函数重排(Function Reordering)
遵循前几节描述的原则,热函数可以被分组在一起,以进一步提高 CPU 前端缓存的利用率。当热函数被分组后,它们开始共享缓存行,从而减少了代码占用(code footprint),即 CPU 需要获取的缓存行总数。
图 FunctionGrouping 给出了对热函数 foo、bar 和 zoo 进行重排的图形表示。图中箭头表示最频繁的调用模式,即 foo 调用 zoo,zoo 再调用 bar。在默认布局中(见图 FuncGroup_default),热函数彼此不相邻,中间穿插着一些冷函数。因此,两次函数调用的序列(foo → zoo → bar)需要读取四条缓存行。4
我们可以重新排列函数顺序,使热函数彼此靠近(见图 FuncGroup_better)。在改进版本中,foo、bar 和 zoo 函数的代码只占用三条缓存行。另外,注意函数 zoo 现在被放置在 foo 和 bar 之间,符合函数调用的顺序。当我们从 foo 调用 zoo 时,zoo 的起始部分已经在 I-cache 中了。
default layout
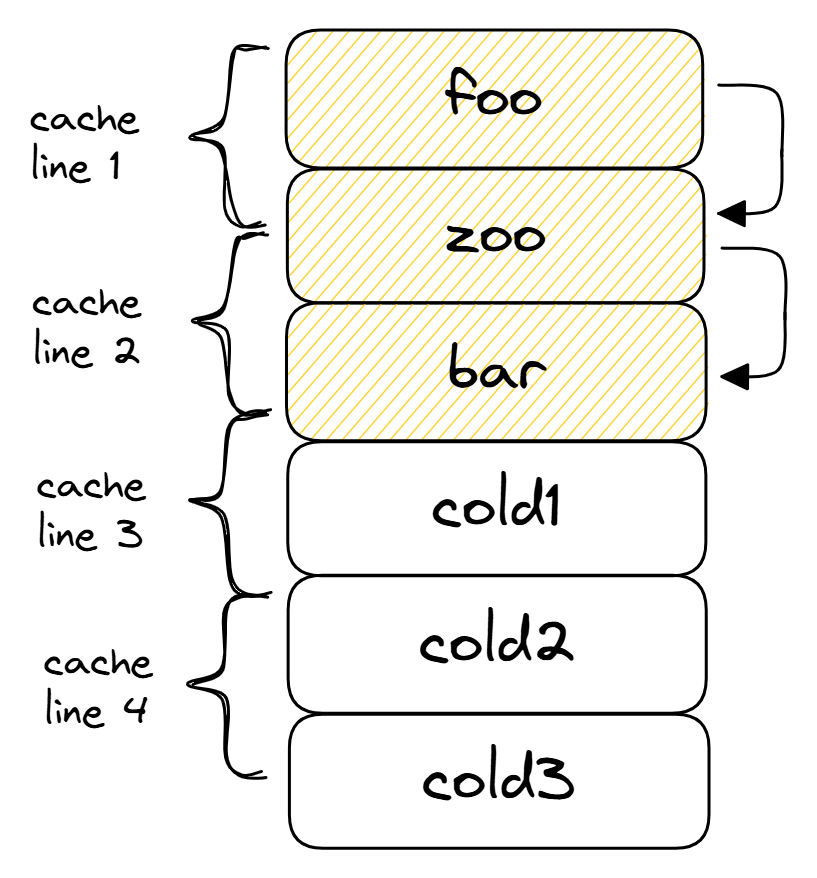improved layout
重排热函数。与前面的优化类似,函数重排改善了 I-cache 和 μop 缓存的利用率。此优化在有许多小型热函数时效果最佳。
链接器(linker)负责在最终二进制输出中排列程序的所有函数。虽然开发者可以尝试自行重新排列程序中的函数,但无法保证所需的物理布局。几十年来,人们一直使用链接器脚本(linker scripts)来实现这一目标。如果你使用的是 GNU 链接器,这仍然是可行的方法。Gold 链接器(ld.gold)对这个问题有更简便的处理方式。要使用 Gold 链接器在二进制文件中实现所需的函数排序,可以先使用 -ffunction-sections 标志编译代码,这会将每个函数放入单独的 section。然后使用 --section-ordering-file=order.txt 选项提供一个包含函数名排序列表的文件,该列表反映了所需的最终布局。LLD 链接器(LLVM 编译器基础设施的一部分)中也存在相同功能,可通过 --symbol-ordering-file 选项访问。
2017 年,Meta 的工程师提出了一种解决热函数分组问题的有趣方法。他们实现了一个名为 HFSort1 的工具,可以根据性能分析数据自动生成 section 排序文件 [HfSort]。使用该工具,他们观察到 Facebook、Baidu 和 Wikipedia 等大型分布式云应用程序的性能提升了 2\%。HFSort 已被集成到 Meta 的 HHVM、LLVM BOLT 和 LLD 链接器2中。此后,该算法先被 HFSort+ 取代,最近又被缓存导向排序(Cache-Directed Sort,CDSort3)所取代,对具有大代码占用的工作负载进行了更多改进。
1. HFSort - https://github.com/facebook/hhvm/tree/master/hphp/tools/hfsort ↩
2. LLD 中的 HFSort - https://github.com/llvm-project/lld/blob/master/ELF/CallGraphSort.cpp ↩
3. LLVM 中的 Cache-Directed Sort - https://github.com/llvm/llvm-project/blob/main/llvm/lib/Transforms/Utils/CodeLayout.cpp ↩
4. 此外,位于共享库中的函数不参与机器码的精细布局。 ↩