分支记录机制
现代高性能 CPU 提供了分支记录机制(branch recording mechanism),使处理器能够持续记录一组最近执行的分支。但在深入细节之前,你可能会问:我们为何如此关注分支?因为这是我们确定程序控制流(control flow)的方式。我们基本上忽略基本块(basic block,见 [BasicBlock])中的其他指令,因为分支总是基本块中的最后一条指令。由于基本块中的所有指令都保证会被执行一次,我们只需关注"代表"整个基本块的分支即可。因此,如果我们追踪每个分支的结果,就可以重建程序逐行的执行路径。Intel 处理器追踪(Processor Traces,PT)特性具备这种能力,将在附录 C 中讨论。本节将讨论的分支记录机制基于采样而非追踪,因此具有不同的使用场景和能力。
Intel、AMD 和 Arm 设计的处理器都发布了各自的分支记录扩展。具体实现方式可能有所不同,但核心思想相同:硬件在程序执行的同时,记录每个分支的"来源"地址和"目标"地址以及一些附加数据。如果我们收集足够长的源-目标地址对历史记录,就能像调用栈(call stack)一样展开程序的控制流,只是深度有限。此类扩展的设计目标是对运行中的程序造成极小的减速(通常在 1% 以内)。
有了分支记录机制,我们可以对分支(或周期,无关紧要)进行采样,并在每次采样时查看最近执行的 N 个分支。这为热代码路径中的控制流提供了合理的覆盖,同时又不会因为检查太多分支信息而让我们不堪重负。重要的是要记住,这仍然是采样,因此并非每个执行的分支都能被检查——CPU 通常执行速度太快,无法做到这一点。
需要特别注意的是,只有被执行(taken)的分支才会被记录。代码清单 LogBranches 展示了分支结果被追踪的示例。该代码表示一个包含三条可能改变程序执行路径的指令的循环,分别是:循环回跳边 JNE(1)、条件分支 JNS(2)、函数 CALL(3),以及该函数的返回地址(4)。
代码清单:记录分支的示例。
----> 4eda10: mov edi,DWORD PTR [rbx]
| 4eda12: test edi,edi
| --- 4eda14: jns 4eda1e <== (2)
| | 4eda16: mov eax,edi
| | 4eda18: shl eax,0x7
| | 4eda1b: lea edi,[rax+rdi*8]
| └─> 4eda1e: call 4edb26 <== (3)
| 4eda23: add rbx,0x4 <== (4)
| 4eda27: mov DWORD PTR [rbx-0x4],eax
| 4eda2a: cmp rbx,rbp
----- 4eda2d: jne 4eda10 <== (1)
代码清单 BranchHistory 展示了在执行 CALL 指令时,分支记录机制可能记录的一种分支历史。它显示了最后 7 条分支结果(更多未显示)。由于在循环的最新一次迭代中,JNS 分支(4eda14 → 4eda1e)未被执行,因此它未被记录,不会出现在历史中。
代码清单:可能的分支历史。
Source Address Destination Address
... ...
(1) 4eda2d 4eda10 <== next iteration │
(2) 4eda14 4eda1e <== jns taken │
(3) 4eda1e 4edb26 <== call a function │
(4) 4b01cd 4eda23 <== return from a function │ time
(1) 4eda2d 4eda10 <== next iteration │
(3) 4eda1e 4edb26 <== latest branch V
未执行的分支不被记录这一特性可能会增加分析负担,但通常不会带来太大的复杂性。我们仍然可以推断完整的执行路径,因为我们知道从第 N-1 条记录的目标地址到第 N 条记录的源地址之间,控制流是顺序的。
接下来,我们将分别介绍各厂商的分支记录机制,然后探讨它们在性能分析中的应用方式。
Intel 平台上的 LBR
Intel 首先在 NetBurst 微架构中实现了其最后分支记录(Last Branch Record,LBR)功能。最初,它只能记录最近 4 条分支结果,后来从 Nehalem 开始扩展到 16 条,从 Skylake 开始扩展到 32 条。在 Golden Cove 微架构之前,LBR 以一组模型专用寄存器(model-specific registers,MSR)的形式实现,如今则在架构寄存器中工作。12
LBR 寄存器的行为类似于一个环形缓冲区(ring buffer),被持续覆写,只保存最近的 32 条分支结果。每条 LBR 记录由三个 64 位值组成:
- 分支的源地址(
From IP)。 - 分支的目标地址(
To IP)。 - 操作的元数据,包括预测错误信息和已经过的时钟周期信息。
除源地址和目标地址之外,附加信息也有重要的应用,我们将在后文讨论。
当采样计数器溢出并触发性能监控中断(Performance Monitoring Interrupt,PMI)时,LBR 日志会冻结,直到软件捕获 LBR 记录并恢复收集为止。
LBR 收集可以限定为特定的分支类型。例如,用户可以选择只记录函数调用和返回。对代码清单 LogBranches 中的代码应用这样的过滤器,历史中只会出现分支(3)和(4)。用户还可以过滤条件跳转、无条件跳转、间接跳转和调用、系统调用、中断等。在 Linux perf 中,-j 选项用于启用/禁用各种分支类型的记录。
默认情况下,LBR 数组作为环形缓冲区捕获控制流转换。然而,LBR 数组的深度是有限的,当剖析的应用程序中每次控制流转换都伴随着大量叶函数(leaf function)调用时,这可能成为限制因素。这些叶函数的调用及其返回,很可能会把主执行上下文从 LBR 中替换出去。再次考虑代码清单 LogBranches 中的示例。假设我们想从 LBR 历史中展开调用栈,因此配置 LBR 只捕获函数调用和返回。如果循环运行了数千次迭代,考虑到 LBR 数组只有 32 个条目,很可能我们只能看到 16 对条目(3)和(4)。在这种情况下,LBR 数组被叶函数调用塞满,对展开当前调用栈毫无帮助。
这就是为什么 LBR 支持调用栈模式(call-stack mode)。在此模式下,LBR 数组像以前一样捕获函数调用,但当执行返回指令时,最后捕获的分支(call)记录以后进先出(LIFO)的方式从数组中清除。因此,已完成的叶函数的分支记录不会被保留,而主执行路径的调用栈信息得以保存。以这种方式配置后,LBR 数组模拟一个调用栈,CALL 指令将条目压栈,RET 指令将条目出栈。如果应用程序的调用栈深度从未超过 32 层,LBR 将提供非常准确的信息。[IntelOptimizationManual]
可以使用以下命令确认系统上已启用 LBR:
{% math_inline %} dmesg | grep -i lbr
[ 0.228149] Performance Events: PEBS fmt3+, 32-deep LBR, Skylake events, full-width counters, Intel PMU driver.
使用 Linux perf,可以通过以下命令收集 LBR 栈:
{% endmath_inline %} perf record -b -e cycles -- ./benchmark.exe
[ perf record: Woken up 68 times to write data ]
[ perf record: Captured and wrote 17.205 MB perf.data (22089 samples) ]
也可以使用 perf record --call-graph lbr 命令收集 LBR 栈,但收集到的信息比使用 perf record -b 少。例如,使用 perf record --call-graph lbr 时不会收集分支预测错误和周期数据。
由于每个收集的样本都捕获整个 LBR 栈(32 条最近分支记录),收集数据(perf.data)的大小比不使用 LBR 的采样大得多。尽管如此,大多数 LBR 使用场景的运行时开销仍低于 1%。[Nowak2014TheOO]
用户可以导出原始 LBR 栈进行自定义分析。以下是可用于转储收集的分支栈内容的 Linux perf 命令:
{% math_inline %} perf record -b -e cycles -- ./benchmark.exe
{% endmath_inline %} perf script -F brstack &> dump.txt
dump.txt 文件可能相当大,包含如下所示的行:
...
0x4edaf9/0x4edab0/P/-/-/29
0x4edabd/0x4edad0/P/-/-/2
0x4edadd/0x4edb00/M/-/-/4
0x4edb24/0x4edab0/P/-/-/24
0x4edabd/0x4edad0/P/-/-/2
0x4edadd/0x4edb00/M/-/-/1
0x4edb24/0x4edab0/P/-/-/3
0x4edabd/0x4edad0/P/-/-/1
...
上述输出中,我们展示了 LBR 栈中的 8 条记录(通常由 32 条 LBR 记录组成)。每条记录包含 FROM 和 TO 地址(十六进制值)、一个预测标志(该单条分支结果:M 表示预测错误(Mispredicted),P 表示预测正确(Predicted)),以及自上一条记录以来的周期数(每条记录最后位置的数字)。标有"-"的部分与事务内存扩展(TSX)相关,本书不作讨论。感兴趣的读者可以在 perf script 规范2 中查阅解码 LBR 条目的格式。
AMD 平台上的 LBR
AMD 处理器从 AMD Zen4 开始也支持最后分支记录(Last Branch Record,LBR)。Zen4 可以记录 16 对"来源"和"目标"地址以及一些额外的元数据。与 Intel LBR 类似,AMD 处理器可以记录各种类型的分支。与 Intel LBR 的主要区别在于,AMD 处理器尚不支持调用栈模式,因此 LBR 功能无法用于调用栈收集。另一个显著区别是,AMD LBR 记录中没有周期计数字段。更多详情请参见 [AMDProgrammingManual]。
自 Linux 内核 6.1 起,Linux perf 在 AMD Zen4 处理器上支持我们下面讨论的分支分析使用场景,除非另有说明。Linux perf 命令使用与 Intel 处理器相同的 -b 和 -j 选项。
也可以使用 AMD uProf CLI 工具进行分支分析。以下示例命令转储收集的原始 LBR 记录并生成 CSV 报告:
{% math_inline %} AMDuProfCLI collect --branch-filter -o /tmp/ ./AMDTClassicMatMul-bin
Arm 平台上的 BRBE
Arm 于 2020 年作为 ARMv9.2-A ISA 的一部分,引入了其分支记录扩展,称为 BRBE(Branch Record Buffer Extension,分支记录缓冲扩展)。Arm BRBE 与 Intel 的 LBR 非常相似,提供了许多类似的功能。与 Intel LBR 一样,BRBE 记录包含源地址和目标地址、预测错误位(misprediction bit)和周期计数值。根据最新可用的 BRBE 规范,调用栈模式不受支持。分支记录仅包含架构上被执行(即不在错误预测路径上)的分支信息。用户也可以基于特定分支类型过滤记录。一个值得注意的区别是,BRBE 支持可配置的缓冲区深度:处理器可以选择 8、16、32 或 64 条记录的 BRBE 缓冲容量。更多详情请参见 [Armv9ManualSupplement]。
截至本文撰写时,尚无实现 ARMv9.2-A 的商用机器,因此无法实际测试 BRBE 扩展。
借助分支记录,多种使用场景成为可能。接下来,我们将介绍最重要的几种。
捕获调用栈
分支记录最流行的使用场景之一是捕获调用栈(call stack)。我已在 [secCollectCallStacks] 中介绍了收集调用栈的必要性。即使在没有帧指针(frame pointer)或调试信息的情况下编译程序,分支记录也可以作为收集调用图(call graph)信息的轻量级替代方案。
截至本文撰写时(2023 年末),AMD 的 LBR 和 Arm 的 BRBE 不支持调用栈收集,但 Intel 的 LBR 支持。以下是使用 Intel LBR 的方式:
{% endmath_inline %} perf record --call-graph lbr -- ./a.exe
{% math_inline %} perf report -n --stdio
# Children Self Samples Command Object Symbol
# ........ ....... ....... ....... ...... .......
99.96% 99.94% 65447 a.exe a.exe [.] bar
|
--99.94%--main
|
|--90.86%--foo
| |
| --90.86%--bar
|
--9.08%--zoo
bar
可以看到,我们识别出程序中最热的函数(即 bar)。同时,我们还识别出贡献到函数 bar 中最多时间的调用者:工具 91% 的时间捕获了 main → foo → bar 调用栈,9% 的时间捕获了 main → zoo → bar。换句话说,bar 中 91% 的样本的直接调用者是 foo。
需要特别指出的是,在这种情况下我们不能必然推断出函数调用次数。例如,我们不能说 foo 调用 bar 的频率是 zoo 的 10 倍。实际上可能是 foo 只调用了 bar 一次,但在 bar 内部执行了一条耗时路径,而 zoo 调用了 bar 多次但每次都很快返回。
识别热分支
分支记录还使我们能够识别最频繁执行的分支。Intel 和 AMD 均支持此功能。根据 Arm 的 BRBE 规范,它理论上可以支持,但由于实现该扩展的处理器尚不可用,无法验证。以下是一个示例:
{% endmath_inline %} perf record -e cycles -b -- ./a.exe
[ perf record: Woken up 3 times to write data ]
[ perf record: Captured and wrote 0.535 MB perf.data (670 samples) ]
{% math_inline %} perf report -n --sort overhead,srcline_from,srcline_to -F +dso,symbol_from,symbol_to --stdio
# Samples: 21K of event 'cycles'
# Event count (approx.): 21440
# Overhead Samples Object Source Sym Target Sym From Line To Line
# ........ ....... ...... .......... .......... ......... .......
51.65% 11074 a.exe [.] bar [.] bar a.c:4 a.c:5
22.30% 4782 a.exe [.] foo [.] bar a.c:10 (null)
21.89% 4693 a.exe [.] foo [.] zoo a.c:11 (null)
4.03% 863 a.exe [.] main [.] foo a.c:21 (null)
从这个示例可以看出,超过 50% 的已执行分支发生在 bar 函数内部,22% 的分支是从 foo 到 bar 的函数调用,依此类推。注意 perf 如何从 cycles 事件切换到分析 LBR 栈:只收集了 670 个样本,但每个样本捕获了完整的 32 条记录的 LBR 栈。这为我们提供了 670 * 32 = 21440 条 LBR 记录(分支结果)用于分析。5
大多数情况下,仅凭代码行和目标符号就能确定分支的位置。然而,理论上你可能会在一行代码中写两条 if 语句。此外,在展开宏定义时,所有展开的代码都被归因于同一源代码行,这是可能发生这种情况的另一种场景。这个问题不会完全阻碍分析,只是会使分析稍微困难一些。要消除两个分支的歧义,可能需要自行分析原始 LBR 栈(参见 easyperf6 博客上的示例)。
借助分支记录,我们还可以找到超级块(hyperblock,有时称为超块(superblock)),即函数中一系列热基本块的链,这些基本块不一定按顺序物理排列,但被顺序执行。因此,超级块代表了函数内部的典型热路径。
分析分支预测错误率
由于每条记录中保存的附加信息里包含预测错误位,我们也可以了解热分支的预测错误率。在这个示例中,我们使用 LLVM 测试套件中 7-zip 基准测试的纯 C 代码版本。7 perf report 命令的输出已稍作裁剪以适应页面。Intel 和 AMD 均支持以下使用场景。根据 Arm 的 BRBE 规范,它理论上可以支持,但由于实现该扩展的处理器尚不可用,无法验证。
{% endmath_inline %} perf record -e cycles -b -- ./7zip.exe b
{% math_inline %} perf report -n --sort symbol_from,symbol_to -F +mispredict,srcline_from,srcline_to --stdio
# Samples: 657K of event 'cycles'
# Event count (approx.): 657888
# Overhead Samples Mis From Line To Line Source Sym Target Sym
# ........ ....... ... ......... ....... .......... ..........
46.12% 303391 N dec.c:36 dec.c:40 LzmaDec LzmaDec
22.33% 146900 N enc.c:25 enc.c:26 LzmaFind LzmaFind
6.70% 44074 N lz.c:13 lz.c:27 LzmaEnc LzmaEnc
6.33% 41665 Y dec.c:36 dec.c:40 LzmaDec LzmaDec
在这个示例中,与函数 LzmaDec 对应的行尤其值得关注。在 Linux perf 提供的输出中,可以看到两条对应 LzmaDec 函数的记录:一条带有 Y,一条带有 N。我们可以得出结论,源代码行 dec.c:36 上的分支是基准测试中执行最频繁的分支,因为超过 50% 的样本归属于它。综合分析这两条记录,可以得到该分支的预测错误率。我们知道,dec.c:36 上的分支被正确预测了 303391 次(对应 N),被错误预测了 41665 次(对应 Y),由此得到 88% 的预测率。
Linux perf 通过分析每条 LBR 记录并提取其中的预测错误位来计算预测错误率。因此,对于每个分支,我们都有它被正确预测的次数和被错误预测的次数。同样,由于采样的本质,某些分支可能有 N 条记录但没有对应的 Y 条记录。这意味着没有 LBR 记录显示该分支被错误预测,但这并不一定意味着预测率是 100%。
机器码的精确计时
如我们在 Intel LBR 一节中所示,从 Skylake 微架构开始,LBR 记录中增加了一个特殊的周期计数(Cycle Count)字段。这个附加字段指定了两次已执行分支之间经过的周期数。由于前一条(N-1)LBR 记录的目标地址是一个基本块(BB)的起始,当前(N)LBR 记录的源地址是同一基本块的最后一条指令,因此周期计数就是该基本块的延迟(latency)。
AMD 平台不支持这种分析,因为 AMD LBR 记录中不包含周期计数。根据 Arm 的 BRBE 规范,它理论上可以支持,但由于实现该扩展的处理器尚不可用,无法验证。Intel 支持此功能,以下是一个示例:
400618: movb {% endmath_inline %}0x0, (%rbp,%rdx,1) <= start of the BB
40061d: add {% math_inline %}0x1, %rdx
400621: cmp {% endmath_inline %}0xc800000, %rdx
400628: jnz 0x400644 <= end of the BB
假设 LBR 栈中有以下记录:
FROM_IP TO_IP Cycle Count
... ... ... <== 26 entries
40060a 400618 10
400628 400644 80 <== occurrence 1
40064e 400600 3
40060a 400618 9
400628 400644 300 <== occurrence 2
40064e 400600 3 <== LBR TOS
根据这些信息,我们有两次从偏移 400618 处开始的基本块执行记录。第一次在 80 个周期内完成,而第二次耗时 300 个周期。如果我们收集足够多的这类样本,就可以绘制出该基本块延迟的出现率图表。
图 LBR_timing_BB 展示了这样一张图表,它是通过分析相关 LBR 条目编制的。读图方法如下:它表示某个延迟值的出现率。例如,该基本块延迟约 2% 的时间被测量为 100 个周期,14% 的时间被测量为 280 个周期,且从未观察到 150 到 200 个周期之间的值。另一种读法是:基于收集的数据,如果你测量某个基本块的延迟,观察到特定延迟值的概率是多少?
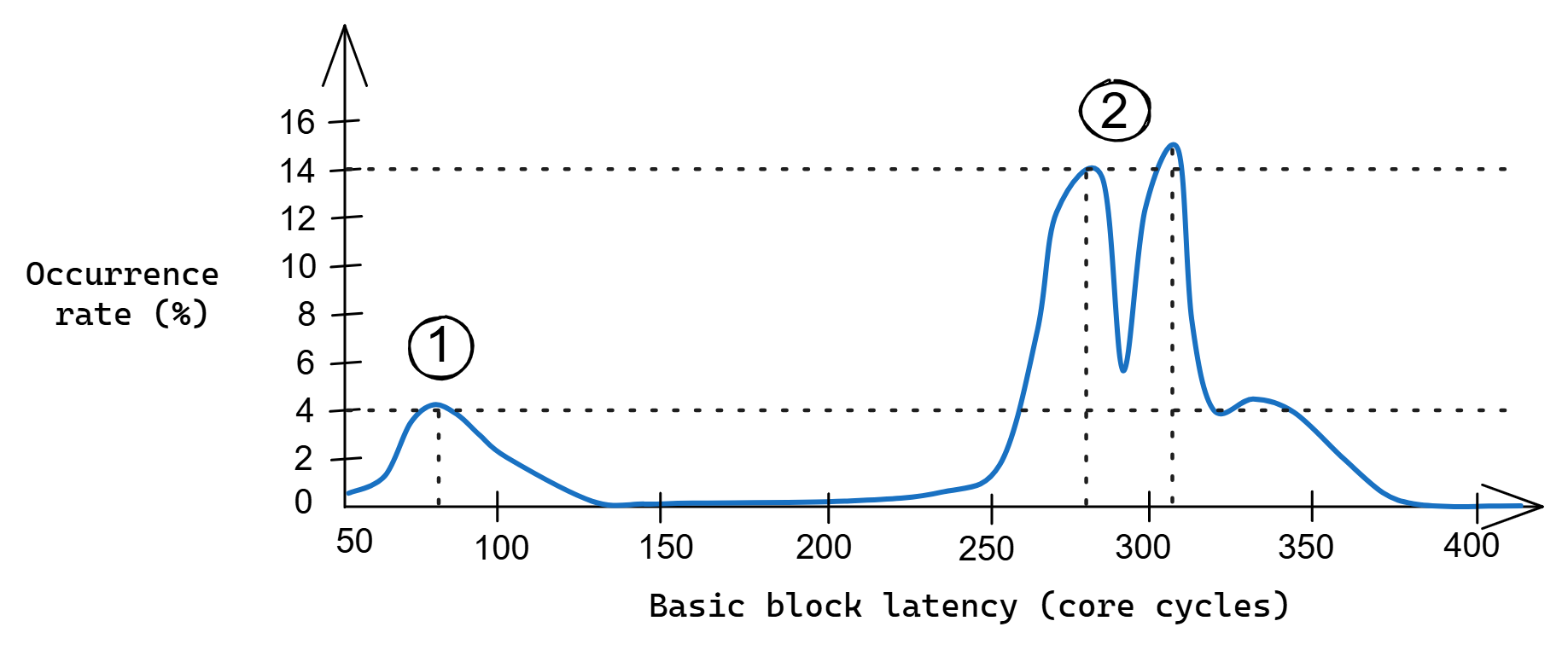
地址 `0x400618` 处基本块延迟的出现率图表。
可以看到两个峰值:一个小峰 ① 在约 80 个周期处,两个较大的峰 ② 在 280 和 305 个周期处。该基本块从一个大型数组进行随机加载,该数组无法放入 CPU L3 缓存,因此基本块的延迟在很大程度上取决于这次加载。根据图表,我们可以得出结论:第一个峰值 ① 对应 L3 缓存命中,第二个峰值 ② 对应 L3 缓存缺失(加载请求一路访问到主内存)的情况。
这些信息可用于对该基本块进行精细调优。此示例可能受益于内存预取(memory prefetching),我们将在 [memPrefetch] 中讨论。另外,周期计数信息还可以用于对循环迭代计时,其中每次循环迭代都以一个已执行的分支(回跳边)结束。
在剖析工具提供适当支持之前,构建类似图 LBR_timing_BB 的图表需要手动解析原始 LBR 转储。关于如何操作的示例可以在 easyperf 博客9 上找到。幸运的是,在较新版本的 Linux perf 中,获取这些信息变得容易得多。以下示例直接使用 Linux perf 在我们之前介绍的 LLVM 测试套件中的同一 7-zip 基准测试上演示这一方法:
{% math_inline %} perf record -e cycles -b -- ./7zip.exe b
{% endmath_inline %} perf report -n --sort symbol_from,symbol_to -F +cycles,srcline_from,srcline_to --stdio
# Samples: 658K of event 'cycles'
# Event count (approx.): 658240
# Overhead Samples BBCycles FromSrcLine ToSrcLine
# ........ ....... ........ ........... ..........
2.82% 18581 1 dec.c:325 dec.c:326
2.54% 16728 2 dec.c:174 dec.c:174
2.40% 15815 4 dec.c:174 dec.c:174
2.28% 15032 2 find.c:375 find.c:376
1.59% 10484 1 dec.c:174 dec.c:174
1.44% 9474 1 enc.c:1310 enc.c:1315
1.43% 9392 10 7zCrc.c:15 7zCrc.c:17
0.85% 5567 32 dec.c:174 dec.c:174
0.78% 5126 1 enc.c:820 find.c:540
0.77% 5066 1 enc.c:1335 enc.c:1325
0.76% 5014 6 dec.c:299 dec.c:299
0.72% 4770 6 dec.c:174 dec.c:174
0.71% 4681 2 dec.c:396 dec.c:395
0.69% 4563 3 dec.c:174 dec.c:174
0.58% 3804 24 dec.c:174 dec.c:174
注意我们添加了 -F +cycles 选项以在输出中显示周期数(BBCycles 列)。perf report 输出中若干无关行已被删除以使其适应页面。让我们关注源地址和目标地址均为 dec.c:174 的行,输出中共有七行此类记录。在源代码中,dec.c:174 行展开了一个包含独立分支的宏。这就是为什么源地址和目标地址指向同一行。
Linux perf 首先按开销排序,因此我们需要手动筛选我们感兴趣的分支的条目。幸运的是,它们很容易用 grep 过滤。实际上,如果我们将它们过滤出来,就会得到以该分支结尾的基本块的延迟分布,如表 bb_latency 所示。这些数据可以绘制成类似图 LBR_timing_BB 所示的图表。
| Cycles | Number of samples | Occurrence rate |
|---|---|---|
| 1 | 10484 | 17.0% |
| 2 | 16728 | 27.1% |
| 3 | 4563 | 7.4% |
| 4 | 15815 | 25.6% |
| 6 | 4770 | 7.7% |
| 24 | 3804 | 6.2% |
| 32 | 5567 | 9.0% |
表:基本块延迟出现率。
以下是对该数据的解读:在所有收集的样本中,17% 的时间基本块延迟为 1 个周期,27% 的时间为 2 个周期,依此类推。注意分布主要集中在 1 到 6 个周期,但也存在第二个众数,延迟高达 24 和 32 个周期,这很可能对应分支预测错误的惩罚(misprediction penalty)。该第二众数占所有样本的 15%。
此示例表明,不仅对小型微基准测试,对真实世界的应用程序也可以绘制基本块延迟图。目前,LBR 是 Intel 系统上最精确的周期级计时信息来源。
估算分支结果概率
在后文 [secFEOpt] 中,我们将讨论代码布局对性能的重要性。先略微预告一下,让热路径走顺序执行路径(fall through)11 通常可以提升程序性能。了解某个分支的最频繁结果,使开发者和编译器能够做出更好的优化决策。例如,如果一个分支 99% 的时间都被执行(taken),我们可以尝试反转条件,将其转换为不被执行(not-taken)的分支。
LBR 使我们无需对代码进行插桩(instrument)就能收集这些数据。分析结果是条件的真/假结果之间的比率,即分支被执行和未被执行的次数比。这一特性在分析间接跳转(switch 语句)和间接调用(虚函数调用)时尤为出色。你可以在 easyperf 博客6 上找到在真实应用程序上使用它的示例。
为编译器提供反馈数据
我们将在 [secPGO] 中讨论基于剖析的优化(Profile Guided Optimizations,PGO),这里只做简短提及。分支记录机制可以为优化编译器提供剖析反馈数据。试想,我们可以将前面几节中发现的所有数据反馈给编译器。在某些情况下,这些数据无法通过传统的静态代码插桩获得,因此分支记录机制不仅因开销更低而成为更优选择,还因为它能提供更丰富的剖析数据。依赖硬件 PMU 收集数据的 PGO 工作流正变得越来越流行,一旦 AMD 和 Arm 的支持成熟,很可能会迅速普及。
2. Linux perf script 手册页 - http://man7.org/linux/man-pages/man1/perf-script.1.html. ↩
5. perf 生成的报告头信息可能仍然令人困惑,因为它显示的是21K of event cycles。但这里有21K条 LBR 记录,而非cycles。 ↩
6. Easyperf:估算分支概率 - https://easyperf.net/blog/2019/05/06/Estimating-branch-probability ↩
7. LLVM test-suite 7zip 基准测试 - https://github.com/llvm-mirror/test-suite/tree/master/MultiSource/Benchmarks/7zip ↩
9. Easyperf:为任意基本块延迟构建概率密度图表 - https://easyperf.net/blog/2019/04/03/Precise-timing-of-machine-code-with-Linux-perf. ↩
11. 即热分支未被执行(not taken)时。 ↩
12. 其主要优势在于 LBR 特性被明确定义,无需检查当前 CPU 的具体型号。这大大简化了操作系统和剖析工具中的支持工作。此外,LBR 条目可以被配置为包含在 PEBS 记录中(见 [secPEBS])。 ↩