开发指令级并行性(Exploiting Instruction Level Parallelism,ILP)
程序中的大多数指令天然适合流水线化和并行执行,因为它们彼此独立。现代 CPU 实现了大量额外的硬件特性,以开发这种指令级并行性(ILP),即在单条指令流中挖掘并行性。这些硬件特性与先进的编译器技术协同工作,提供了显著的性能提升。
乱序(OOO)执行
图 Pipelining 中的流水线示例展示了所有指令按顺序经过流水线不同阶段的过程,即按照与程序相同的顺序(也称为程序顺序(program order))执行。大多数现代 CPU 支持乱序(OOO,Out-Of-Order)执行,其中顺序指令可以仅受数据依赖和资源可用性限制,以任意顺序进入执行阶段。支持 OOO 执行的 CPU 仍然必须给出与所有指令按程序顺序执行相同的结果。
一条指令在最终执行完毕且其结果在架构状态中正确可见后,称为退休(retired)。为保证正确性,CPU 必须按程序顺序退休所有指令。OOO 执行主要用于避免因依赖关系导致的停顿而造成 CPU 资源利用不足,在超标量引擎(我们将很快讨论)中尤为如此。
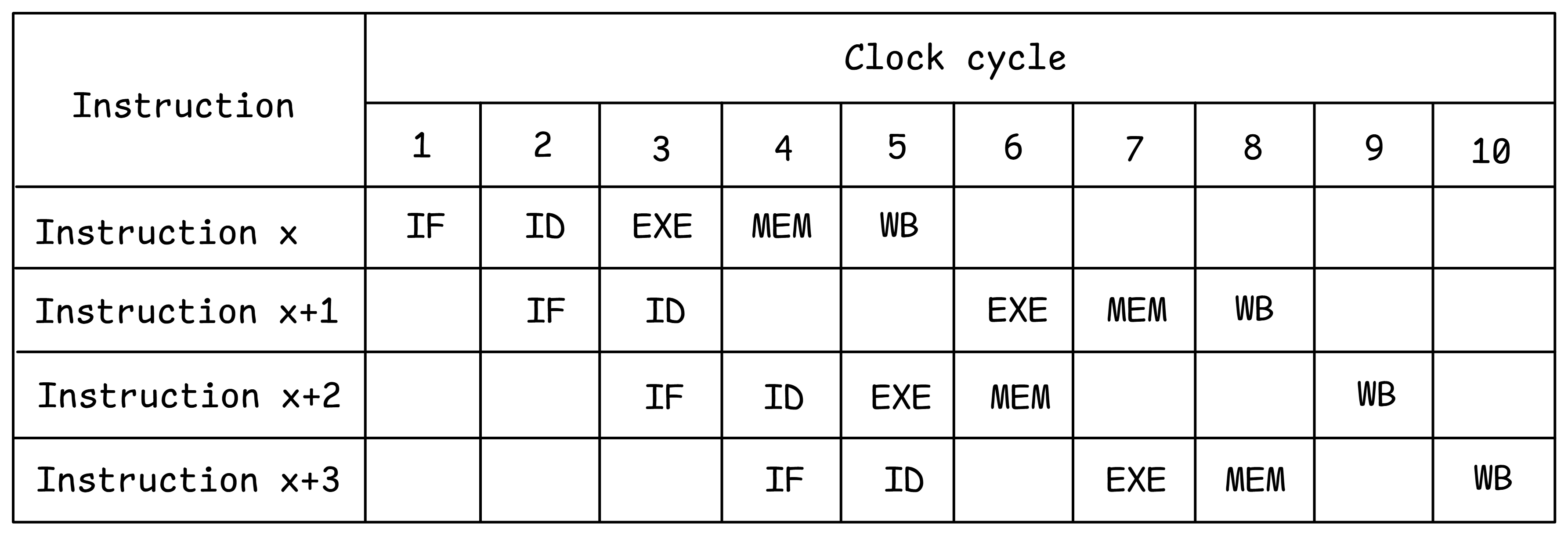
乱序执行的概念示意图。
图 OOO 说明了乱序执行的概念。假设指令 x+1 由于某些冲突在第 4 和第 5 个周期无法执行。顺序 CPU 会停止所有后续指令进入 EXE 流水线阶段,因此指令 x+2 只能在第 7 个周期才开始执行。在支持 OOO 执行的 CPU 中,只要没有冲突(例如输入已就绪,执行单元未被占用等),指令就可以开始执行。如图所示,指令 x+2 在指令 x+1 之前开始执行。指令 x+3 不能在第 6 个周期进入 EXE 阶段,因为该阶段已被指令 x+1 占用。所有指令仍然按顺序退休,即指令按程序顺序完成 WB 阶段。
OOO 执行通常相比顺序执行带来巨大的性能提升。然而,它也带来了额外的复杂性和功耗。
对指令进行重排序的过程通常称为指令调度(scheduling)。调度的目标是以最小化流水线冒险、最大化 CPU 资源利用率的方式发射指令。指令调度可以在编译时进行(静态调度),也可以在运行时进行(动态调度)。让我们分别解析这两种选项。
静态调度
Intel Itanium 是静态调度的一个例子。对于超标量多执行单元机器的静态调度,调度工作从硬件转移到编译器,使用一种称为 VLIW(超长指令字,Very Long Instruction Word)的技术。其理由是通过要求编译器选择合适的指令组合来保持机器充分利用,从而简化硬件。编译器可以使用软件流水线和循环展开等技术,比硬件结构所能合理支持的范围看得更远,以找到合适的 ILP。
Intel Itanium 最终未能取得成功,原因有几个。其一是与 x86 代码缺乏兼容性。其二是编译器很难以使 CPU 保持忙碌的方式调度指令,因为加载延迟是可变的。x86 ISA 的 64 位扩展(x86-64)在同一时间窗口由 AMD 引入,与 IA-32(x86 ISA 的 32 位版本)兼容,并最终成为其真正的继任者。最后一批 Intel Itanium 处理器于 2021 年出货。
动态调度
为了克服静态调度的问题,现代处理器使用动态调度。动态调度中最重要的两种算法是记分板4和 Tomasulo 算法。5
记分板(Scoreboarding)最初在 1960 年代的 CDC6600 处理器中实现。它的主要缺点是不仅保留了真正的依赖关系(RAW),还保留了虚假依赖关系(WAW 和 WAR),因此提供的 ILP 并不理想。虚假依赖关系是由架构寄存器数量少(现代 ISA 通常在 16 到 32 个之间)造成的。这就是为什么所有现代处理器都采用了 Tomasulo 算法进行动态调度。Tomasulo 算法由 Robert Tomasulo 在 1960 年代发明,并首次在 IBM360 Model 91 中实现。
为了消除虚假依赖关系,Tomasulo 算法利用了我们在上一节讨论的寄存器重命名技术。因此,与记分板相比,性能得到了很大的提升。然而,存在 RAW 依赖关系的指令序列(也称为依赖链(dependency chain))对于 OOO 执行仍然是个问题,因为寄存器重命名后 ILP 不会增加,因为所有 RAW 依赖关系都被保留了。依赖链通常出现在循环(循环携带依赖)中,其中当前循环迭代依赖于前一次迭代产生的结果。
动态调度实现中另外两个关键组件是重排序缓冲区(ROB,Reorder Buffer)和保留站(RS,Reservation Station)。ROB 是一个跟踪每条指令状态的循环缓冲区,现代处理器中通常有数百个条目。通常,ROB 的大小决定了硬件可以向前多远地查找独立调度的指令。指令按程序顺序插入 ROB,可以乱序执行,并按程序顺序退休。寄存器重命名在指令被放入 ROB 时完成。
指令从 ROB 进入 RS,RS 的条目数少得多。一旦指令在 RS 中,它们就等待其输入操作数变为可用。当输入可用时,指令可以被发射到适当的执行单元。因此,一旦操作数可用,指令就可以以任何顺序执行,不再受程序顺序的约束。现代处理器越来越宽(可以在一个周期内执行许多指令)和越来越深(更大的 ROB、RS 和其他缓冲区),这表明在生产应用程序中存在大量可以挖掘的 ILP。
超标量引擎(Superscalar Engines)
大多数现代 CPU 都是超标量的,即它们可以在任意给定周期内发射多条指令。发射宽度(Issue width)是在同一周期内可以发射的最大指令数(参见 [PipelineSlot])。2024 年主流 CPU 的典型发射宽度在 6 到 9 之间。为确保适当的平衡,此类超标量引擎还具有多个执行单元和/或流水线化的执行单元。CPU 还将超标量能力与深度流水线和乱序执行相结合,以从给定软件中提取最大的 ILP。
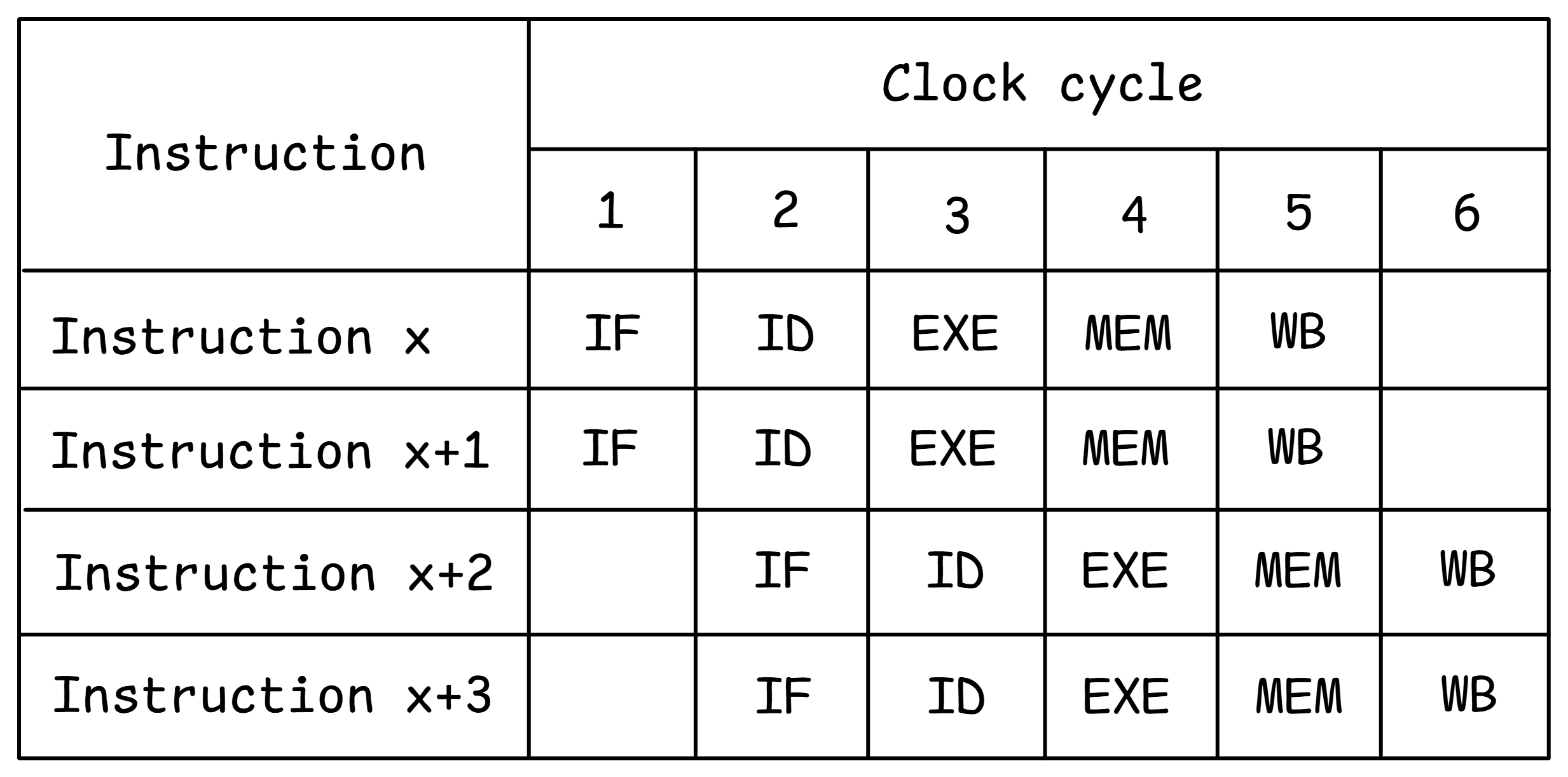
2 路超标量 CPU 中代码执行的流水线图。
图 SuperScalar 展示了支持 2 路发射的 CPU 流水线图。注意,每个周期每个流水线阶段都可以处理两条指令。例如,指令 x 和 x+1 都在第 3 个周期开始执行。这可以是两条相同类型的指令(例如两次加法)或两条不同类型的指令(例如一次加法和一次分支)。超标量处理器复制执行资源,以保持流水线中的指令流动不受结构冲突影响。例如,为了支持同时译码两条指令,我们需要有 2 个独立的译码器。
推测执行(Speculative Execution)
如上一节所述,如果指令在分支条件解析之前停顿,控制冒险可能导致流水线显著的性能损失。避免这种性能损失的一种技术是硬件分支预测(branch prediction)。利用该技术,CPU 预测分支的可能目标,并从预测路径开始执行指令(称为推测执行(speculative execution))。
让我们考虑清单 Speculative 中的例子。为了理解应该执行哪个函数,处理器需要知道条件 a < b 是假还是真。在不知道的情况下,CPU 会等待分支指令的结果确定,如图 NoSpeculation 所示。
清单:推测执行
if (a < b)
foo();
else
bar();
无推测执行
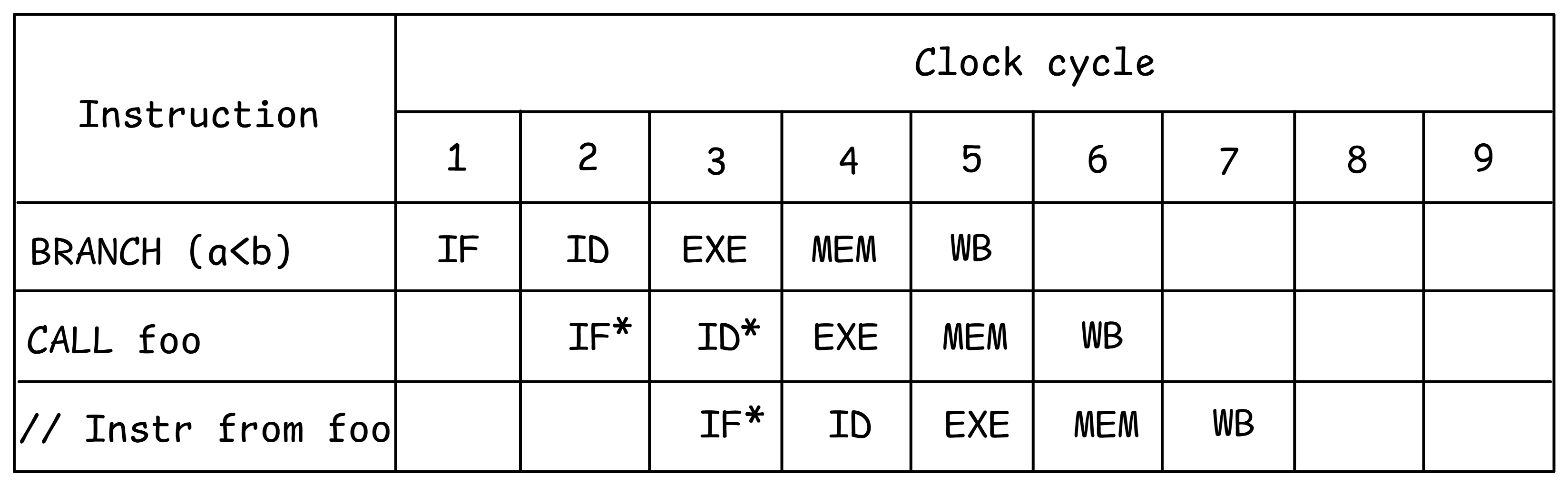推测执行。推测性工作标记为 。
推测执行的概念。有了推测执行,CPU 猜测分支的结果并开始处理所选路径上的指令。假设处理器预测条件 a < b 将被评估为真。它无需等待分支结果就继续执行,推测性地调用函数 foo(参见图 SpeculativeExec)。在条件解析之前,对机器状态的更改不能提交,以确保推测执行指令永远不会影响机器的架构状态。
在上面的例子中,分支指令比较两个标量值,速度很快。但在实际中,分支指令可能依赖于从内存加载的值,这可能需要数百个周期。
如果预测结果正确,可以节省大量周期。然而,有时预测是错误的,应该调用函数 bar。在这种情况下,推测执行的结果必须被丢弃。这被称为分支预测错误惩罚(branch misprediction penalty),我们将在 [BbMisp] 中讨论。
在 ROB 中,推测执行的指令被标记。一旦不再是推测性的,它就可以按程序顺序退休。这就是架构状态被提交、架构寄存器被更新的地方。由于推测指令的结果未被提交,当预测错误发生时,回滚变得很容易。
分支预测(Branch Prediction)
正如我们刚才所见,正确的预测能极大地提高执行效率,因为它允许 CPU 在没有前一条指令结果的情况下向前推进。然而,错误的推测往往会带来高昂的性能代价。现代 CPU 采用复杂的动态分支预测机制,提供非常高的准确率,并能适应分支行为的动态变化。分支有三种类型,可以以特殊方式处理:
- 无条件跳转和直接调用:它们最容易预测,因为它们总是被执行,且每次都走相同的方向。
- 条件分支:它们有两种可能的结果:跳转或不跳转。跳转分支可以向前或向后。向前条件分支通常由
if-else语句生成,不跳转的概率很高,因为它们经常表示错误检查代码。向后条件跳转在循环中经常出现,用于跳转到循环的下一次迭代;此类分支通常被执行。 - 间接调用和跳转:它们有许多目标。间接跳转或间接调用可以由
switch语句、函数指针或virtual函数调用生成。函数的返回也值得关注,因为它也有许多潜在目标。
大多数预测算法基于分支的历史结果。分支预测单元(BPU)的核心是分支目标缓冲区(BTB,Branch Target Buffer),它缓存每个分支的目标地址。预测算法每个周期查询 BTB 以生成下一个取指地址。CPU 使用该新地址来取下一个指令块。如果当前取指块中没有分支,则下一个取指地址将是下一个顺序对齐的取指块(fall through)。
无条件分支不需要预测;我们只需在 BTB 中查找目标地址即可。每个周期 BPU 都需要生成下一个取指地址以避免流水线停顿。我们本可以直接从指令编码中提取地址,但那样就必须等到译码阶段结束,这会在流水线中引入气泡(bubble),使事情变慢。因此,下一个取指地址必须在分支被取指时确定。
对于条件分支,我们首先需要预测分支是否会被执行。如果不被执行,则继续执行后续指令,无需查找目标。否则,我们在 BTB 中查找目标地址。条件分支通常占总分支数的最大比例,也是生产软件中预测错误惩罚的主要来源。对于间接分支,我们需要从可能的目标中选择一个,但预测算法可以与条件分支非常相似。
所有预测机制都尝试利用两个重要原理,这与我们稍后讨论缓存的内容类似:
- 时间相关性(Temporal correlation):分支的解析方式可能是其下次执行时解析方式的良好预测依据。这也称为局部相关性。
- 空间相关性(Spatial correlation):几个相邻的分支可能以高度相关的方式解析(优选执行路径)。这也称为全局相关性。
通过同时利用局部和全局相关性,通常可以获得最佳准确率。因此,我们不仅查看当前分支的历史结果,还将其与相邻分支的结果相关联。
另一种常用技术称为混合预测(hybrid prediction)。其思想是某些分支具有偏向性行为。例如,如果一个条件分支 99.9% 的时间都走同一个方向,就没必要使用复杂的预测器并占用其数据结构。可以使用简单得多的机制。另一个例子是循环分支。如果一个分支具有循环行为,则可以使用专用的循环预测器来预测它,该预测器会记住循环通常执行的迭代次数。
如今,最先进的预测技术以类 TAGE [Seznec2006] 预测器为主导。冠军级6分支预测器每 1000 条指令的预测错误不到 3 次。现代 CPU 在大多数工作负载上通常能达到 >95% 的预测率。
4. 记分板 - https://en.wikipedia.org/wiki/Scoreboarding。 ↩
5. Tomasulo 算法 - https://en.wikipedia.org/wiki/Tomasulo_algorithm。 ↩
6. 第 5 届冠军分支预测竞赛 - https://jilp.org/cbp2016。 ↩