持续性能分析
在 [sec_PerfApproaches] 中,我们介绍了进行性能分析的各种方法,包括但不限于插桩(instrumentation)、追踪(tracing)和采样(sampling)。在这三种方法中,采样带来的运行时开销相对较小,前期工作量最少,同时仍能对应用程序热点提供有价值的洞察。然而,这种洞察仅限于采集样本时的特定时间点。如果我们可以为这种采样添加一个时间维度会怎样?与其只知道某一特定时间点 FunctionA 消耗了 30% 的 CPU 周期,不如追踪 FunctionA 的 CPU 使用率在数天、数周或数月内的变化?或者在同样的时间跨度内检测其调用栈的变化,全部在生产环境中进行?持续性能分析(Continuous Profiling)已经出现,将这些目标变为现实。
持续性能分析(CP)是一种系统级、基于采样的性能分析器,始终保持开启状态,但采样率较低以最小化运行时影响。持续收集所有进程的数据有助于分析代码在不同时间执行差异的原因,并在事件发生后辅助调试。CP 工具能够提供关于哪些代码最消耗资源的宝贵洞察,帮助工程师减少生产环境中的资源使用,从而节省成本。与 Linux perf 或 Intel VTune 等典型分析器不同,CP 可以从应用程序栈到内核栈精确定位任意给定日期和时间的性能问题,并支持在任意两个日期/时间之间进行调用栈比较,以突显性能差异。
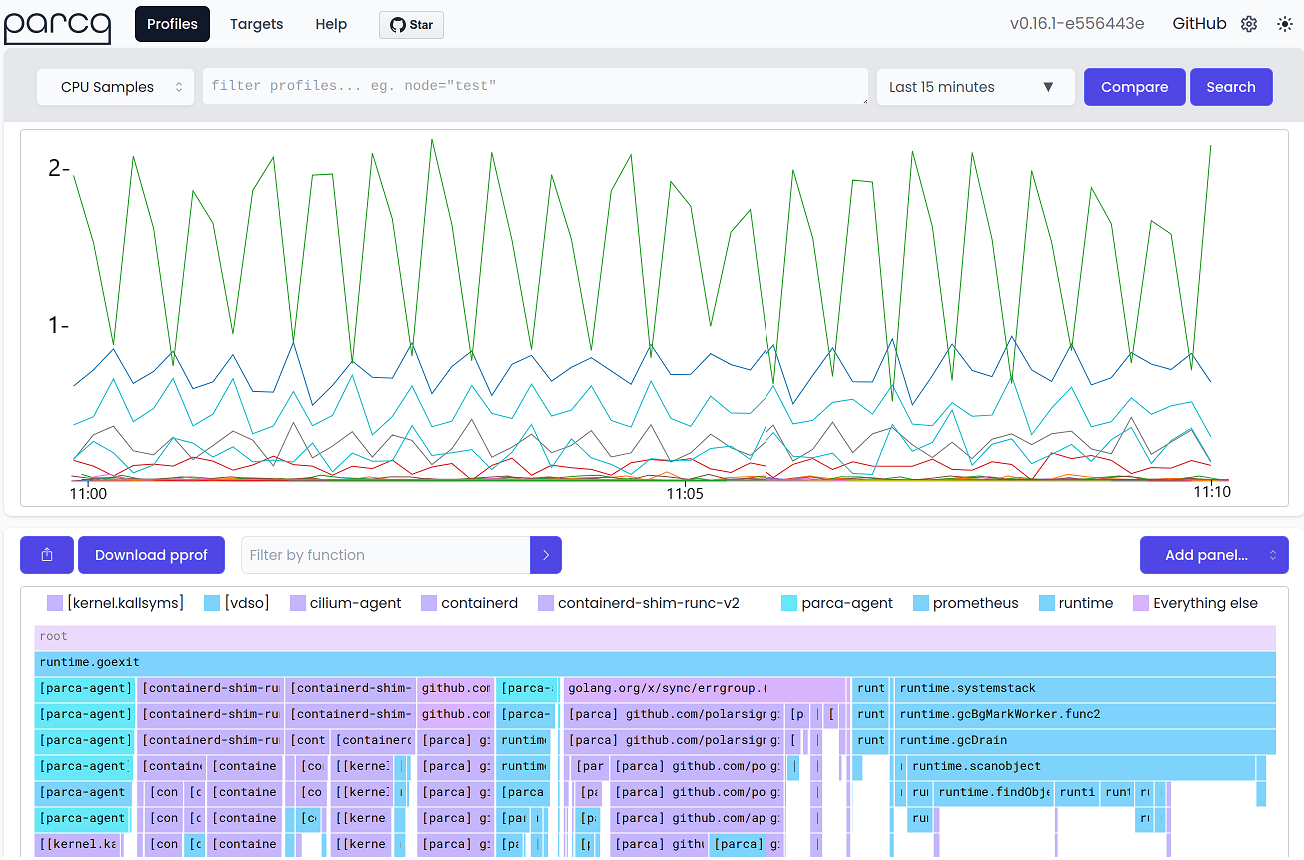
Parca 持续性能分析器 Web UI 截图。
为了展示典型 CP 工具的外观和使用感受,让我们看看 Parca1 的 Web UI,这是图 Continuous_profiling 中展示的一款开源 CP 工具。顶部面板显示了一个时间序列图,展示了在从时间窗口下拉列表中选择的时间段内(本例中为"最近 15 分钟"),从机器上各种进程收集的 CPU 样本数量。然而,为了适应页面,图像被裁剪为只显示最近 10 分钟。
默认情况下,Parca 每秒收集 19 个样本。对于每个样本,它从运行在主机系统上的所有进程收集调用栈。归因于某个进程的样本越多,该进程在一段时间内的 CPU 活动就越多。在我们的示例中,可以看到最热的进程(顶线)具有间歇性行为,CPU 活动有峰值和低谷。如果你是这个应用程序的首席开发人员,你可能会好奇这为什么会发生。当你推出新版本的应用程序,突然看到归因于该进程的 CPU 样本出现意外峰值时,这就表明有什么地方出了问题。
持续性能分析工具不仅更容易发现性能变化发生的时间点,也更容易确定问题的根本原因。一旦你点击图表上任何感兴趣的点,工具就会在底部面板中显示与该时期相关联的冰柱图(icicle graph)。冰柱图是火焰图的倒置版本。使用它,可以比较更改前后的调用栈,帮助你找出导致性能问题的原因。
想象一下,你将一个代码更改合并到生产环境中,在它运行了一段时间后,你收到了间歇性响应时间峰值的报告。这些可能与用户流量相关,也可能与一天中的特定时间相关,也可能毫无规律。这正是 CP 大显身手的领域。你可以打开 CP Web UI,搜索那些响应时间峰值日期和时间的调用栈,然后将它们与其他日期和时间的调用栈进行比较,以识别应用程序和/或内核栈层面的异常执行。这种"视觉差异"分析可以直接在 UI 中支持,类似于图形化的"perf diff"或差异火焰图(differential flamegraph)。2
Google 在 2010 年的论文"Google-Wide Profiling" [GoogleWideProfiling] 中引入了 CP 概念,倡导在生产环境中始终开启性能分析的价值。然而,在业界获得广泛认可花了将近十年的时间:
- 2019 年 3 月,Google Cloud 发布了其 Continuous Profiler。
- 2020 年 7 月,AWS 发布了 CodeGuru Profiler。
- 2020 年 8 月,Datadog 发布了其 Continuous Profiler。
- 2020 年 12 月,New Relic 收购了 Pixie Continuous Profiler。
- 2021 年 1 月,Pyroscope 发布了其开源 Continuous Profiler。
- 2021 年 10 月,Elastic 收购了 Optimyze 及其 Continuous Profiler(Prodfiler);Polar Signals 发布了其 Parca Continuous Profiler,并于 2024 年 4 月开源。
- 2021 年 12 月,Splunk 发布了其 AlwaysOn Profiler。
- 2022 年 3 月,Intel 收购了 Granulate 及其 Continuous Profiler(gProfiler),并于 2024 年 3 月开源。
这一领域的新进入者在开源和商业版本中持续涌现。这些产品中有些比其他的需要更多的配置。例如,有些需要更改源代码或配置文件才能开始性能分析。其他的则需要针对不同语言运行时(如 Ruby、Python、Golang、C/C++/Rust)使用不同的代理。其中最好的产品围绕 eBPF 精心打造了独特优势,只需安装运行时代理即可。
它们还在支持的语言运行时数量、获取可读调用栈调试符号所需的工作量,以及除 CPU 之外可以分析的系统资源类型(如内存、I/O 或锁)方面存在差异。尽管持续性能分析器在上述方面有所不同,但它们都具有为各种语言运行时提供低开销、基于采样的性能分析,以及用于基于 Web 的搜索和查询能力的远程调用栈存储这一共同功能。
持续性能分析的未来方向是什么?Optimyze 的联合创始人 Thomas Dullien——该公司开发了创新性的持续性能分析器 Prodfiler——在 QCon London 2023 的主题演讲中表达了他对一种集群级工具的愿望,该工具能够回答"为什么这个请求很慢?"或"为什么这个请求代价高昂?"这样的问题。在多线程应用程序中,某个特定函数可能在性能分析中显示为最高的 CPU 和内存消耗者,但其职责可能完全在应用程序的关键路径之外,例如一个管家线程(housekeeping thread)。与此同时,另一个 CPU 执行时间微乎其微、几乎不在性能分析中出现的函数,可能对整体应用程序延迟和/或吞吐量产生过大影响。典型的性能分析器无法解决这一不足。由于 CP 工具基本上是随时运行的性能分析器,它们继承了同样的盲点。
幸运的是,新一代 CP 工具已经出现,它们采用具有大型语言模型(Large Language Model)启发架构的 AI 来处理性能分析样本,分析函数之间的关系,并最终以高精度定位直接影响整体吞吐量和延迟的函数和库。目前提供此功能的公司之一是 Raven.io。随着这一领域竞争加剧,创新能力将继续增长,使 CP 工具变得与典型性能分析器一样强大和健壮。
1. Parca - https://github.com/parca-dev/parca ↩
2. Differential flamegraph - https://www.brendangregg.com/blog/2014-11-09/differential-flame-graphs.html ↩