Intel 平台上的 TMA
TMA 方法论由 Intel 于 2014 年首次提出,从 Sandy Bridge 系列处理器开始得到支持。Intel 的实现为每个高层分类提供了嵌套子类,使开发者能够更深入地理解程序中 CPU 性能瓶颈(见图 TMA)。
该工作流程被设计为"逐层深入"TMA 层次结构,直到获得对性能瓶颈非常具体的分类。首先,我们收集四个主要分类的指标:前端受限(Frontend Bound)、后端受限(Backend Bound)、退休(Retiring)和错误推测(Bad Speculation)。假设我们发现程序执行的很大一部分时间被内存访问所阻塞(即后端受限分类,见图 TMA),下一步是再次运行工作负载,仅收集内存受限(Memory Bound)分类的专项指标。这一过程持续重复,直到我们确定具体的根因,例如L3 受限(L3 Bound)。
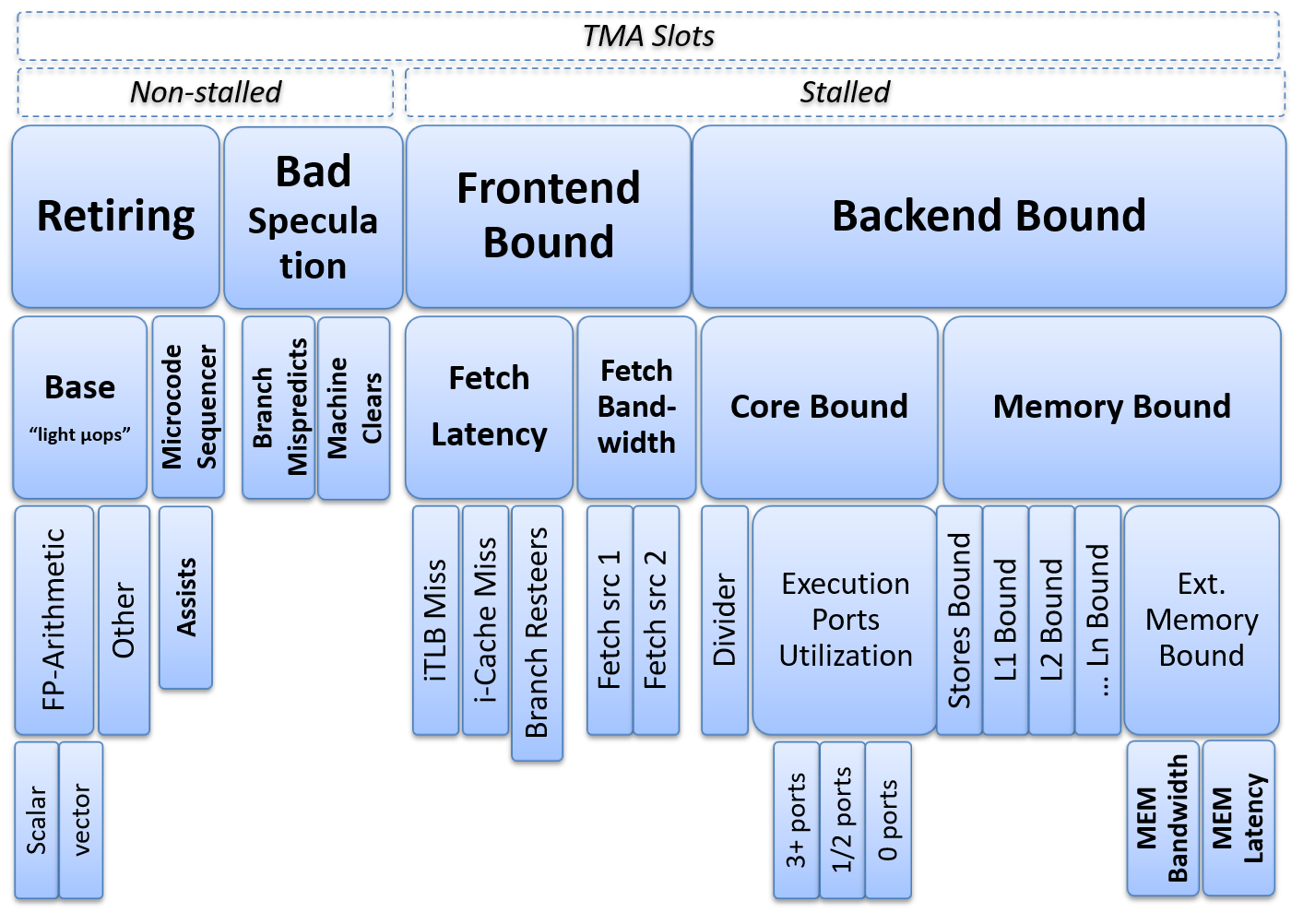
TMA 性能瓶颈层次结构。© 图片来源:Ahmad Yasin。
多次运行工作负载是可以接受的,每次深入一层并聚焦于特定指标。但通常情况下,运行一次工作负载并收集 TMA 所有层级所需的全部指标就已足够。性能剖析工具通过在单次运行期间对不同性能事件进行复用(见 [secMultiplex])来实现这一点。此外,在实际应用中,性能可能同时受到多个因素的限制。例如,一个应用程序可能同时出现大量分支预测错误(错误推测)和缓存缺失(后端受限)。在这种情况下,TMA 会同时向多个分类深入,并识别每种瓶颈类型对程序性能的影响。Intel 的 VTune Profiler、AMD 的 uProf 以及 Linux perf 等分析工具,都可以在单次基准测试运行中计算出所有 TMA 指标。但这仅在工作负载行为稳定的情况下才可接受,否则最好还是回退到多次运行、逐层深入的原始策略。
TMA 的前两层指标以程序执行期间可用的流水线槽位(pipeline slot,见 [PipelineSlot])百分比来表示。这使得 TMA 能够考虑处理器的全部带宽,从而准确地表示 CPU 微架构的利用率。到目前为止,所有数值加起来应该恰好等于 100%。然而,从第 3 层开始,分类可能以不同的计数域来表示,例如时钟周期(clocks)和停顿周期(stalls)。因此,它们不一定能与其他 TMA 分类直接比较。
一旦识别出性能瓶颈,我们需要知道它具体发生在代码的哪个位置。TMA 的第二步是将问题源头精确定位到代码行及对应的汇编指令。该分析方法论为每种性能问题类别提供了对应的性能事件。然后,你可以对该事件进行采样,找到在源代码中对第一阶段所识别的性能瓶颈贡献最大的代码行。如果这个过程听起来很复杂,请不必担心,在你阅读完案例研究之后,一切都会变得清晰。
案例研究:利用 TMA 减少缓存缺失次数
作为本案例研究的示例,我选用了一个非常简单的基准测试程序,便于理解和修改。它不能代表真实世界的应用程序,但足以演示 TMA 的工作流程。本书第二部分有更多实际案例。
本书的大多数读者可能会将 TMA 应用于自己熟悉的应用程序。但即使你第一次接触某个应用程序,TMA 也非常有效。因此,我不从展示基准测试的源代码开始。以下是简短描述:该基准测试在堆上分配一个 200 MB 的数组,然后进入一个包含 1 亿次迭代的循环。在每次迭代中,它生成一个随机索引指向已分配的数组,执行一些虚拟工作,然后读取该索引处的值。
我在一台搭载 Intel Core i5-8259U(基于 Skylake)CPU 和 16GB DRAM(DDR4 2400 MT/s)的机器上进行了实验,运行 64 位 Ubuntu 20.04(内核版本 5.13.0-27)。
步骤 1:识别瓶颈
第一步,我们运行微基准测试并收集有限的事件集,用于计算第 1 层指标。在这里,我们尝试通过将其归入四个 L1 分类来识别应用程序的高层性能瓶颈:前端受限(Frontend Bound)、后端受限(Backend Bound)、退休(Retiring)和错误推测(Bad Speculation)。可以使用 Linux perf 工具收集第 1 层指标,perf stat 命令有专用的 --topdown 选项,在较新版本中默认会输出这些指标。以下是我们基准测试的分解结果,本节所有命令的输出均已截断以节省篇幅。
{% math_inline %} perf stat -- ./benchmark.exe
...
TopdownL1 (cpu_core) # 53.4 % tma_backend_bound <==
# 0.2 % tma_bad_speculation
# 13.8 % tma_frontend_bound
# 32.5 % tma_retiring
...
从输出结果可以看出,该应用程序的性能受到 CPU 后端的制约。让我们再深入一层。要获取第 2、3 层及更深层的 TMA 指标,我将使用 toplev 工具,它是 Andi Kleen 编写的 pmu-tools7 的一部分,由 Python 实现,底层使用 Linux perf。使用 toplev 需要启用特定的 Linux 内核设置,详情请查阅文档。
{% endmath_inline %} ~/pmu-tools/toplev.py --core S0-C0 -l2 -v --no-desc taskset -c 0 ./benchmark.exe
...
# Level 1
S0-C0 Frontend_Bound: 13.92 % Slots
S0-C0 Bad_Speculation: 0.23 % Slots
S0-C0 Backend_Bound: 53.39 % Slots
S0-C0 Retiring: 32.49 % Slots
# Level 2
S0-C0 Frontend_Bound.FE_Latency: 12.11 % Slots
S0-C0 Frontend_Bound.FE_Bandwidth: 1.84 % Slots
S0-C0 Bad_Speculation.Branch_Mispred: 0.22 % Slots
S0-C0 Bad_Speculation.Machine_Clears: 0.01 % Slots
S0-C0 Backend_Bound.Memory_Bound: 44.59 % Slots <==
S0-C0 Backend_Bound.Core_Bound: 8.80 % Slots
S0-C0 Retiring.Base: 24.83 % Slots
S0-C0 Retiring.Microcode_Sequencer: 7.65 % Slots
在该命令中,我们将进程固定到 CPU0(使用 taskset -c 0),并将 toplev 的输出限制在该核心(--core S0-C0)。-l2 选项告诉工具收集第 2 层指标,--no-desc 选项禁止输出每个指标的描述。
可以看出,应用程序的性能受到内存访问的制约(Backend_Bound.Memory_Bound)。近一半的 CPU 执行资源被浪费在等待内存请求完成上。现在让我们再深入一层:17
{% math_inline %} ~/pmu-tools/toplev.py --core S0-C0 -l3 -v --no-desc taskset -c 0 ./benchmark.exe
...
# Level 1
S0-C0 Frontend_Bound: 13.91 % Slots
S0-C0 Bad_Speculation: 0.24 % Slots
S0-C0 Backend_Bound: 53.36 % Slots
S0-C0 Retiring: 32.41 % Slots
# Level 2
S0-C0 FE_Bound.FE_Latency: 12.10 % Slots
S0-C0 FE_Bound.FE_Bandwidth: 1.85 % Slots
S0-C0 BE_Bound.Memory_Bound: 44.58 % Slots
S0-C0 BE_Bound.Core_Bound: 8.78 % Slots
# Level 3
S0-C0-T0 BE_Bound.Mem_Bound.L1_Bound: 4.39 % Stalls
S0-C0-T0 BE_Bound.Mem_Bound.L2_Bound: 2.42 % Stalls
S0-C0-T0 BE_Bound.Mem_Bound.L3_Bound: 5.75 % Stalls
S0-C0-T0 BE_Bound.Mem_Bound.DRAM_Bound: 47.11 % Stalls <==
S0-C0-T0 BE_Bound.Mem_Bound.Store_Bound: 0.69 % Stalls
S0-C0-T0 BE_Bound.Core_Bound.Divider: 8.56 % Clocks
S0-C0-T0 BE_Bound.Core_Bound.Ports_Util: 11.31 % Clocks
我们发现瓶颈位于 DRAM_Bound。这表明许多内存访问在所有级别的缓存中均未命中,最终访问到主内存。我们也可以通过收集程序的 L3 缓存缺失绝对次数来确认这一点。对于 Skylake 架构,DRAM_Bound 指标使用 CYCLE_ACTIVITY.STALLS_L3_MISS 性能事件来计算。让我们手动收集该数据:
{% endmath_inline %} perf stat -e cycles,cycle_activity.stalls_l3_miss -- ./benchmark.exe
32226253316 cycles
19764641315 cycle_activity.stalls_l3_miss
CYCLE_ACTIVITY.STALLS_L3_MISS 事件统计执行停顿时(同时存在未完成的 L3 缓存缺失加载请求)的周期数。可以看到约有 60% 的此类周期,情况相当糟糕。
步骤 2:定位代码位置
TMA 过程的第二步是定位代码中识别出的性能事件最频繁发生的位置。为此,应使用与步骤 1 中识别出的瓶颈类型对应的事件对工作负载进行采样。
推荐的方式是使用 --show-sample 选项运行 toplev 工具,它会建议可用于定位问题的 perf record 命令行。为了理解 TMA 的工作机制,我们也介绍手动查找与特定性能瓶颈对应事件的方式。性能瓶颈与应用于确定源代码中瓶颈位置的性能事件之间的对应关系,可借助 TMA metrics2 表格查找。其中 Locate-with 列标注了用于定位代码中问题位置的性能事件。在我们的案例中,要查找导致 DRAM_Bound 指标(即 L3 缓存缺失)值如此之高的内存访问,应对 MEM_LOAD_RETIRED.L3_MISS_PS 精确事件进行采样。示例命令如下:
{% math_inline %} perf record -e cpu/event=0xd1,umask=0x20,name=MEM_LOAD_RETIRED.L3_MISS/ppp -- ./benchmark.exe
{% endmath_inline %} perf report -n --stdio
...
# Samples: 33K of event 'MEM_LOAD_RETIRED.L3_MISS'
# Event count (approx.): 71363893
# Overhead Samples Shared Object Symbol
# ........ ......... .............. .................
#
99.95% 33811 benchmark.exe [.] foo
0.03% 52 [kernel] [k] get_page_from_freelist
0.01% 3 [kernel] [k] free_pages_prepare
0.00% 1 [kernel] [k] free_pcppages_bulk
几乎所有 L3 缓存缺失都是由可执行文件 benchmark.exe 中的函数 foo 内的内存访问引起的。现在是查看基准测试源代码的时候了,源代码可在 GitHub8 上找到。
为了避免编译器优化,函数 foo 以汇编语言实现,如代码清单 TMA_asm 所示。基准测试的"驱动"部分在 main 函数中实现,如代码清单 TMA_cpp 所示。我们分配了一个足够大的数组 a,使其无法放入 6MB L3 缓存。基准测试生成一个随机索引指向数组 a,并将该索引与数组 a 的地址一起传递给 foo 函数。之后,foo 函数读取该随机内存位置。11
代码清单:函数 foo 的汇编代码。
$ perf annotate --stdio -M intel foo
Percent | Disassembly of benchmark.exe for MEM_LOAD_RETIRED.L3_MISS
------------------------------------------------------------
: Disassembly of section .text:
:
: 0000000000400a00 <foo>:
: foo():
0.00 : 400a00: nop DWORD PTR [rax+rax*1+0x0]
0.00 : 400a08: nop DWORD PTR [rax+rax*1+0x0]
... # more NOPs
100.00 : 400e07: mov rax,QWORD PTR [rdi+rsi*1] <==
...
0.00 : 400e13: xor rax,rax
0.00 : 400e16: ret
代码清单:main 函数的源代码。
extern "C" { void foo(char* a, int n); }
const int _200MB = 1024*1024*200;
int main() {
char* a = new char[_200MB]; // 200 MB buffer
...
for (int i = 0; i < 100000000; i++) {
int random_int = distribution(generator);
foo(a, random_int);
}
...
}
通过查看代码清单 TMA_asm,可以看到函数 foo 中所有的 L3 缓存缺失都被归因于一条指令。现在我们知道了哪条指令导致了如此多的 L3 缺失,来修复它吧。
步骤 3:修复问题
foo 函数开头用 NOP 指令模拟了一些虚拟工作。这在获取下一个将被访问的地址与实际加载指令之间创建了一个时间窗口。利用这个时间窗口,我们可以在虚拟工作执行的同时开始预取该内存位置。代码清单 TMA_prefetch 展示了这一思路的具体实现。关于显式内存预取(explicit memory prefetching)技术的更多信息,请参见 [memPrefetch]。
代码清单:在 main 函数中插入内存预取。
for (int i = 0; i < 100000000; i++) {
int random_int = distribution(generator);
+ __builtin_prefetch ( a + random_int, 0, 1);
foo(a, random_int);
}
这一显式内存预取提示将执行时间从 8.5 秒减少到了 6.5 秒。同时,CYCLE_ACTIVITY.STALLS_L3_MISS 事件的次数减少了近十倍:从 190 亿次降至 20 亿次。
TMA 是一个迭代过程,因此一旦修复了一个问题,我们需要从步骤 1 重新开始。很可能瓶颈会转移到另一个分类,在本例中是退休(Retiring)。这是一个演示 TMA 方法论工作流程的简单示例。分析真实世界的应用程序不太可能如此简单。本书第二部分的章节经过精心组织,方便与 TMA 过程配合使用。具体来说,第 8 章涵盖内存受限(Memory Bound)类别,第 9 章涵盖核心受限(Core Bound),第 10 章涵盖错误推测(Bad Speculation),第 11 章涵盖前端受限(Frontend Bound)。这种结构旨在形成一份检查清单,当你遇到特定性能瓶颈时,可以用来指导代码改进。
2. TMA 指标 - https://github.com/intel/perfmon/blob/main/TMA_Metrics.xlsx. ↩
7. PMU 工具 - https://github.com/andikleen/pmu-tools. ↩
8. 案例研究示例 - https://github.com/dendibakh/dendibakh.github.io/tree/master/_posts/code/TMAM. ↩
11. 根据 x86 Linux 调用约定(https://en.wikipedia.org/wiki/X86_calling_conventions),前两个参数分别放入rdi和rsi寄存器。 ↩
17. 另一种方式是使用-l2 --nodes L1_Bound,L2_Bound,L3_Bound,DRAM_Bound,Store_Bound选项,而不是-l3,以限制收集范围,因为我们已知该应用程序受内存制约。 ↩