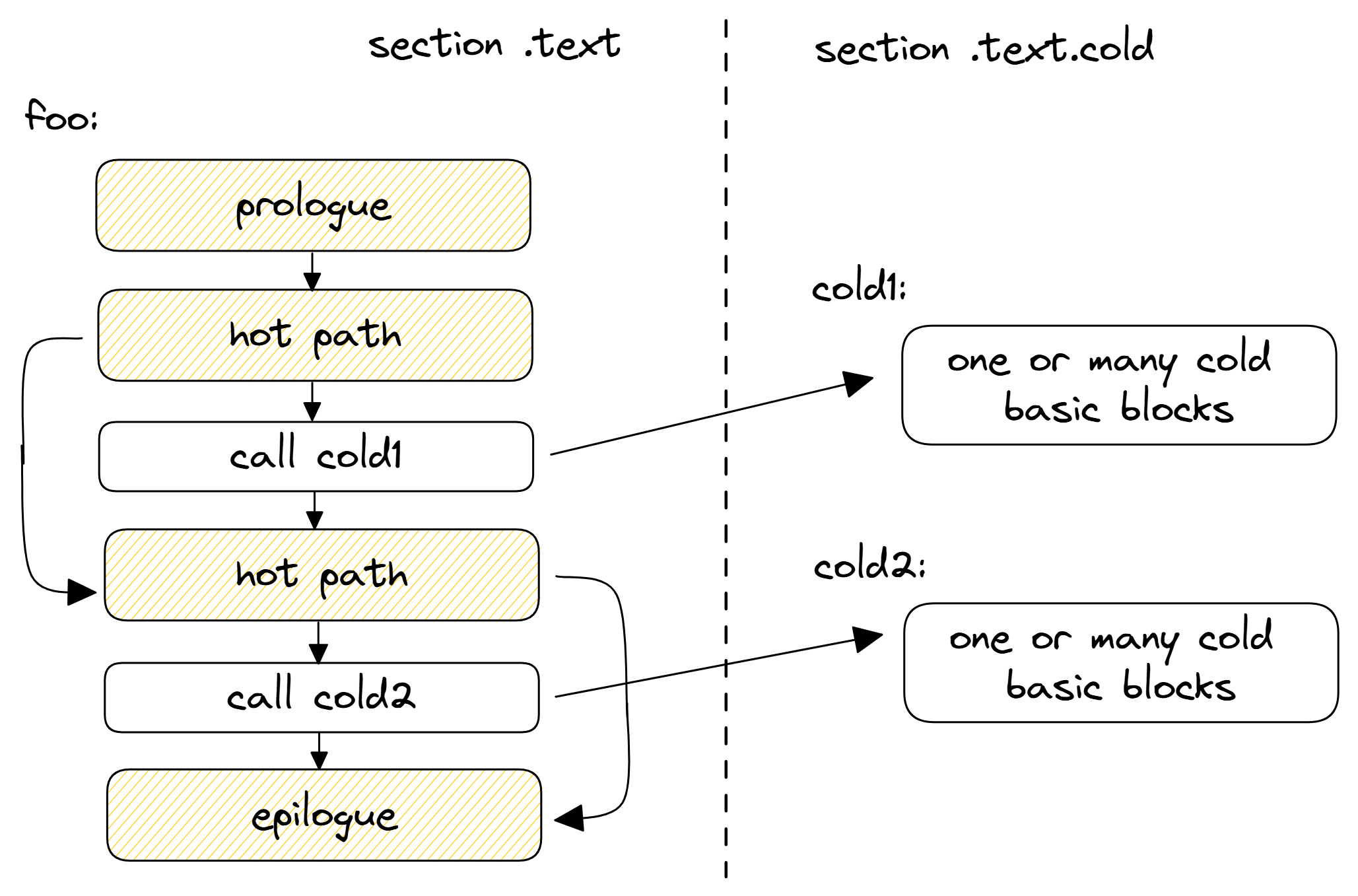improved layout
将冷代码拆分到单独函数中。图 FunctionSplitting 给出了此变换的图形表示。在改进的布局中,我们在热路径中只留下了一条 CALL 指令,下一条热指令很可能与前一条热指令位于同一缓存行中。这改善了 CPU 前端数据结构(如 I-cache 和 μop 缓存)的利用率。
外联的函数应该创建在 .text 段之外,例如放在 .text.cold 中。如果该函数从未被调用,这可以改善内存占用,因为它不会在运行时被加载到内存中。