内存性能分析
在本章迄今为止,我们讨论了识别程序大部分时间花费在哪里的工具。在本节中,我们将重点关注程序与内存的交互。这通常称为内存性能分析(memory profiling)。具体而言,我们将学习如何收集内存使用情况、分析堆(heap)分配以及测量内存占用(memory footprint)。内存性能分析帮助你了解应用程序随时间如何使用内存,并帮助你建立对程序与内存交互的准确心理模型。以下是它可以回答的一些问题:
- 程序的总虚拟内存消耗是多少,随时间如何变化?
- 程序在何时何地进行堆分配?
- 哪些代码位置分配的内存量最大?
- 程序每秒访问多少内存?
- 程序的总内存占用是多少?
内存使用情况
内存使用情况通常由虚拟内存大小(Virtual Memory Size,VSZ)和常驻集大小(Resident Set Size,RSS)来描述。VSZ 包括进程可以访问的所有内存,例如栈(stack)、堆(heap)、用于编码可执行文件指令的内存,以及链接的共享库的指令,包括已交换(swapped out)到磁盘/SSD 的内存。另一方面,RSS 衡量分配给进程的内存中有多少驻留在 RAM 中。因此,RSS 不包括已交换出的内存或该进程尚未触及的内存。此外,RSS 不包括未加载到内存中的共享库的内存。通过 mmap 映射到内存的文件也会贡献到 VSZ 和 RSS 使用量。
考虑一个示例。进程 A 有 200K 的栈和堆分配,其中 100K 驻留在主内存中;其余已被交换出或未使用。它有一个 500K 的二进制文件,其中只有 400K 被触及。进程 A 链接了 2500K 的共享库,只将 1000K 加载到主内存中。
VSZ: 200K + 500K + 2500K = 3200K
RSS: 100K + 400K + 1000K = 1500K
开发人员可以在 Linux 上使用标准的 top 工具观察 RSS 和 VSZ,但这两个指标可能变化非常快。幸运的是,有一些工具可以记录和可视化随时间变化的内存使用情况。图 MemoryUsageAIBench 展示了 PSPNet 图像分割算法的内存使用情况,该算法是 AI Benchmark Alpha5 的一部分。该图表基于名为 memory_profiler6 的工具的输出创建,这是一个构建在跨平台 psutil7 包之上的 Python 库。
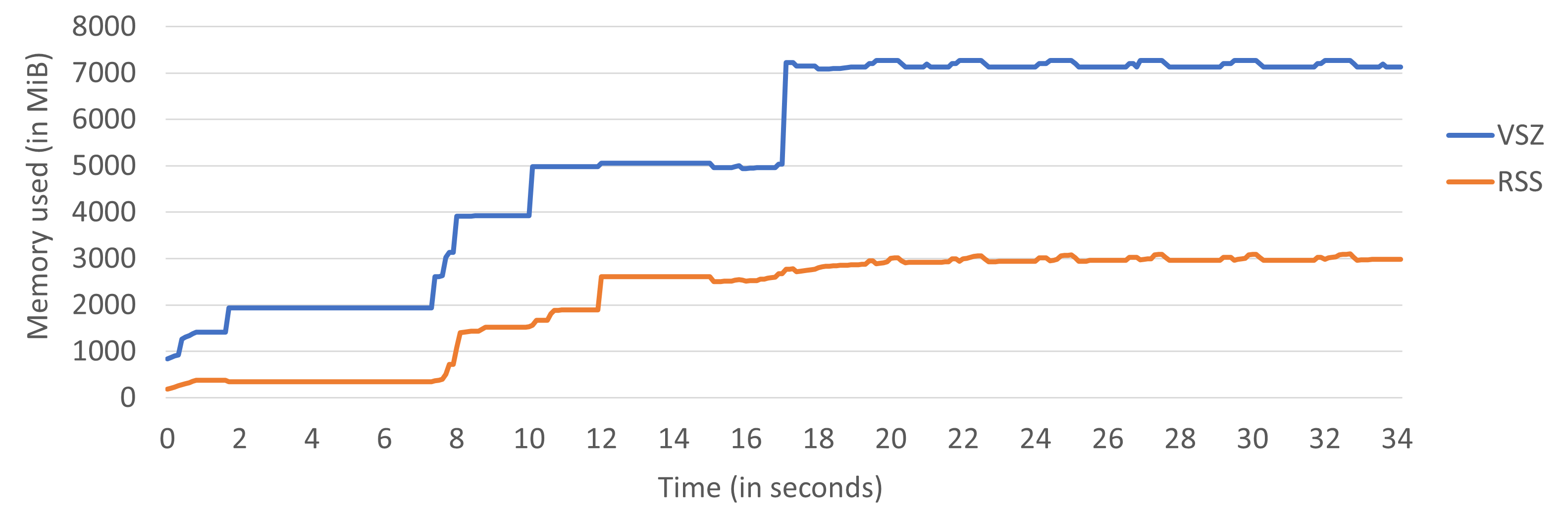
AI_bench PSPNet 图像分割的 RSS 和 VSZ 内存利用率。
除标准的 RSS 和 VSZ 指标外,人们还开发了一些更复杂的指标。由于 RSS 包括进程独有的内存和与其他进程共享的内存,因此不清楚进程自身拥有多少内存。USS(Unique Set Size,唯一集大小)是进程独有的内存,如果进程现在终止,该内存将被释放。PSS(Proportional Set Size,比例集大小)代表唯一内存加上共享内存在共享该内存的进程之间均匀分配的量。例如,如果一个进程有 10 MB 完全属于自己的内存(USS)和 10 MB 与另一个进程共享的内存,则其 PSS 将为 15 MB。psutil 库支持测量这些指标(仅限 Linux),可以通过 memory_profiler 进行可视化。
在 Windows 上,类似的概念由已提交内存大小(Committed Memory Size)和工作集大小(Working Set Size)定义。它们并非 VSZ 和 RSS 的直接等价物,但可用于有效估算 Windows 应用程序的内存使用情况。RAMMap8 工具为系统和各个进程的内存使用情况提供了丰富的信息集。
当开发人员谈论内存消耗时,他们隐含地指的是堆使用情况。实际上,堆是大多数应用程序中最大的内存消耗者,因为它容纳了所有动态分配的对象。但堆并不是唯一的内存消耗者。为完整起见,让我们提一下其他内存消耗者:
- 栈(Stack):应用程序中栈帧使用的内存。应用程序内的每个线程都有自己的栈内存空间。通常,栈大小只有几 MB,如果超出限制,应用程序将崩溃。例如,Linux 上栈内存的默认大小通常为 8MB,尽管可能因发行版和内核设置而异。macOS 上的默认栈大小也是 8MB,但在 Windows 上只有 1 MB。总栈内存消耗与系统中运行的线程数成正比。
- 代码(Code):用于存储应用程序及其库的代码(指令)的内存。在大多数情况下,它对内存消耗的贡献不大,但也有例外。例如,Clang 17 C++ 编译器有一个 33 MB 的代码节,而最新的 Windows Chrome 浏览器其 219MB 的
chrome.dll中有 187MB 专用于代码。然而,并非所有代码部分在程序运行时都被频繁执行。我们在 [CodeFootprint] 中展示了如何测量代码占用。
由于堆通常是内存资源最大的消耗者,因此开发人员在分析应用程序的内存利用情况时专注于这部分内存是有意义的。在下一节中,我们将在一个流行的真实世界应用程序中检查堆消耗和内存分配。
案例研究:分析 Stockfish 的堆分配
在本案例研究中,我使用 heaptrack2,这是 KDE 开发的一款面向 Linux 的开源堆内存分析器。Ubuntu 用户可以使用 apt install heaptrack heaptrack-gui 轻松安装。Heaptrack 可以找到代码中发生最大且最频繁分配的位置等。在 Windows 上,可以使用 Mtuner3,其功能与 Heaptrack 类似。
我分析了 Stockfish4 国际象棋引擎的内置基准测试,我们已在 [PerfMetricsCaseStudy] 中研究过它。与之前一样,我使用 Clang 15 编译器以 -O3 -mavx2 选项编译。我在 Intel Alder Lake i7-1260P 处理器上使用以下命令收集了单线程 Stockfish 内置基准测试的 Heaptrack 内存配置文件:
$ heaptrack ./stockfish bench 128 1 24 default depth
图 StockfishSummary 为我们显示了 Stockfish 内存配置文件的摘要视图。以下是我们可以从中了解到的一些有趣事实:
- 总分配次数为 10614。
- 近一半的分配是临时性的,即紧随其后就被释放的分配。
- 峰值堆内存消耗为 204 MB。
Stockfish::std_aligned_alloc负责已分配堆空间的最大部分(182 MB)。但它并不在最频繁的分配位置中(中间表格),因此它可能被分配一次后一直存活到程序结束。- 几乎一半的分配调用来自
operator new,这些都是临时分配。我们能摆脱临时分配吗?你稍后会知道答案。 - 内存泄漏对本案例研究不是问题。
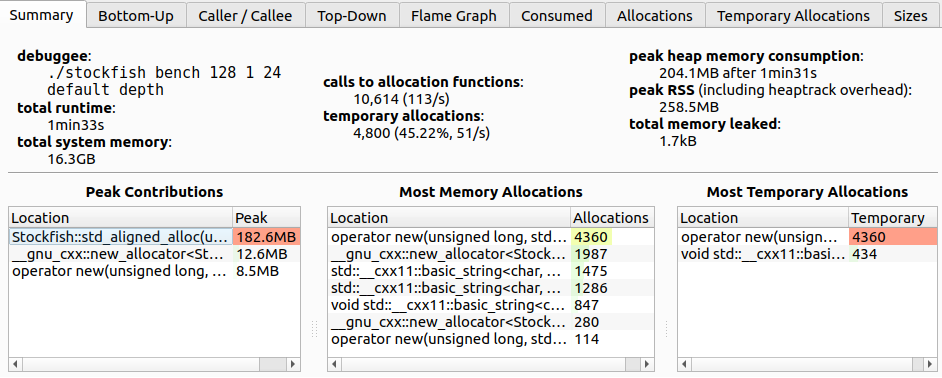
Stockfish 的 Heaptrack 内存配置文件,摘要视图。
注意,图像顶部有许多标签页;我们将探索其中一些。图 StockfishMemUsage 显示了 Stockfish 内置基准测试的内存使用情况。在整个程序运行过程中,内存使用始终保持在 200 MB 不变。总消耗内存被分割成切片,例如图中的区域①和②。每个切片对应一个特定的分配。有趣的是,通过 Stockfish::std_aligned_alloc 进行的并不是我们之前认为的单次大型 182 MB 分配。相反,有两次:切片①为 134.2 MB,切片②为 48.4 MB。两个分配都一直存活到基准测试的最后。
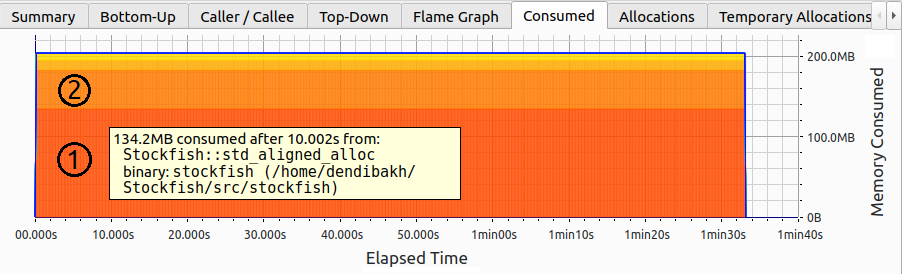
Stockfish 的 Heaptrack 内存配置文件,内存使用随时间保持不变。
这是否意味着启动阶段之后没有内存分配了?让我们来查明。图 StockfishAllocations 显示了随时间累积的分配次数。与内存消耗图表(图 StockfishMemUsage)类似,分配按照每个函数归因的累积内存分配次数切片。如我们所见,新的分配持续来自不止一个地方,而是许多地方。最频繁的分配通过 operator new 进行,对应图中的区域①。
注意整个程序生命周期内以稳定速度出现新分配。然而,正如我们刚才看到的,内存消耗没有变化;这怎么可能呢?嗯,如果我们释放之前分配的缓冲区并分配相同大小的新缓冲区(也称为临时分配),这是可能的。
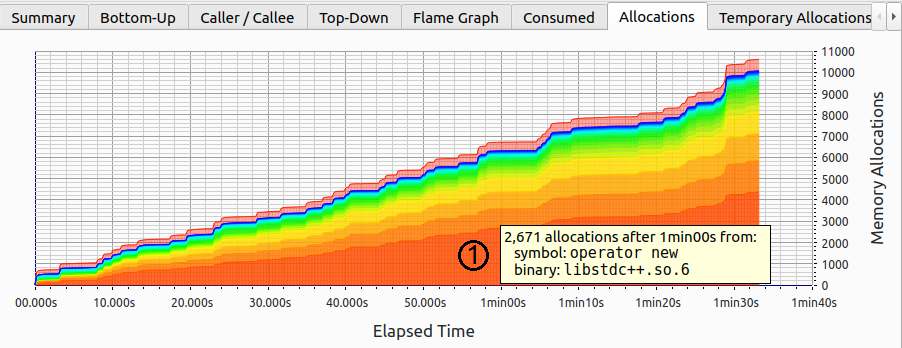
Stockfish 的 Heaptrack 内存配置文件,分配次数持续增长。
由于分配次数在增长但总消耗内存没有变化,我们正在处理临时分配。让我们找出它们在代码的哪个位置产生的。使用图 StockfishFlamegraph 中展示的火焰图可以轻松做到这一点。共有 4800 次临时分配,其中 90.8% 来自 operator new。借助火焰图,我们知道了导致 4360 次临时分配的完整调用栈。有趣的是,这些临时分配是由 std::stable_sort 发起的,它分配了一个临时缓冲区来进行排序。消除这些临时分配的一种方式是使用原地稳定排序算法。然而,这样做后我观察到性能下降了 8%,因此我放弃了这个更改。
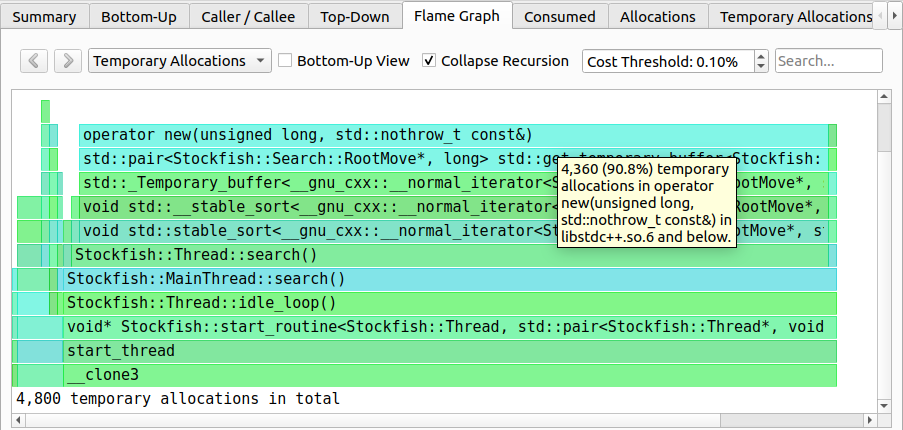
Stockfish 的 Heaptrack 内存配置文件,临时分配火焰图。
与临时分配类似,你还可以在程序中找到导致最大分配的路径。在图 StockfishFlamegraph 顶部的下拉菜单中,你需要选择"Consumed"火焰图。
内存强度与占用
在本节中,我将展示如何测量程序的内存强度(intensity)和内存占用(footprint)。内存强度指程序在某一时间区间内访问的数据大小,例如以每秒 MB 为单位。内存强度高的程序会大量使用内存系统,通常访问大量数据。另一方面,内存强度低的程序相对较少进行内存访问,可能更受计算限制(compute-bound),即花费更多时间进行计算而非等待来自内存的数据。在短时间区间内测量内存强度使我们能够观察其随时间的变化。
内存占用(Memory footprint)测量应用程序访问的总字节数。在计算内存占用时,我们只考虑唯一的内存位置。也就是说,如果一个内存位置在程序的整个生命周期内被访问了两次,我们只计算被触及的内存一次。
图 MemFootCaseStudyFourBench 展示了四个工作负载的内存强度和占用:Blender 光线追踪、Stockfish 国际象棋引擎、Clang++ 编译和 AI_bench PSPNet 分割。我们使用 Intel SDE(软件开发模拟器,Software Development Emulator)工具,采用 Easyperf 博客6上描述的方法,以 10 亿条指令为间隔收集图表数据。
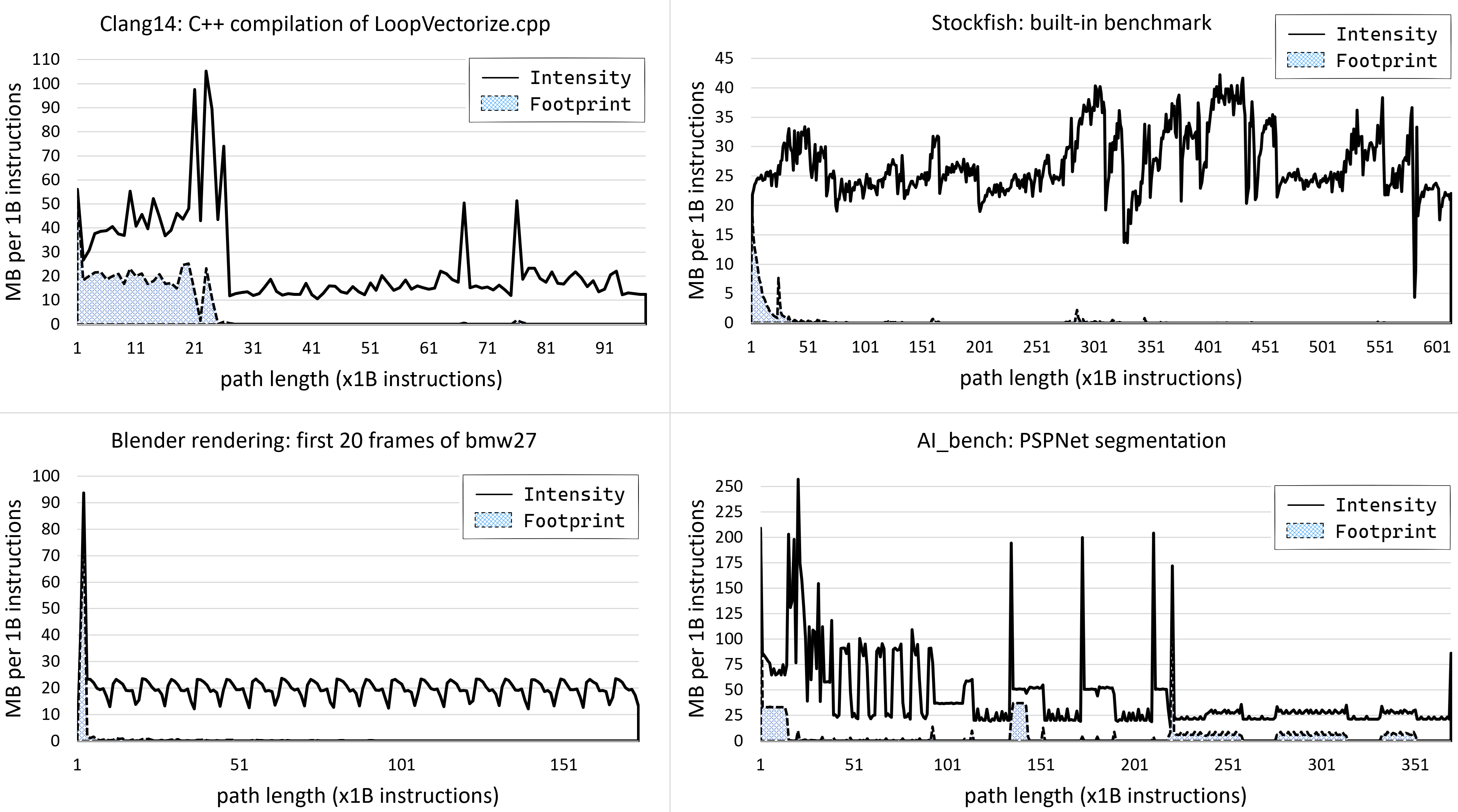
四个工作负载的内存强度和占用。强度:每 10 亿条指令区间内访问的总内存。占用:之前未见过的已访问内存。
实线(Intensity,强度)追踪每个 10 亿条指令区间内访问的字节数。这里,我们不计算某个内存位置被访问了多少次。如果一个内存位置在区间 I 内被加载了两次,我们只计算被触及的内存一次。但是,如果该内存位置在随后的区间 I+1 中第三次被访问,它将贡献到区间 I+1 的内存强度。正因如此,我们不能对时间区间进行聚合。例如,可以看到 Blender 基准测试平均每个区间大约触及 20MB。我们不能将其 150 个连续区间聚合并说 Blender 的内存占用为 150 * 20MB = 3GB。只有当程序从不跨区间重复内存访问时,这才成立。
虚线(Footprint,占用)追踪自程序启动以来每个 10 亿条指令区间内新访问的数据大小。这里,我们计算每个 10 亿条指令区间内程序之前从未触及过的访问字节数。将所有区间聚合(虚线下方的交叉阴影面积)给出程序的总内存占用。以下是我们基准测试的内存占用数字:Clang C++ 编译(487MB);Stockfish(188MB);PSPNet(1888MB);Blender(149MB)。请记住,这些唯一内存位置可能被访问多次,因此即使占用相对较小,对内存子系统的总体压力也可能很高。
如你所见,我们的工作负载具有非常不同的行为。Clang 编译在开始时具有高内存强度,有时峰值达到每 10 亿条指令 100MB,但之后降至约每 10 亿条指令 15MB。图表上的任何峰值都可能引起 Clang 开发人员的关注:它们是预期的吗?它们是否与某个内存密集的优化过程有关?访问的内存位置是否可以压缩?
Blender 基准测试非常稳定;我们可以看到每个渲染帧的开始和结束。这使我们能够专注于单个帧,而无需查看整个 1000+ 帧的工作负载。Stockfish 基准测试更加混乱,可能是因为国际象棋引擎处理需要不同资源量的不同棋局。最后,PSPNet 分割的内存强度非常有趣,我们可以发现重复的模式。初始启动后,从 40B 到 95B 有五六个正弦波,然后是三个以急剧峰值到 200MB 结尾的区域,然后是三个大致平稳徘徊在每 10 亿条指令约 25MB 的区域。这是可以用来优化应用程序的可行信息。
这类图表帮助我们估算内存强度并测量应用程序的内存占用。通过观察图表,可以发现各个阶段并将其与底层算法相关联。问自己:"这看起来符合你的预期吗,还是工作负载正在做一些隐蔽的事情?" 你可能会遇到意外的内存强度峰值。在许多情况下,内存性能分析帮助识别了问题,或者作为支持常规性能分析得出结论的额外数据点。
在某些场景下,内存占用帮助我们估算对内存子系统的压力。例如,如果内存占用较小(几兆字节),我们可能会怀疑对内存子系统的压力很低,因为数据很可能驻留在 L3 缓存中;请记住,现代处理器中可用的内存带宽从几十到几百 GB/s 不等,并且正在接近 1 TB/s。另一方面,当我们处理一个每秒访问 10 GB 且内存占用远大于 L3 缓存大小的应用程序时,该工作负载可能会对内存子系统施加显著压力。
虽然本章讨论的内存性能分析技术确实有助于更好地理解工作负载的行为,但这还不足以完全评估内存访问的时间局部性(temporal locality)和空间局部性(spatial locality)。我们仍然无法了解某个内存位置被访问了多少次,两次连续访问同一内存位置之间的时间间隔是多少,以及内存是顺序访问、跨步访问还是完全随机访问。应用程序的数据局部性(data locality)话题已经被研究了很长时间。不幸的是,截至 2024 年初,还没有可供生产使用的工具能够提供此类信息。进一步的细节超出了本书的范围,但好奇的读者欢迎阅读 Easyperf 博客上的相关文章9。
1. Intel SDE - https://www.intel.com/content/www/us/en/developer/articles/tool/software-development-emulator.html ↩
2. Heaptrack - https://github.com/KDE/heaptrack ↩
3. MTuner - https://github.com/milostosic/MTuner ↩
4. Stockfish - https://github.com/official-stockfish/Stockfish ↩
5. AI Benchmark Alpha - https://ai-benchmark.com/alpha.html ↩
6. Easyper blog: Measuring memory footprint with SDE - https://easyperf.net/blog/2024/02/12/Memory-Profiling-Part3 ↩
7. psutil - https://github.com/giampaolo/psutil ↩
8. RAMMap - https://learn.microsoft.com/en-us/sysinternals/downloads/rammap ↩
9. Easyperf blog: Data Locality and Reuse Distances - https://easyperf.net/blog/2024/02/12/Memory-Profiling-Part5 ↩