高级分析工具
许多工具已被开发出来以解决传统分析器无法提供足够可见性的特定用例。在本节中,我们将介绍 Coz 和 eBPF 工具。我们鼓励你对这些和其他工具进行进一步研究。
Coz
在 [secAmdahl] 中,我们定义了识别影响多线程程序整体性能的代码部分所面临的挑战。由于各种原因,优化多线程程序的某一部分可能不会总是产生可见的结果。传统的基于采样的分析器只显示大部分时间花费的代码位置。然而,这不一定对应于程序员应该集中优化工作的地方。
Coz16 是一个解决这一问题的分析器。它使用一种称为因果分析(causal profiling)的新技术,通过在应用程序运行时进行实验,通过虚拟加速代码段来预测某些优化的整体效果。它通过插入暂停来减慢所有其他并发运行的代码来实现这些"虚拟加速"。此外,Coz 量化了优化的潜在影响。[CozPaper]
将 Coz 分析器应用于 C-Ray15 基准测试的示例如图 CozProfile 所示。根据图表,如果我们将 c-ray-mt.c 第 540 行的性能提升 20%,Coz 预计 C-Ray 基准测试的整体应用程序性能相应增加约 17%。一旦我们在该行上达到约 45% 的提升,Coz 估计对应用程序的影响开始趋于平稳。有关此示例的更多详细信息,请参阅 Easyperf 博客上的文章。17
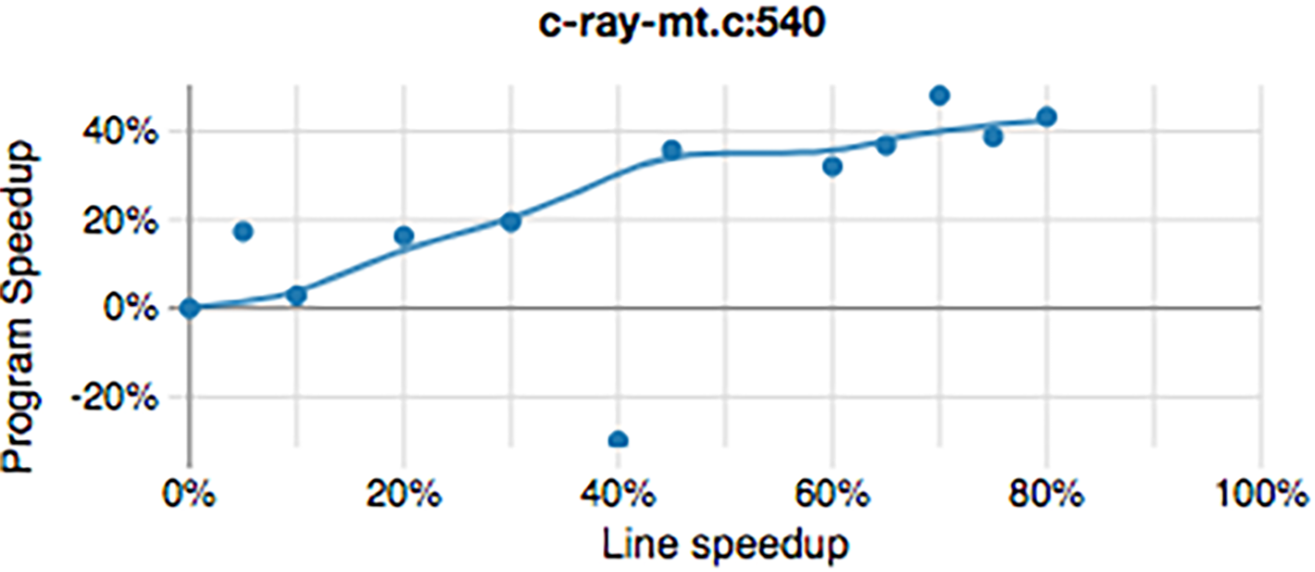
C-Ray 基准测试的 Coz 性能剖析。
15. C-Ray benchmark - https://github.com/jtsiomb/c-ray. ↩
16. COZ source code - https://github.com/plasma-umass/coz. ↩
17. Blog article "COZ vs Sampling Profilers" - https://easyperf.net/blog/2020/02/26/coz-vs-sampling-profilers. ↩
eBPF 和 GAPP
Linux 支持多种线程同步原语:互斥锁(mutexes)、信号量(semaphores)、条件变量(condition variables)等。内核通过 futex 系统调用支持这些线程原语。因此,通过在内核中跟踪 futex 系统调用的执行,同时从相关线程收集有用的元数据,可以更容易地识别竞争瓶颈。Linux 提供了使这成为可能的内核追踪和分析工具,其中最强大的是扩展伯克利数据包过滤器(Extended Berkeley Packet Filter,eBPF)。22
eBPF 基于在内核中运行的沙箱虚拟机,允许在内核内安全高效地执行用户定义的程序。用户定义的程序可以用 C 编写,并由 BCC 编译器23编译成 BPF 字节码,为加载到内核虚拟机做准备。这些 BPF 程序可以被编写为在某些内核事件执行时启动,并通过各种方式将原始或处理过的数据传回用户空间。
开源社区为一般用途提供了许多 eBPF 程序。其中一个工具是通用自动并行分析器(Generic Automatic Parallel Profiler,GAPP),25它有助于跟踪多线程竞争问题。GAPP 使用 eBPF 通过对已识别的序列化瓶颈的关键性进行排名来跟踪多线程应用程序的竞争开销,并收集被阻塞线程和导致阻塞的线程的栈追踪。GAPP 最好的一点是它不需要代码更改、昂贵的仪器化或重新编译。GAPP 分析器的创建者能够在 Parsec 3.0 基准测试套件24和一些大型开源项目中确认已知瓶颈并暴露新的、以前未报告的瓶颈。[GAPP]
作为结语,我想重新强调优化多线程应用程序的重要性。从我们在本书中讨论的所有内容来看,本章的建议可能带来最显著的性能改进。在多线程应用程序中,细节决定成败。细微的同步问题或数据共享中的小低效可能导致显著的性能下降。展望未来,向多核处理器和并行工作负载的趋势只会加速。多线程优化的复杂性将会增长,但对于掌握它的人来说,机会也会随之增长。
22. eBPF docs - https://prototype-kernel.readthedocs.io/en/latest/bpf/ ↩
23. BCC compiler - https://github.com/iovisor/bcc ↩
24. Parsec 3.0 Benchmark Suite - https://parsec.cs.princeton.edu/index.htm ↩
25. GAPP - https://github.com/RN-dev-repo/GAPP/ ↩