内存延迟与带宽(Memory Latency and Bandwidth)
低效的内存访问往往是现代环境中主要的性能瓶颈。因此,处理器从内存子系统获取数据的速度是决定应用程序性能的关键因素。内存性能有两个方面:1) CPU 从内存获取单个字节的速度(延迟,latency),以及 2) 每秒可以获取多少字节(带宽,bandwidth)。两者在不同场景下都很重要;我们稍后会看几个例子。在本节中,我们将重点测量内存子系统各组件的峰值性能。
在 x86 平台上,一个有用的工具是 Intel 内存延迟检测器(MLC,Memory Latency Checker)1,它可在 Windows 和 Linux 上免费获取。MLC 可以使用不同的访问模式和在负载下测量缓存和内存的延迟与带宽。在基于 ARM 的系统上没有类似工具,但用户可以从源代码下载和构建内存延迟和带宽基准测试工具。此类项目的示例包括 lmbench2、bandwidth4 和 Stream。3
我们只关注一部分指标,即空闲读延迟(idle read latency)和读带宽(read bandwidth)。先从读延迟开始。"空闲"意味着在进行测量时,系统处于空闲状态。这将给出从内存系统组件获取数据所需的最短时间,但当系统被其他"内存密集型"应用程序加载时,访问延迟会增加,因为各个点的资源队列可能更多。MLC 通过执行依赖加载(dependent load,也称为指针追逐,pointer chasing)来测量空闲延迟。测量线程分配一个非常大的缓冲区,并对其进行初始化,使缓冲区内每个(64字节)缓存行都包含一个指向缓冲区内另一个非相邻缓存行的指针。通过适当调整缓冲区大小,我们可以确保几乎所有加载都命中某个特定层级的缓存或主内存。
我的测试系统是一台 Intel Alder Lake 计算机,搭载 Core i7-1260P CPU 和 16GB DDR4 @ 2400 MT/s 双通道内存。该处理器有 4 个 P(性能,Performance)超线程核心和 8 个 E(效率,Efficient)核心。每个 P 核具有 48 KB 的 L1 数据缓存和 1.25 MB 的 L2 缓存。每个 E 核具有 32 KB 的 L1 数据缓存,四个 E 核组成一个集群,共享一个 2 MB 的 L2 缓存。系统中所有核心都由一个 18 MB 的 L3 缓存提供支持。如果使用 10 MB 的缓冲区,我们几乎可以确定对该缓冲区的重复访问会在 L2 中未命中但在 L3 中命中。以下是示例 mlc 命令:
{% math_inline %} sudo ./mlc --idle_latency -c0 -L -b10m
Intel(R) Memory Latency Checker - v3.10
Command line parameters: --idle_latency -c0 -L -b10m
Using buffer size of 10.000MiB
Each iteration took 31.1 base frequency clocks ( 12.5 ns)
选项 --idle_latency 在不加载系统的情况下测量读延迟。此外,MLC 还有 --loaded_latency 选项,用于在有其他线程产生内存流量时测量延迟。选项 -c0 将测量线程固定到逻辑 CPU 0,该 CPU 位于 P 核上。选项 -L 启用大页(huge page)以限制 TLB 对测量结果的影响。选项 -b10m 告知 MLC 使用 10 MB 的缓冲区,该缓冲区可放入我们系统的 L3 缓存中。
图 MemoryLatenciesCharts 展示了 L1、L2 和 L3 缓存的读延迟。图表上有四个不同的区域。从 1 KB 到 48 KB 缓冲区大小的最左侧第一区域对应 L1 D-cache,它是每个物理核心私有的。我们可以观察到 E 核的延迟为 0.9 ns,P 核略高为 1.1 ns。此外,我们可以用这张图确认缓存大小。注意当缓冲区大小超过 32 KB 后 E 核延迟开始上升,而 P 核延迟在 48 KB 之前保持不变。这证实了 E 核的 L1 D-cache 大小为 32 KB,P 核为 48 KB。
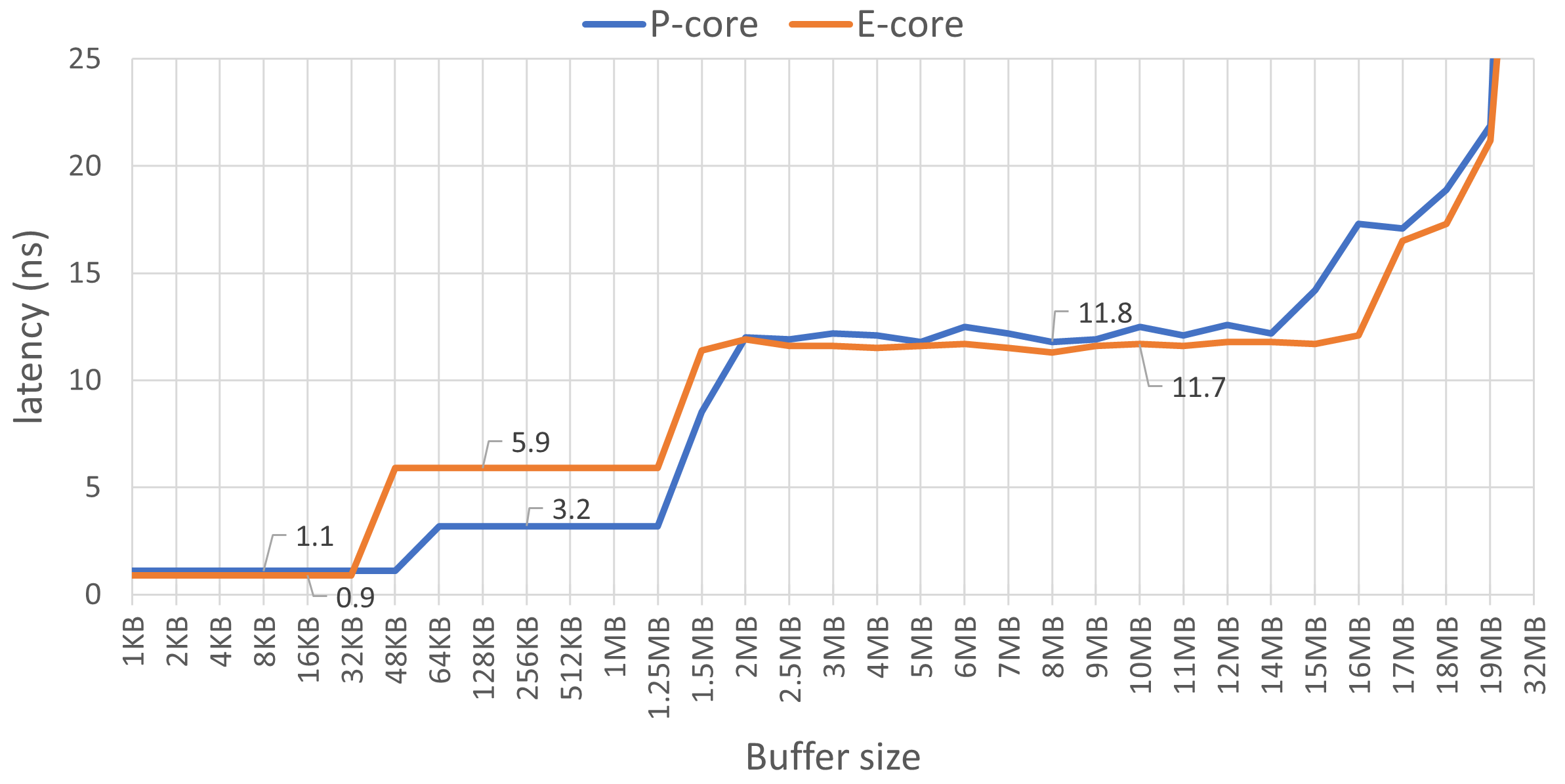
Intel Core i7-1260P 上 L1/L2/L3 缓存读延迟(越低越好),使用 MLC 工具测量,启用大页。
第二区域显示了 L2 缓存延迟,E 核几乎是 P 核的两倍(5.9 ns vs. 3.2 ns)。对于 P 核,当缓冲区大小超过 1.25 MB 后延迟增加,这在意料之中。我们预计 E 核延迟在超过 2 MB 之前保持不变,但根据我们的测量结果,这一现象发生得更早。
从 2 MB 到 14 MB 的第三区域对应 L3 缓存延迟,两种类型的核心大约都是 12 ns。系统中所有核心共享的 L3 缓存总大小为 18 MB。有趣的是,从 15 MB 开始就出现了一些意外的动态变化,而不是从 18 MB 开始。这很可能与部分访问在 L3 中未命中并需要从主内存获取有关。
我没有展示对应内存延迟的图表部分,该部分从超过 18 MB 边界后开始。延迟开始急剧攀升,并在 E 核 24 MB 和 P 核 64 MB 处趋于平稳。使用更大的缓冲区(例如 500 MB),E 核访问延迟为 45 ns,P 核为 90 ns。这衡量的是内存延迟,因为几乎没有加载命中 L3 缓存。
使用类似的技术,我们可以测量内存层次结构各组件的带宽。对于带宽测量,MLC 执行加载请求,其结果不会被任何后续指令使用。这使 MLC 能够产生最大可能的带宽。MLC 在每个配置的逻辑处理器上生成一个软件线程。每个线程访问的地址是独立的,线程之间不共享数据。与延迟实验一样,线程使用的缓冲区大小决定了 MLC 测量的是 L1/L2/L3 缓存带宽还是内存带宽。
{% endmath_inline %} sudo ./mlc --max_bandwidth -k0-15 -Y -L -u -b18m
Measuring Maximum Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : 349670.42
这里有几个新选项。-k 选项指定用于测量的 CPU 核心列表。-Y 选项告知 MLC 使用 AVX2 加载,即每次 32 字节。使用 -u 标志时,每个线程共享同一缓冲区,而不是分配自己的缓冲区。此选项必须用于测量 L3 带宽(注意我们使用了 18 MB 的缓冲区,等于 L3 缓存大小)。
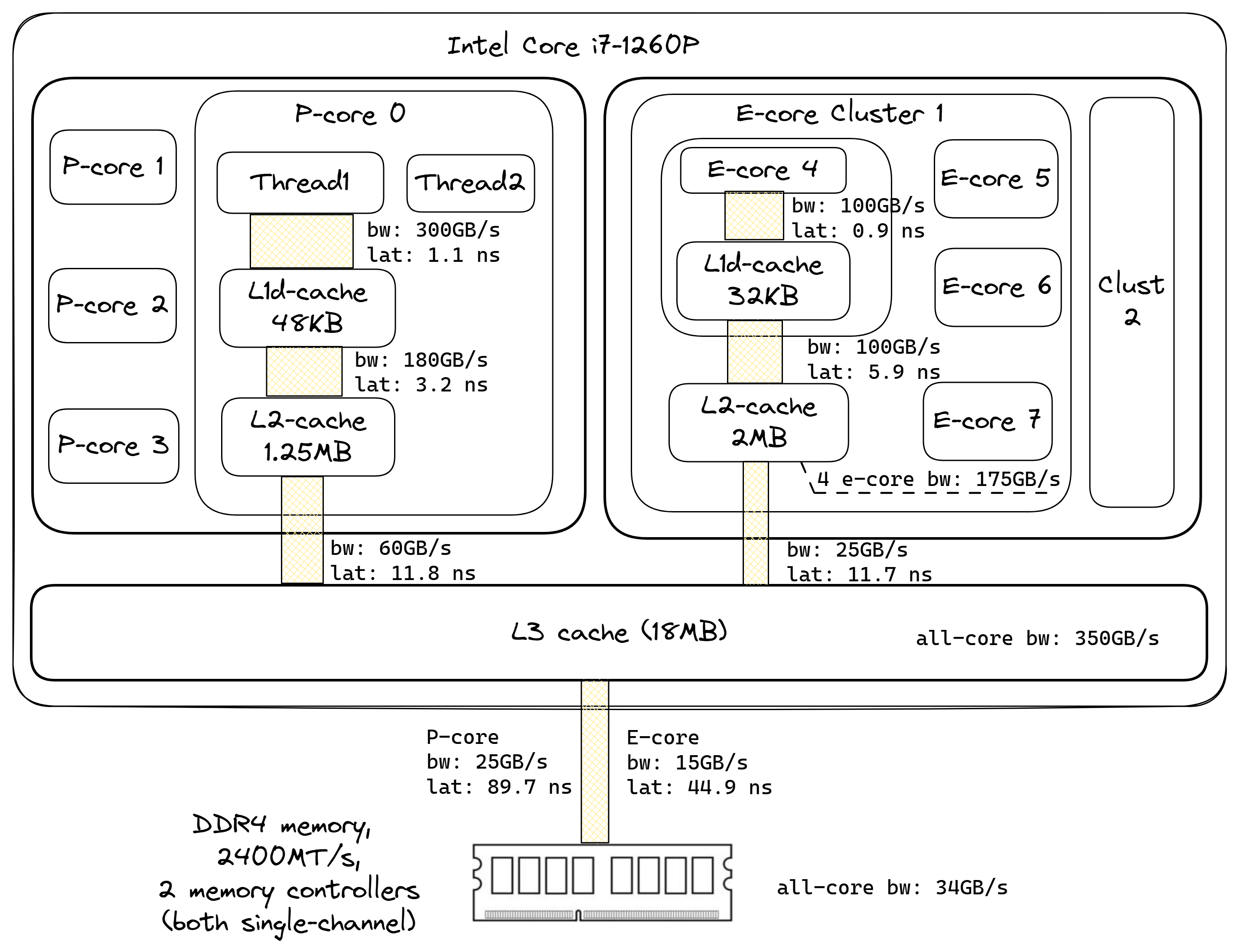
Intel Core i7-1260P 内存层次结构及外部 DDR4 内存的框图。
使用 Intel MLC 测量的我们测试系统的延迟和带宽综合数据如图 MemBandwidthAndLatenciesDiagram 所示。核心从较低层级缓存(如 L1 和 L2)获取数据的带宽远高于从共享 L3 缓存或主内存获取的带宽。L3 和 E 核 L2 等共享缓存能够相当好地扩展以同时满足多个核心的请求。例如,单个 E 核 L2 带宽为 100 GB/s。使用来自同一集群的两个 E 核,我测量到 140 GB/s,三个 E 核为 165 GB/s,全部四个 E 核可以从共享 L2 获取 175 GB/s。L3 缓存也类似,单个 P 核可达 60 GB/s,单个 E 核仅 25 GB/s。但当所有核心都被使用时,L3 缓存可以维持 300 GB/s 的带宽。从内存读取数据的速度可达 33.7 GB/s,而我的平台理论最大带宽为 38.4 GB/s。
了解机器的主要特性对于评估程序对可用资源的利用程度至关重要。我们将在 [roofline] 讨论 Roofline 性能模型时回到这个话题。如果你经常在单一平台上分析性能,最好记住内存层次结构各组件的延迟和带宽,或随时查阅。这有助于建立针对测试系统的心智模型(mental model),从而辅助你进行进一步的性能分析,正如你接下来将看到的那样。
1. Intel MLC 工具 - https://www.intel.com/content/www/us/en/download/736633/intel-memory-latency-checker-intel-mlc.html ↩
2. lmbench - https://sourceforge.net/projects/lmbench ↩
3. Stream - https://github.com/jeffhammond/STREAM ↩
4. Zack Smith 的内存带宽基准测试 - https://zsmith.co/bandwidth.php ↩