收集性能监控事件(Collecting Performance Monitoring Events)
性能监控计数器(Performance Monitoring Counters,PMCs)是底层性能分析的一个非常重要的工具。它们能够提供关于程序执行的独特信息。PMCs 通常以两种模式使用:"计数"(Counting)或"采样"(Sampling)。计数模式主要用于计算我们在 [PerfMetrics] 中讨论的各种性能指标。采样模式用于查找热点,我们很快将对此进行讨论。
计数背后的想法非常简单:我们希望在程序运行时统计某些性能监控事件的总数量。PMCs 在自顶向下微架构分析(Top-down Microarchitecture Analysis,TMA)方法中被大量使用,我们将在 [TMA] 中仔细研究该方法。图 Counting 说明了从程序开始到结束统计性能事件的过程。
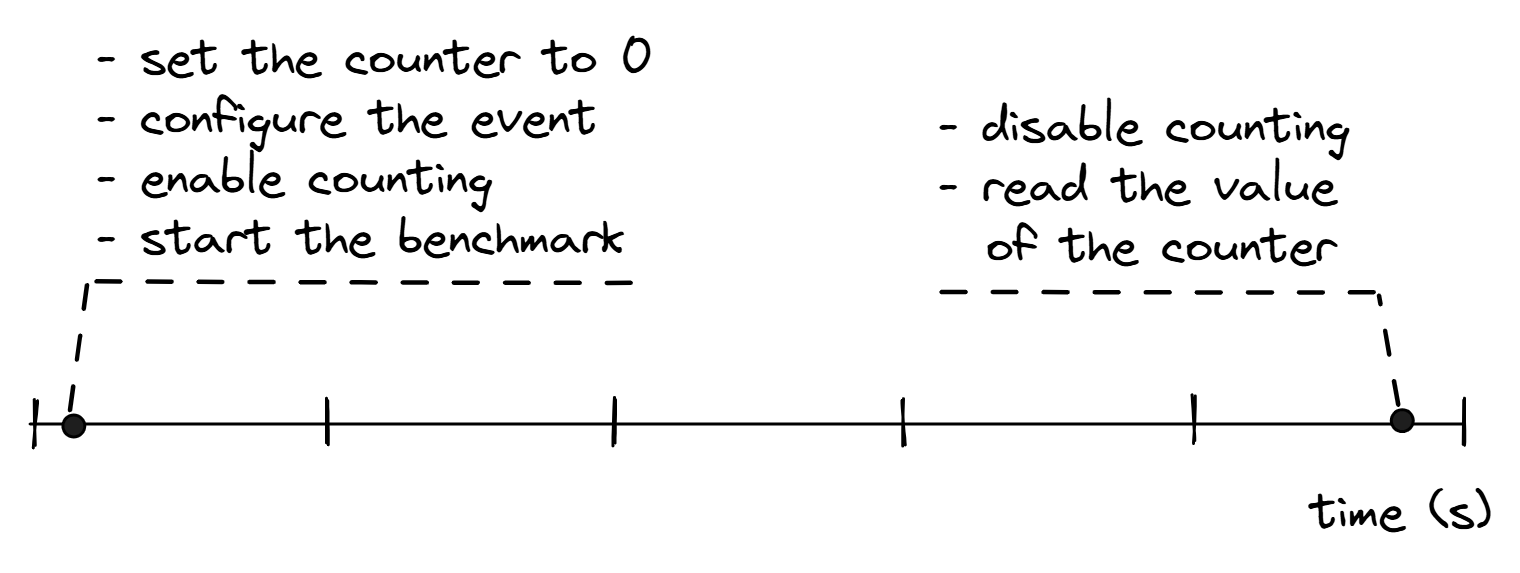
统计性能事件。
图 Counting 中概述的步骤大致代表了典型分析工具统计性能事件所执行的操作。perf stat 工具实现了类似的过程,可用于统计各种硬件事件,如指令数、周期数、缓存缺失次数等。以下是 perf stat 输出的示例:
{% math_inline %} perf stat -- ./my_program.exe
10580290629 cycles # 3,677 GHz
8067576938 instructions # 0,76 insn per cycle
3005772086 branches # 1044,472 M/sec
239298395 branch-misses # 7,96% of all branches
这些数据非常有用。首先,它使我们能够快速发现一些异常,例如高分支预测错误率(branch misprediction rate)或低 IPC(每周期指令数,instructions per cycle)。此外,当你进行了代码修改并希望验证该修改是否改善了性能时,它也会很有帮助。查看相关事件可能有助于你证明或否定代码修改的效果。perf stat 工具可以用作一个轻量级的基准测试包装器(benchmark wrapper),可作为性能调查的第一步。有时异常会立刻显现出来,这可以节省一些分析时间。
可用事件名称的完整列表可通过 perf list 查看:
{% endmath_inline %} perf list
cycles [Hardware event]
ref-cycles [Hardware event]
instructions [Hardware event]
branches [Hardware event]
branch-misses [Hardware event]
...
cache:
mem_load_retired.l1_hit
mem_load_retired.l1_miss
...
现代 CPU 有数百个可观测的性能事件。记住所有这些事件及其含义非常困难。了解何时使用特定事件则更难。因此,通常我不建议手动收集特定事件,除非你真的知道自己在做什么。相反,我建议使用 Intel VTune Profiler 等工具,它能自动收集所需事件以计算各种指标。
并非每种环境中都能访问性能事件,因为访问 PMCs 需要 root 权限,而在虚拟化环境(virtualized environment)中运行的应用程序通常没有这种权限。对于在公有云中执行的程序,如果虚拟机(VM)管理器没有将 PMU 编程接口(PMU programming interfaces)正确暴露给客户机,则直接在客户机容器中运行基于 PMU 的性能分析工具不会产生有用的输出。因此,基于 CPU 性能监控计数器的性能分析工具在虚拟化和云环境中效果不佳 [PMC_virtual],尽管情况正在改善。VMware® 是最早支持4虚拟性能监控计数器(virtual Performance Monitoring Counters,vPMC)的 VM 管理器之一。AWS EC2 云也为专用主机启用了5 PMCs。
多路复用与事件缩放(Multiplexing and Scaling Events)
有些情况下,我们希望同时统计许多不同的事件。然而,一个计数器一次只能统计一个事件。这就是为什么 PMU(性能监控单元,Performance Monitoring Unit)包含多个计数器(在 Intel 最新的 Golden Cove 微架构中,有 12 个可编程 PMC,每个硬件线程 6 个)的原因。即便如此,固定计数器和可编程计数器的数量也并不总是足够的。自顶向下微架构分析(TMA)方法需要在程序的单次执行中收集多达 100 个不同的性能事件。现代 CPU 没有那么多计数器,这就是多路复用(multiplexing)发挥作用的时候了。
如果你需要收集的事件数量超过可用 PMC 的数量,分析工具会使用时间多路复用(time multiplexing)让每个事件都有机会访问监控硬件。图 Multiplexing1 展示了只有 4 个计数器可用时,在 8 个性能事件之间进行多路复用的示例。
使用多路复用时,事件不是一直被测量,而是只在一部分时间内被测量。在运行结束时,性能分析工具需要根据总启用时间(total time enabled)对原始计数进行缩放:
以图 Multiplexing2 为例。假设在性能分析期间,我们能够在三个时间间隔内测量第 1 组的一个事件。每个测量间隔持续 100ms(time enabled)。程序运行时间为 500ms(time running)。该计数器的总事件数被测量为 10,000(raw count)。因此,最终计数需要如下缩放:
这提供了一个估计值,表示如果在整个运行期间都测量该事件,计数会是多少。非常重要的是要理解,这仍然是一个估计值,而不是实际计数。多路复用和缩放可以安全地用于在长时间间隔内执行相同代码的稳定(steady)工作负载。但是,如果程序在不同热点之间频繁跳转,即具有不同的执行阶段(phases),则会有盲点,这可能在缩放过程中引入误差。为了避免缩放,你可以将事件数量减少到不超过可用物理 PMC 的数量。但是,你将不得不多次运行基准测试以测量所有事件。
4. VMware PMCs - https://www.vladan.fr/what-are-vmware-virtual-cpu-performance-monitoring-counters-vpmcs/ ↩
5. Amazon EC2 PMCs - http://www.brendangregg.com/blog/2017-05-04/the-pmcs-of-ec2.html ↩