持续基准测试
我们刚才讨论了为什么应该在生产环境中监控性能。另一方面,建立持续的"内部"测试以尽早发现性能问题仍然是有益的,尽管不是所有性能回归都能在实验室中被发现。
软件供应商不断寻求加快产品交付速度的方法。许多公司每隔几个月或几周就会部署新编写的代码。遗憾的是,软件产品并不会随着每个新版本的发布而获得更好的性能。性能缺陷以令人担忧的速度渗入生产软件 [UnderstandingPerfRegress]。大量的代码变更对彻底分析其性能影响构成了挑战。
性能回归(performance regressions)是指使软件运行速度比前一版本更慢的缺陷。捕获性能回归(或改进)需要检测出改变程序性能的那次提交。从数据库系统到搜索引擎再到编译器,在持续演进和部署生命周期中,几乎所有大规模软件系统都会经历性能回归。在软件开发过程中可能无法完全避免性能回归,但借助适当的测试和诊断工具,可以显著降低此类缺陷悄悄渗入生产代码的可能性。
使用图表跟踪应用程序的性能是有益的,例如图 PerfRegress 所示。使用此类图表,你可以看到历史趋势,找到性能改进或下降的时间点。通常,你的每个性能测试对应图表上的一条独立折线。不要在单个图表上包含过多的基准测试,否则会变得非常嘈杂。
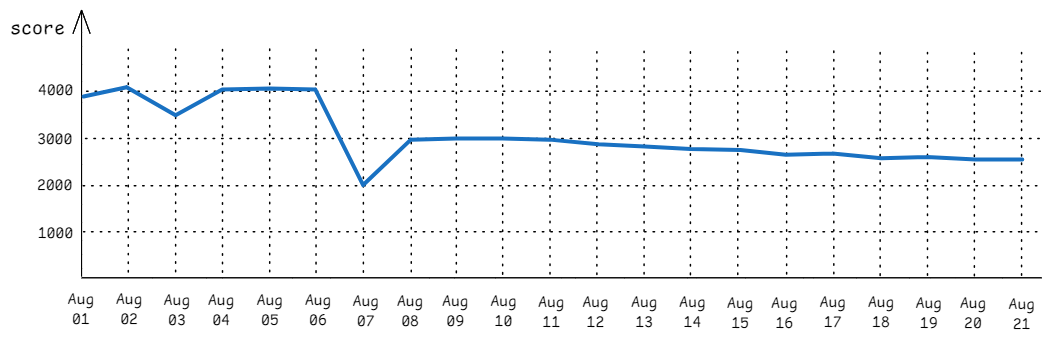
应用程序的性能图(越高越好),显示 8 月 7 日出现了一次大幅性能下降,随后还有几次较小的下降。
让我们考虑一些检测性能回归的潜在解决方案。第一个想法是:让人工查看图表。对于图 PerfRegress 中的图表,人工可能会发现 8 月 7 日发生的性能回归,但他们不一定会察觉到后来更小的回归。人们容易分心,可能会错过回归,尤其是在繁忙的图表上。此外,这是一项耗时且枯燥的工作,必须每天进行。
8 月 3 日还有另一个有趣的性能下降。开发者可能也会注意到它,但我们大多数人都会忍不住将其忽略,因为性能在第二天就恢复了。但我们能确定这只是测量中的一个故障吗?如果这是一个真实的回归,而恰好被 8 月 4 日的一项优化所补偿呢?如果我们能修复该回归同时保留那项优化,我们的性能分数将达到约 4500。不要忽视此类情况。一种处理方式是重复 8 月 2 日至 4 日期间的测量,并检查该期间的代码变更。
第二种方案是设置一个阈值,比如 2%。每项性能在该阈值范围内的代码修改被视为噪声,超出阈值的则被视为回归。这比第一种方案略好,但仍有其自身的缺点。性能测试中的波动是不可避免的:有时,即使是无害的代码变更也可能触发基准测试的性能变化。3 选择合适的阈值极其困难,且不能保证假阳性(false-positive)和假阴性(false-negative)告警的低发生率。将阈值设置得太低,可能导致分析一堆并非由源代码变更引起、而是由随机噪声导致的小幅回归。将阈值设置得太高,可能会过滤掉真实的性能回归。
小幅回归可以慢慢累积成更大的回归,从而被忽视。回到图 PerfRegress,注意从 8 月 11 日到 21 日持续的下行趋势。这段时间从 3000 分开始,以 2600 分结束。这大约是 10 天内 15% 的回归,平均每天约 1.5%。如果我们设置 2% 的阈值,所有回归都会被过滤掉。然而如我们所见,累积的回归远大于阈值。
尽管如此,这种方案对许多项目来说效果相当不错,特别是当基准测试的噪声水平非常低时。你也可以为每个测试调整阈值。LUCI2 是一个持续集成(CI, Continuous Integration)系统的例子,其中每个测试都需要设置明确的阈值来触发回归警报,它是 Chromium 项目的一部分。
值得一提的是,随时间跟踪性能结果需要维护运行基准测试的机器配置保持不变。配置的变更可能会使所有以前的性能结果失效。你可能决定用新配置重新收集所有历史测量数据,但这代价非常高昂。
另一种最近变得流行的方案采用统计方法来识别性能回归。它利用一种称为"变更点检测(CPD, Change Point Detection)"的算法(参见 [ChangePointAnalysis]),该算法利用历史数据并识别性能发生变化的时间点。许多性能监控系统采用了 CPD 算法,包括几个开源项目。你可以在网络上搜索最适合你需求的工具。
CPD 的显著优点是不需要设置阈值。该算法评估大量近期结果窗口,这使其能够将异常值视为噪声忽略,并减少误报。CPD 的缺点是缺乏即时反馈。例如,考虑一个性能测试的历史运行时间测量数据:5 秒、6 秒、5 秒、5 秒、7 秒。如果下一次基准测试结果为 11 秒,那么阈值方案可能会被超过,并立即生成告警。然而,使用 CPD 算法的话,此时不会有任何动作。如果下一次运行性能恢复到 5 秒,CPD 很可能将其视为误报而不生成告警。相反,如果随后一两次运行分别得到 10 秒和 12 秒,CPD 算法才会触发告警。
哪种方法更好并没有明确答案。如果你的开发流程需要即时反馈(例如,在合并拉取请求之前进行评估),那么使用阈值是更好的选择。此外,如果你能从系统中消除大量噪声并获得稳定的性能结果,那么使用阈值更为合适。在一个非常安静的系统中,前面提到的 11 秒测量结果很可能表明真实的性能回归,因此我们需要尽早标记它。相反,如果你的系统中有大量噪声(例如,你运行分布式宏基准测试),那么 11 秒的结果可能只是一个误报。在这种情况下,使用变更点检测可能更为合适。
典型的 CI 性能跟踪系统应自动化以下操作:
- 搭建被测系统。
- 运行基准测试套件。
- 报告结果。
- 确定性能是否发生变化。
- 对性能的意外变化发出告警。
- 可视化结果供人工分析。
CI 性能跟踪系统的另一个理想功能是允许开发者在将补丁提交到代码库之前,先提交性能评估任务。这大大简化了开发者的工作,有助于加快实验的迭代速度。代码变更的性能影响通常被包含在签入标准(check-in criteria)列表中。
如果出于某种原因,性能回归已经渗入代码库,及时发现它至关重要。首先,自回归发生以来合并的变更越少,就越容易找到问题根因,并能让负责该回归的人员在转向其他任务之前处理该问题。此外,由于所有细节在开发者脑海中仍然清晰,因此比几周后更容易着手解决回归问题。
最后,CI 系统不仅应就软件性能回归发出告警,对意外的性能改进也应如此。例如,有人可能提交了一个看似无害的提交,在自动化跟踪系统中使性能提升了 10%。你最初的本能可能是庆祝这次幸运的性能提升并继续工作。然而,虽然这次提交可能通过了 CI 流水线中的所有功能测试,但这种意外改进很可能揭示了功能测试中的一个盲点,而这只在性能回归结果中才表现出来。例如,该变更导致应用程序跳过了某些工作,而这部分工作没有被功能测试覆盖。这种情况发生得足够频繁,值得特别提及:将自动化性能回归测试框架视为整体软件测试框架的一部分。
综上所述,我们强烈建议建立一个自动化的统计性能跟踪系统。尝试不同的算法,看哪种最适合你的应用程序。这肯定需要时间,但对项目未来的性能健康状况来说是一项坚实的投资。
2. LUCI - https://chromium.googlesource.com/chromium/src.git/+/master/docs/tour_of_luci_ui.md ↩
3. 以下文章表明,更改函数顺序或删除死函数可能导致性能变化:https://easyperf.net/blog/2018/01/18/Code_alignment_issues ↩