屋顶线性能模型(The Roofline Performance Model)
屋顶线性能模型是一种以吞吐量为导向的性能模型,在高性能计算(HPC)领域被广泛使用。它由加州大学伯克利分校于 2009 年开发 [RooflinePaper]。该模型中的"roofline"(屋顶线)这一术语表达了应用程序的性能不能超过机器能力的事实。程序中的每个函数和每个循环都受到机器计算能力或内存带宽(memory bandwidth)容量的限制。这一概念在图 RooflineIntro 中体现。应用程序的性能始终会受到某个"屋顶线"函数的限制。
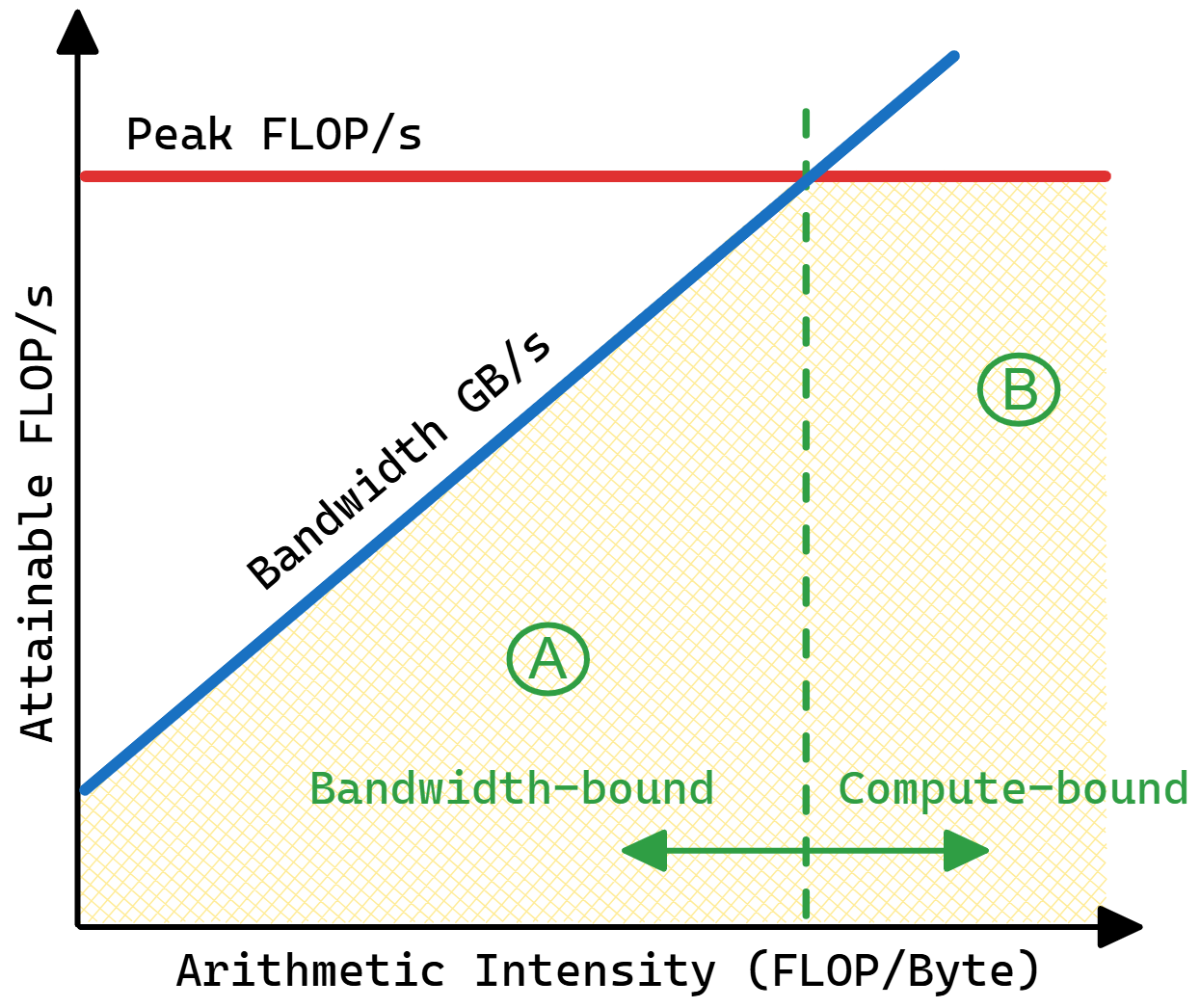
屋顶线性能模型。应用程序的最大性能受到峰值 FLOPS(水平线)与平台带宽乘以算术强度(对角线)之间的最小值限制。
硬件有两个主要限制:计算速度(峰值计算性能,FLOPS)和数据移动速度(峰值内存带宽,GB/s)。应用程序的最大性能受到峰值 FLOPS(水平线)与平台带宽乘以算术强度(arithmetic intensity)(对角线)之间的最小值限制。图 RooflineIntro 中的屋顶线图表将两个应用程序 A 和 B 的性能与硬件限制进行了对比。应用程序 A 算术强度较低,其性能受内存带宽限制(memory bandwidth bound),而应用程序 B 计算密集度更高,不那么受内存瓶颈影响。类似地,A 和 B 可以代表程序中两个不同的函数,具有不同的性能特征。屋顶线性能模型考虑了这一点,并能在同一图表上显示应用程序的多个函数和循环。但请记住,屋顶线性能模型主要适用于具有少量计算密集型循环的 HPC 应用程序。我不建议将其用于通用应用程序,例如编译器、Web 浏览器或数据库。
算术强度(Arithmetic Intensity)是浮点操作数(Floating-point operations,FLOPs)7 与字节数之间的比率,可以为程序中的每个循环计算。让我们计算代码清单 BasicMatMul 中代码的算术强度。在最内层循环体中,我们有一个浮点加法和一个乘法;因此,我们有 2 个 FLOPs。此外,我们有三个读操作和一个写操作;因此,我们传输 4 operations * 4 bytes = 16 字节。该代码的算术强度为 2 / 16 = 0.125。算术强度是屋顶线图表的 X 轴,而 Y 轴测量给定程序的性能。
代码清单:朴素并行矩阵乘法。
void matmul(int N, float a[][2048], float b[][2048], float c[][2048]) {
#pragma omp parallel for
for(int i = 0; i < N; i++) {
for(int j = 0; j < N; j++) {
for(int k = 0; k < N; k++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
}
}
}
}
加速应用程序性能的传统方法是充分利用机器的 SIMD(单指令多数据)和多核(multicore)能力。通常,我们需要针对多个方面进行优化:向量化(vectorization)、内存和线程。屋顶线方法可以帮助评估应用程序的这些特征。在屋顶线图表上,我们可以绘制标量单核(scalar single-core)、SIMD 单核和 SIMD 多核性能的理论最大值(参见图 RooflineIntro2)。这将使我们了解改善应用程序性能的空间。如果我们发现应用程序受计算限制(即具有高算术强度)且低于峰值标量单核性能,我们应该考虑强制向量化(参见 [Vectorization])并将工作分配给多个线程。相反,如果应用程序算术强度低,我们应该寻求改善内存访问(参见 [MemBound])的方法。使用屋顶线模型优化性能的最终目标是将图表上的点向上移动。向量化和线程化将点向上移动,而通过增加算术强度来优化内存访问会将点向右移动,同时也可能提升性能。
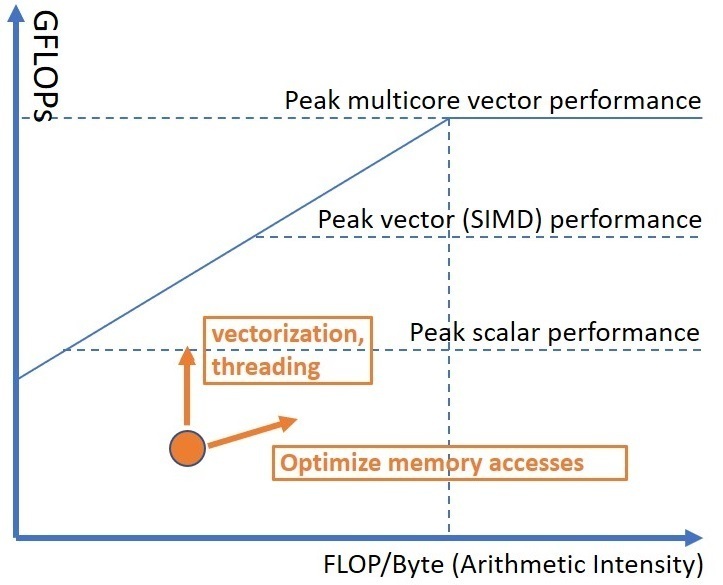
对程序进行屋顶线分析以及提升其性能的潜在方法。
理论最大值(屋顶线)通常在设备规格中列出,可以轻松查阅。此外,理论最大值可以根据你所使用的机器的特性计算得出。一旦了解机器参数,通常并不难做到。对于 Intel Core i5-8259U 处理器,使用 AVX2 和 2 个融合乘加(Fused Multiply Add,FMA)单元的最大 FLOPS(单精度浮点数)可计算为:
我用于实验的 Intel NUC Kit NUC8i5BEH 的最大内存带宽可如下计算。请记住,DDR 技术每次内存访问可传输 64 位或 8 字节。
经验屋顶线工具(Empirical Roofline Tool)2 和 Intel Advisor3 等自动化工具能够通过运行一组准备好的基准测试来经验性地确定理论最大值。如果计算可以重用缓存中的数据,则可以实现更高的 FLOP 速率。屋顶线可以通过为内存层次结构的每个级别引入专用屋顶线来考虑这一点(参见图 RooflineMatrix)。
确定硬件限制后,我们可以开始根据屋顶线评估应用程序的性能。Intel Advisor 自动构建屋顶线图表并为给定循环的性能优化提供提示。Intel Advisor 生成的屋顶线图表示例如图 RooflineMatrix 所示。请注意,屋顶线图表使用对数刻度(logarithmic scales)。
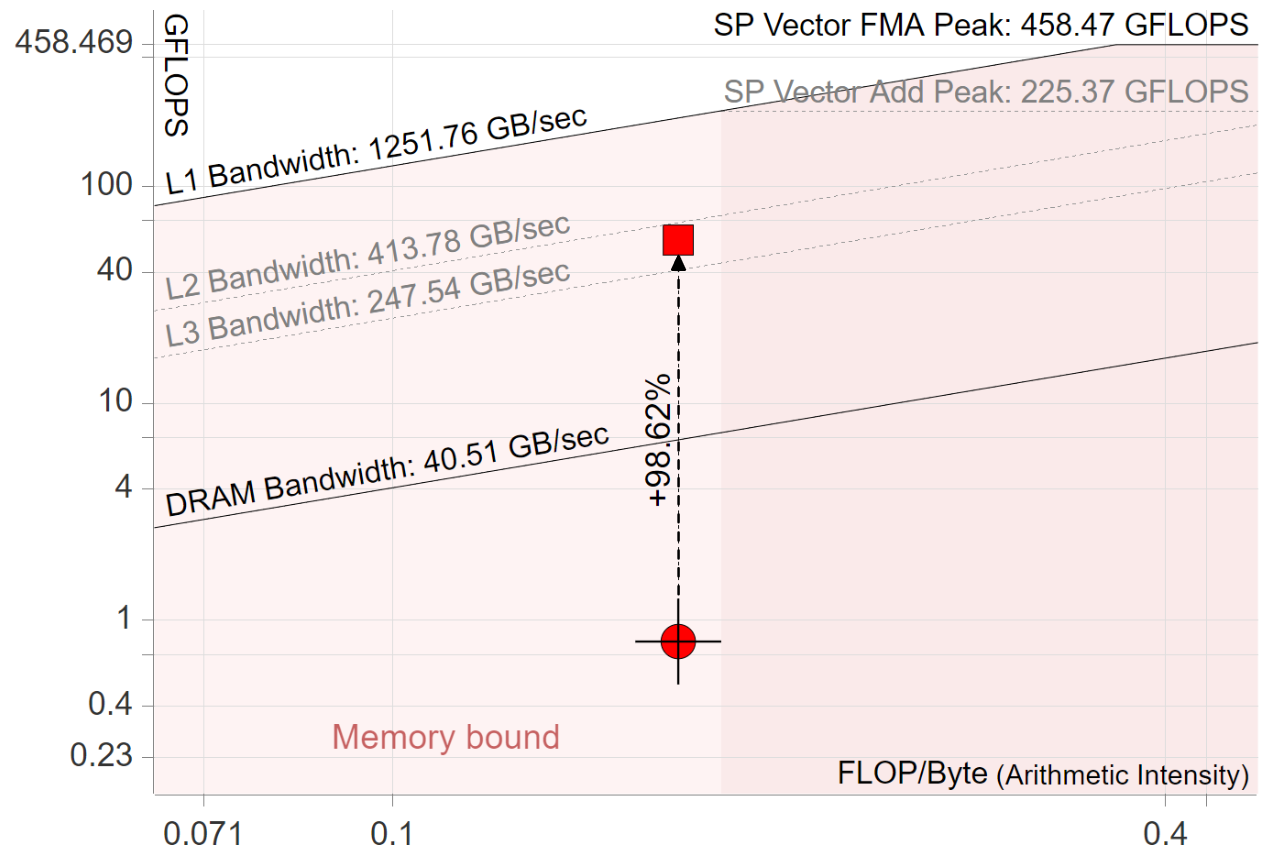
在 Intel NUC Kit NUC8i5BEH(8GB RAM,使用 Clang 10 编译器)上矩阵乘法"之前"和"之后"版本的屋顶线分析。
屋顶线方法通过在同一图表上绘制"之前"和"之后"的点来追踪优化进度,因此这是一个迭代过程,指导开发者帮助其应用程序充分利用硬件能力。图 RooflineMatrix 显示了对早先代码清单 BasicMatMul 中所示代码进行以下两项更改后的性能提升:
- 交换两个最内层循环(交换第 4 行和第 5 行)。这实现了缓存友好的内存访问(参见 [MemBound])。
- 使用 AVX2 指令启用最内层循环的自动向量化(autovectorization)。
总而言之,屋顶线性能模型可以帮助:
- 识别性能瓶颈。
- 指导软件优化。
- 确定何时完成优化。
- 评估相对于机器能力的性能。
2. Empirical Roofline Tool - https://bitbucket.org/berkeleylab/cs-roofline-toolkit/src/master/。 ↩
3. Intel Advisor - https://software.intel.com/content/www/us/en/develop/tools/advisor.html。 ↩
7. 屋顶线性能模型不仅适用于浮点计算,也可用于整数运算。然而,大多数 HPC 应用程序涉及浮点计算,因此屋顶线模型主要与 FLOPs 一起使用。 ↩