SIMD 多处理器
另一种促进并行处理的技术称为单指令多数据(SIMD,Single Instruction Multiple Data),几乎所有高性能处理器都使用这种技术。顾名思义,在 SIMD 处理器中,单条指令利用许多独立的功能单元在单个周期内对多个数据元素进行操作。向量和矩阵上的操作非常适合 SIMD 架构,因为向量或矩阵的每个元素都可以使用同一条指令处理。SIMD 架构能够更高效地处理大量数据,最适合涉及向量运算的数据并行应用程序。
图 SIMD 展示了清单 SIMD 中代码的标量和 SIMD 执行模式。在传统的单指令单数据(SISD,Single Instruction Single Data)模式(也称为标量(scalar)模式)下,加法操作分别应用于数组 a 和 b 的每个元素。然而,在 SIMD 模式下,加法同时应用于多个元素。如果我们的目标 CPU 架构具有能够对 256 位向量进行操作的执行单元,我们可以用一条指令处理四个双精度元素。这导致发射的指令数减少 4 倍,相对于四次标量计算,可能获得 4 倍的加速。
清单:SIMD 执行
double *a, *b, *c;
for (int i = 0; i < N; ++i) {
c[i] = a[i] + b[i];
}
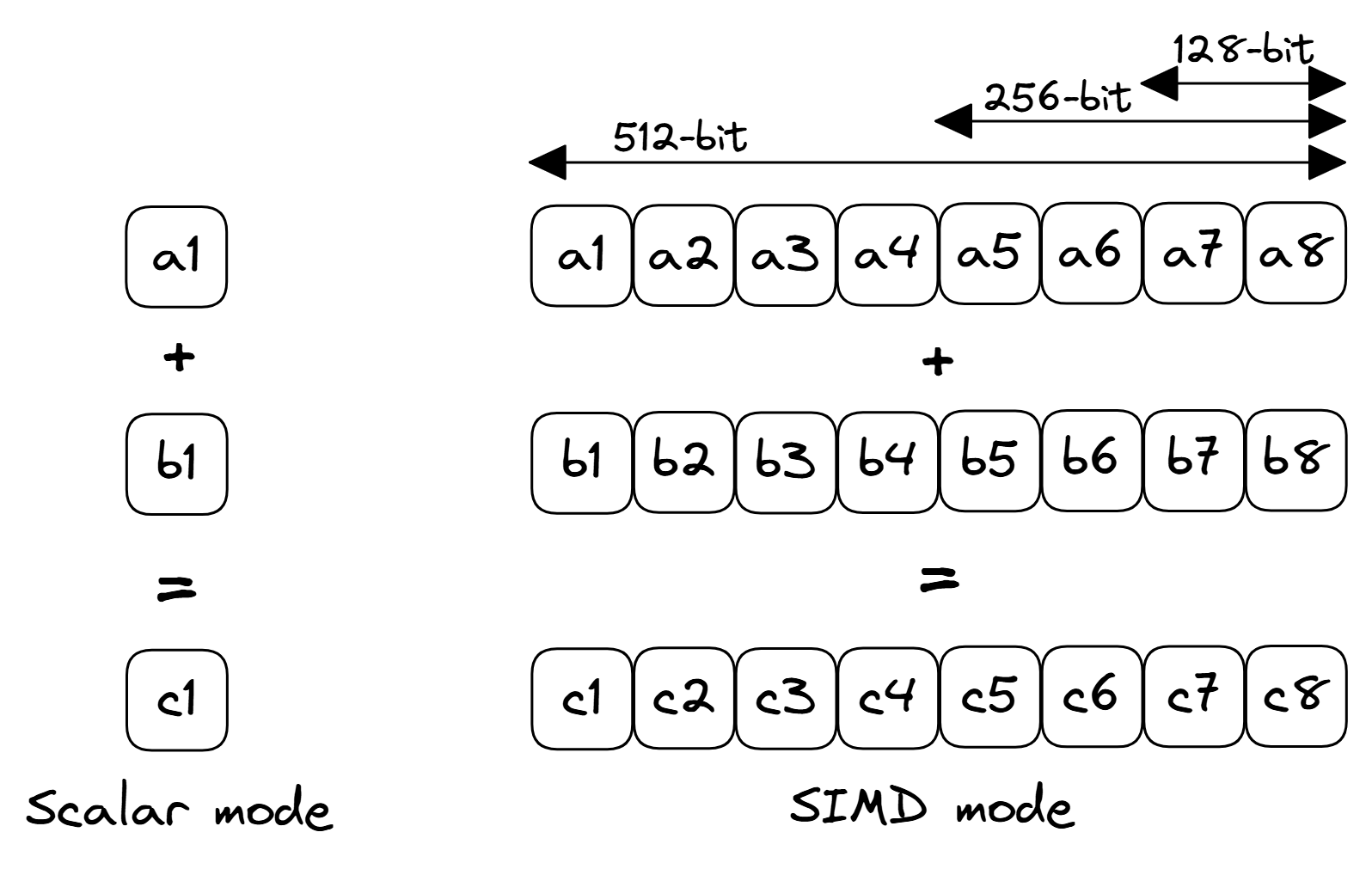
标量和 SIMD 操作示例。
对于常规整数 SISD 指令,处理器使用通用寄存器。类似地,对于 SIMD 指令,CPU 有一组 SIMD 寄存器,用于保存从内存加载的数据并存储计算的中间结果。在我们的例子中,对应数组 a 和 b 的两段各 256 位的连续数据将从内存加载并存储在两个独立的向量寄存器中。接下来,将进行逐元素加法,结果将存储在一个新的 256 位向量寄存器中。最后,结果将从向量寄存器写入到对应数组 c 的 256 位内存区域。注意,数据元素可以是整数或浮点数。
向量执行单元在逻辑上被划分为通道(lanes)。在 SIMD 的上下文中,通道是指 SIMD 执行单元内的独立数据通路,负责处理向量的一个元素。在我们的例子中,每个通道处理 64 位元素(双精度),因此 256 位寄存器中将有 4 个通道。
大多数流行的 CPU 架构都提供向量指令,包括 x86、PowerPC、ARM 和 RISC-V。1996 年,Intel 发布了 MMX,这是一种为多媒体应用设计的 SIMD 指令集。继 MMX 之后,Intel 引入了具有更多功能和更大向量的新指令集:SSE、AVX、AVX2 和 AVX-512。ARM 在其架构的各个版本中可选地支持 128 位 NEON 指令集。在第 8 版(aarch64)中,这一支持成为强制要求,并新增了指令。
随着新指令集的出现,开始着手使其对软件工程师可用。开发利用 SIMD 指令所需的软件修改被称为代码向量化(code vectorization)。最初,SIMD 指令是用汇编语言编写的。后来引入了特殊的编译器内建函数(compiler intrinsics),它们是与 SIMD 指令一一对应的小函数。如今,所有主流编译器都支持对流行处理器的自动向量化,即可以直接从用 C/C++、Java、Rust 和其他语言编写的高级代码生成 SIMD 指令。
为了使代码能够在支持不同向量长度的系统上运行,Arm 引入了 SVE 指令集。其定义性特征是可扩展向量(scalable vectors)的概念:其长度在编译时是未知的。使用 SVE,无需将软件移植到每种可能的向量长度。用户在新一代 CPU 中出现更宽的向量时,无需重新编译其应用程序的源代码。可扩展向量的另一个例子是 RISC-V V 扩展(RVV),于 2021 年底批准。一些实现支持相当宽(2048 位)的向量,最多可将 8 个向量组合在一起产生 16384 位向量,大大减少了执行的指令数量。在每次循环迭代中,SVE 代码通常执行 ptr += number_of_lanes,其中 number_of_lanes 在编译时是未知的。ARM SVE 提供了用于此类长度相关操作的特殊指令,而 RVV 使程序员能够查询/设置 number_of_lanes。
回到清单 SIMD 中的例子,如果 N 等于 5,而我们有一个 256 位向量,我们无法在单次迭代中处理所有元素。我们可以用一条 SIMD 指令处理前四个元素,但第 5 个元素需要单独处理。这被称为循环余数(loop remainder)。循环余数是循环中必须处理比向量宽度更少元素的部分,需要额外的标量代码来处理剩余元素。可扩展向量 ISA 扩展没有这个问题,因为它们可以用单条指令处理任意数量的元素。解决循环余数问题的另一种方案是使用掩码(masking),允许根据条件选择性地启用或禁用 SIMD 通道。
此外,CPU 越来越多地加速机器学习中常用的矩阵乘法。Intel 的 AMX 扩展自 2023 年起在服务器处理器中受支持,将 16x64 和 64x16 的 8 位矩阵相乘,累加到 32 位 16x16 矩阵中。相比之下,Apple CPU 中名称相同但无关的 AMX 扩展,以及 ARM 的 SME 扩展,计算行和列的外积,分别存储在特殊的 512 位寄存器或可扩展向量中。
最初,SIMD 由多媒体应用程序和科学计算驱动,但后来在许多其他领域也找到了用途。随着时间推移,SIMD 指令集中支持的操作集不断增加。除了图 SIMD 所示的简单算术外,SIMD 的较新用例包括:
- 字符串处理:查找字符、验证 UTF-81、解析 JSON2 和 CSV3;
- 哈希4、随机生成5、密码学(AES);
- 列式数据库(位打包、过滤、连接);
- 对内置类型排序(VQSort6、QuickSelect);
- 机器学习和人工智能(加速 PyTorch、TensorFlow)。
1. UTF-8 验证 - https://github.com/rusticstuff/simdutf8 ↩
2. 解析 JSON - https://github.com/simdjson/simdjson ↩
3. 解析 CSV - https://github.com/geofflangdale/simdcsv ↩
4. SIMD 哈希 - https://github.com/google/highwayhash ↩
5. 随机生成 - abseil 库 ↩
6. 排序 - VQSort ↩