编译器优化报告(Compiler Optimization Reports)
如今,软件开发非常依赖编译器来进行性能优化。编译器在加速软件方面发挥着关键作用。大多数开发者将优化代码的工作留给编译器,只有在看到编译器无法完成的改进机会时才会介入。公平地说,这是一个不错的默认策略。但当你寻求尽可能好的性能时,它就不那么有效了。如果编译器未能执行关键优化,例如向量化(vectorizing)一个循环,怎么办?你怎么知道这件事?幸运的是,所有主要编译器都提供优化报告,我们现在将对其进行讨论。
假设你想知道一个关键循环是否被展开(unrolled)。如果被展开了,展开因子(unroll factor)是多少?有一种困难的方法可以知道这一点:研究生成的汇编指令。不幸的是,并非所有人都擅长阅读汇编语言。如果函数很大、调用了其他函数、有许多也被向量化的循环,或者编译器为同一循环创建了多个版本,这可能会特别困难。包括 GCC、Clang、Intel 编译器和 MSVC9 在内的大多数编译器都提供优化报告,以检查对特定代码片段进行了哪些优化。
让我们看看代码清单 optReport,它展示了 clang 16.0 无法向量化的循环示例。
代码清单:a.c
void foo(float* __restrict__ a,
float* __restrict__ b,
float* __restrict__ c,
unsigned N) {
for (unsigned i = 1; i < N; i++) {
a[i] = c[i-1]; // value is carried over from previous iteration
c[i] = b[i];
}
}
要在 Clang 编译器中生成优化报告,你需要使用 -Rpass* 标志:
{% math_inline %} clang -O3 -Rpass-analysis=.* -Rpass=.* -Rpass-missed=.* a.c -c
a.c:5:3: remark: loop not vectorized [-Rpass-missed=loop-vectorize]
for (unsigned i = 1; i < N; i++) {
^
a.c:5:3: remark: unrolled loop by a factor of 8 with run-time trip count [-Rpass=loop-unroll]
for (unsigned i = 1; i < N; i++) {
^
通过检查上面的优化报告,我们可以看到循环没有被向量化,但它被展开了。对于开发者来说,识别代码清单 optReport 第 6 行循环中存在循环携带依赖(loop-carry dependency)并不总是容易的。由 c[i-1] 加载的值依赖于前一次迭代的存储(见图 VectorDep 中的操作 ② 和 ③)。通过手动展开循环的前几次迭代,可以揭示这种依赖关系:
// iteration 1
a[1] = c[0];
c[1] = b[1]; // writing the value to c[1]
// iteration 2
a[2] = c[1]; // reading the value of c[1]
c[2] = b[2];
...
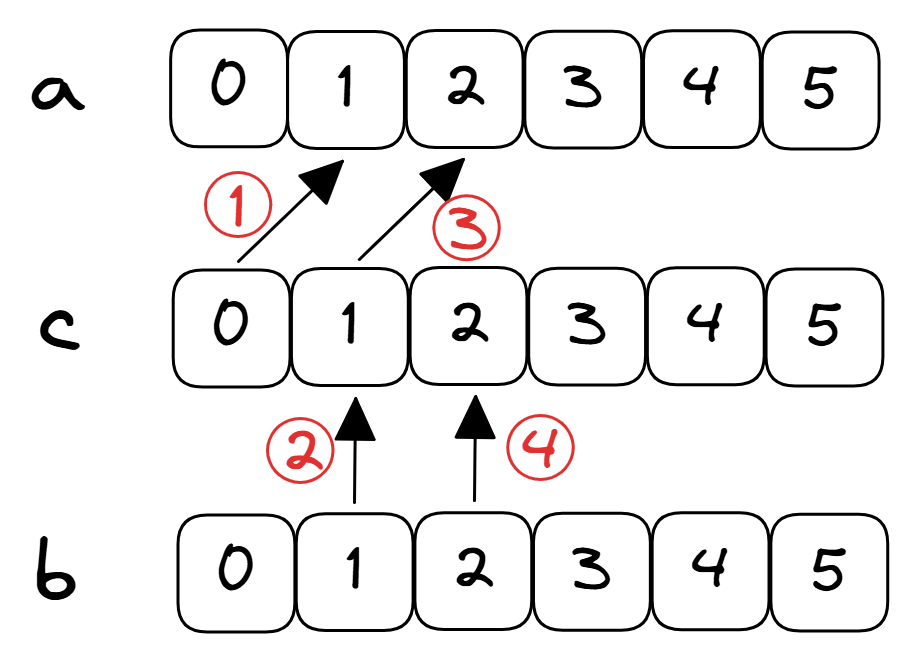
可视化代码清单 optReport 中的操作顺序。
如果我们对代码清单 optReport 中的代码进行向量化,将导致数组 a 中写入错误的值。假设 CPU SIMD 单元每次可以处理四个浮点数,我们将得到可以用以下伪代码表示的代码:
// iteration 1
a[1..4] = c[0..3]; // oops!, a[2..4] get wrong values
c[1..4] = b[1..4];
...
代码清单 optReport 中的代码无法被向量化,因为循环内操作的顺序很重要。这个示例可以通过交换第 6 行和第 7 行来修复,如代码清单 optReport2 所示。这不会改变代码的语义,因此这是一个完全合法的更改。或者,可以通过将循环拆分成两个独立的循环来改善代码。这样做会使循环开销翻倍,但这个缺点会被通过向量化获得的性能提升所抵消。
代码清单:a.c
void foo(float* __restrict__ a,
float* __restrict__ b,
float* __restrict__ c,
unsigned N) {
for (unsigned i = 1; i < N; i++) {
c[i] = b[i];
a[i] = c[i-1];
}
}
在优化报告中,我们现在可以看到循环被成功向量化:
{% endmath_inline %} clang -O3 -Rpass-analysis=.* -Rpass=.* -Rpass-missed=.* a.c -c
a.cpp:5:3: remark: vectorized loop (vectorization width: 8, interleaved count: 4) [-Rpass=loop-vectorize]
for (unsigned i = 1; i < N; i++) {
^
这只是使用优化报告的一个示例;我们将在 [DiscoverVectOpptnt] 中提供更多示例,在那里我们讨论如何发现向量化机会。编译器优化报告可以帮助你找到遗漏的优化机会,并理解这些机会为何被遗漏。此外,编译器优化报告对于测试假设也很有用。编译器通常根据其代价模型(cost model)分析来决定某个特定转换是否有益。但编译器并不总是做出最优选择。一旦在报告中检测到关键的缺失优化,你可以尝试通过更改源代码或以 #pragma、属性(attribute)、编译器内置函数(compiler built-in)等形式向编译器提供提示来纠正它。一如既往,通过在实际环境中测量来验证你的假设。
编译器报告可能相当大,且每个源代码文件都会生成单独的报告。有时,在输出文件中找到相关记录可能成为一项挑战。我们应该提到,这些报告最初是专门为编译器编写者设计的,用于改进优化流程。多年来,一些工具被开发出来,使优化报告对应用程序开发者更加易于访问和可操作,最值得注意的是 opt-viewer7 和 optview2。8 此外,Compiler Explorer 网站为基于 LLVM 的编译器提供了"Optimization Output"工具,当你将鼠标悬停在相应的源代码行上时,它会报告已执行的转换。所有这些工具都有助于可视化 LLVM 编译器成功和失败的代码转换。
在链接时优化(Link-Time Optimization,LTO)5 模式下,某些优化是在链接阶段进行的。要从编译和链接阶段都输出编译器报告,你应该将专用选项传递给编译器和链接器。有关更多信息,请参阅 LLVM "Remarks"指南。6
Intel® ISPC3 编译器(在 [ISPC] 中讨论)采用了一种略有不同的方式来报告缺失的优化。它对编译为相对低效代码的代码结构发出警告。无论如何,编译器优化报告都应该是你工具箱中的关键工具之一。它们是一种快速检查对特定热点进行了哪些优化以及是否有重要优化失败的方法。我已经通过编译器优化报告发现了许多改进机会。
1. 使用编译器优化 pragmas - https://easyperf.net/blog/2017/11/09/Multiversioning_by_trip_counts ↩
3. ISPC - https://ispc.github.io/ispc.html ↩
5. 链接时优化(Link-Time Optimizations),也称为过程间优化(InterProcedural Optimizations,IPO)。更多信息请参阅:https://en.wikipedia.org/wiki/Interprocedural_optimization ↩
6. LLVM 编译器备注 - https://llvm.org/docs/Remarks.html ↩
7. opt-viewer - https://github.com/llvm/llvm-project/tree/main/llvm/tools/opt-viewer ↩
8. optview2 - https://github.com/OfekShilon/optview2 ↩
9. 在撰写本文时(2024 年),MSVC 仅提供向量化报告。 ↩