静态性能分析(Static Performance Analysis)
如今,我们有大量用于静态代码分析(static code analysis)的工具。对于 C 和 C++ 语言,我们有诸如 Clang 静态分析器(Clang static analyzer)、Klocwork、Cppcheck 等知名工具。这些工具旨在检查代码的正确性和语义(semantics)。同样,某些工具尝试解决代码的性能方面问题。静态性能分析工具不执行或剖析程序,而是模拟代码,就像它在真实硬件上执行一样。静态预测性能几乎是不可能的,因此这种分析类型有许多限制。
首先,无法对 C/C++ 代码进行静态性能分析,因为我们不知道它将被编译成什么机器码。因此,静态性能分析在汇编代码(assembly code)上进行。
其次,静态分析工具模拟工作负载而不是执行它。这显然非常慢,因此无法静态分析整个程序。相反,工具会取一段汇编代码并尝试预测它在真实硬件上的行为。用户应该选择特定的汇编指令(通常是一个小循环)进行分析。因此,静态性能分析的范围非常有限。
静态性能分析工具的输出相当底层,通常将执行分解到 CPU 周期级别。通常,开发者使用它对关键代码区域进行精细调优(fine-grained tuning),在这些区域中每个 CPU 周期都很重要。
静态与动态分析工具的比较
静态工具(Static tools)。它们不运行实际代码,而是尝试模拟执行,尽可能保留微架构(microarchitectural)细节。由于不运行代码,它们无法进行真实测量(执行时间、性能计数器)。优点在于你不需要真实硬件,可以为不同的 CPU 世代模拟代码。另一个好处是你不需要担心结果的一致性:静态分析工具将始终给出确定性的(deterministic)输出,因为模拟(与在真实硬件上执行相比)不会以任何方式产生偏差。静态工具的缺点是它们通常无法预测和模拟现代 CPU 内部的所有内容:它们基于一个可能存在缺陷和限制的模型。静态性能分析工具的示例有 UICA2 和 llvm-mca。3
动态工具(Dynamic tools)。它们基于在真实硬件上运行代码并收集有关执行的各种信息。这是证明任何性能假设的唯一 100% 可靠方法。作为缺点,通常需要具有特权访问权限才能收集 PMC 等底层性能数据。编写一个好的基准测试并测量你想要测量的内容并不总是容易的。最后,你需要过滤噪声和各种副作用。两个动态微架构性能分析工具的示例是 nanoBench5 和 uarch-bench。4
案例研究:使用 UICA 优化 FMA 吞吐量(Case Study: Using UICA to Optimize FMA Throughput)
开发者经常问的一个问题是:"最新的处理器有 10 多个执行单元;我如何编写代码以使它们始终保持繁忙?"这确实是最难解决的问题之一。有时它需要在微观层面审视程序的运行方式。UICA 模拟器就是这样一个显微镜,它帮助你深入了解代码如何在现代处理器中流动。
让我们看看代码清单 FMAthroughput 中的代码。我故意让示例尽可能简单。尽管现实世界的代码当然通常比这更复杂。代码将数组 a 的每个元素乘以浮点值 B,并将乘积累加到 sum 中。在右侧,我展示了由 Clang-16 在使用 -O3 -ffast-math -march=core-avx2 编译时为循环生成的机器码。
代码清单:FMA 吞吐量
float foo(float * a, float B, int N){ │ .loop:
float sum = 0; │ vfmadd231ps ymm2, ymm1, [rdi + rsi]
for (int i = 0; i < N; i++) │ vfmadd231ps ymm3, ymm1, [rdi + rsi + 32]
sum += a[i] * B; │ vfmadd231ps ymm4, ymm1, [rdi + rsi + 64]
return sum; │ vfmadd231ps ymm5, ymm1, [rdi + rsi + 96]
} │ sub rsi, -128
│ cmp rdx, rsi
│ jne .loop
这是一个归约循环(reduction loop),即我们需要对所有乘积求和,最终返回一个单精度浮点值。按照代码的写法,sum 存在循环携带依赖(loop-carry dependency)。在累加上一个乘积之前,你无法覆写 sum。一种聪明的并行化方法是使用多个累加器(accumulators),最后将它们合并。因此,不是使用单个 sum,而是可以用 sum1 累加偶数迭代的结果,sum2 累加奇数迭代的结果。
这正是 Clang-16 所做的:它有 4 个向量(ymm2-ymm5),每个向量持有 8 个浮点累加器,并且它使用 FMA(融合乘加,Fused Multiply Add)将乘法和加法融合成单条指令。常量 B 被广播到 ymm1 寄存器中。-ffast-math 选项允许编译器重新关联浮点运算;我们将在 [Vectorization] 中讨论该选项如何帮助优化。9
代码看起来不错,但它是最优的吗?让我们来验证一下。我们将代码清单 FMAthroughput 中的汇编片段提交给 UICA 并进行了模拟。在撰写本文时,UICA 不支持 Alder Lake(Intel 第 12 代,基于 Golden Cove),因此我们在最新可用的 Rocket Lake(Intel 第 11 代,基于 Sunny Cove)上运行了它。尽管架构不同,但这个实验揭示的问题在两者中都同样明显。模拟结果如图 FMA_tput_UICA 所示。这是一个流水线图(pipeline diagram),类似于我们在第 3 章中展示的。我们跳过了前两次迭代,只展示迭代 2 和 3(最左列"It.")。此时执行达到稳定状态,之后的所有迭代看起来都非常相似。
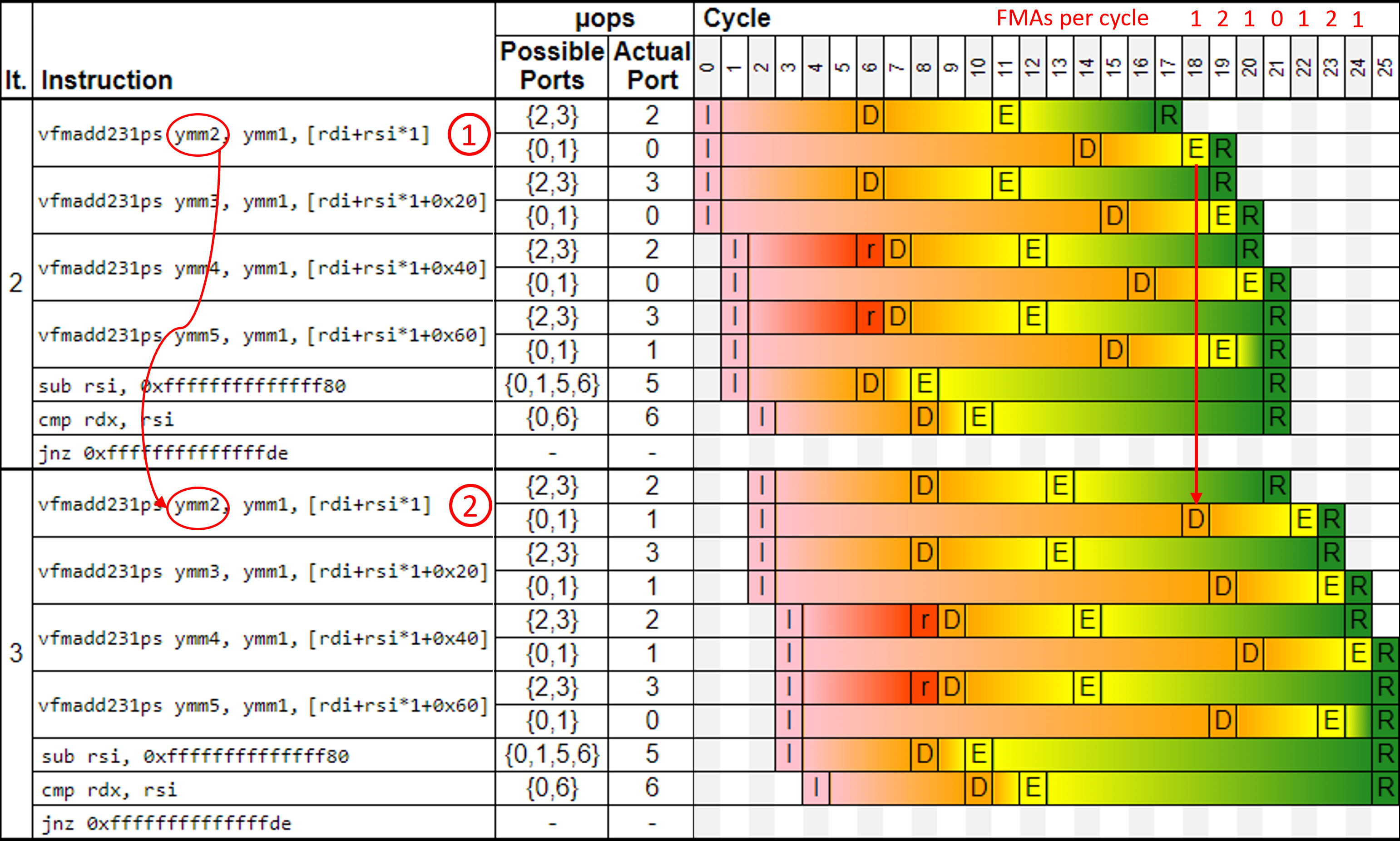
UICA 流水线图。`I` = 发射(issued),`r` = 准备好调度(ready for dispatch),`D` = 已调度(dispatched),`E` = 已执行(executed),`R` = 已退役(retired)。
UICA 是实际 CPU 流水线的一个非常简化的模型。例如,你可能注意到取指(instruction fetch)和译码(decode)阶段缺失。此外,UICA 不考虑缓存缺失和分支预测错误,因此它假设所有内存访问总是命中 L1 缓存,且分支总是被正确预测,而我们知道在现代处理器中并非如此。同样,这与我们的实验无关,因为我们仍然可以使用模拟结果来找到改进代码的方法。
你能看到性能问题吗?让我们检查一下图表。首先,每个 FMA 指令被分解为两个 μops(见图 FMA_tput_UICA 中的 ①):一个去往端口(ports){2,3} 的加载(load)μop 和一个可以去往端口 {0,1} 的 FMA μop。加载 μop 的延迟为 5 个周期:它从第 7 个周期开始,在第 11 个周期完成。FMA μop 的延迟为 4 个周期:它从第 15 个周期开始,在第 18 个周期完成。所有 FMA μops 都依赖于加载 μops,从图表中可以看出:FMA μops 总是在对应的加载 μop 完成后才开始。现在找到第 6 个周期中的两个 r 单元格,它们已准备好被调度,但 Rocket Lake 只有两个加载端口,而且两个端口在同一周期内已被占用。因此,这两个加载在下一个周期发射。
循环在 ymm2-ymm5 上有四个跨迭代依赖(cross-iteration dependencies)。写入 ymm2 的指令 ② 的 FMA μop 不能在前一次迭代的指令 ① 完成之前开始执行。注意,指令 ② 的 FMA μop 在指令 ① 完成执行的同一个第 18 个周期内被调度。指令 ① 和指令 ② 之间存在数据依赖(data dependency)。你也可以在其他 FMA 指令中观察到这种模式。
那么,"问题是什么?"你问道。看图像的右上角。对于每个周期,我们添加了执行的 FMA μops 数量(这不是 UICA 打印的)。它像 1,2,1,0,1,2,1,... 这样变化,平均每个周期一个 FMA μop。大多数近期的 Intel 处理器有两个 FMA 执行单元,因此每个周期可以发射两个 FMA μops。因此,我们只利用了可用 FMA 执行吞吐量的一半。图表清楚地显示了每隔四个周期没有 FMA 执行的间隔。正如我们之前所了解的,之所以没有 FMA μops 被调度,是因为它们的输入(ymm2-ymm5)尚未就绪。
为了将 FMA 执行单元的利用率从 50% 提高到 100%,我们需要将累加器数量从 4 个增加到 8 个,实际上是将循环展开两倍。我们将有 8 条独立数据流链(data flow chains),而不是 4 条。我在这里不展示展开版本的模拟;你可以自行实验。相反,让我们通过在真实硬件上运行两个版本来验证假设。顺便说一句,始终进行验证是个好主意,因为像 UICA 这样的静态性能分析工具并不是精确的模型。下面,我们展示了在 Alder Lake 处理器上运行的两个 nanoBench 测试的输出。该工具接受提供的汇编指令(-asm 选项)并创建一个基准测试内核(benchmark kernel)。读者可以在 nanoBench 文档中查找其他参数的含义。左边的原始代码在 4 个周期内执行 4 条指令,而改进版本可以在 4 个周期内执行 8 条指令。现在我们可以确信已经最大化了 FMA 执行吞吐量,因为右边的代码始终保持 FMA 单元繁忙。
# ran on Intel Core i7-1260P (Alder Lake)
{% math_inline %} sudo ./kernel-nanoBench.sh -f │ {% endmath_inline %} sudo ./kernel-nanoBench.sh -f
-basic -loop 100 -unroll 1000 │ -basic -loop 100 -unroll 1000
-warm_up_count 10 -asm " │ -warm_up_count 10 -asm "
VFMADD231PS YMM0, YMM1, [R14]; │ VFMADD231PS YMM0, YMM1, [R14];
VFMADD231PS YMM2, YMM1, [R14+32]; │ VFMADD231PS YMM2, YMM1, [R14+32];
VFMADD231PS YMM3, YMM1, [R14+64]; │ VFMADD231PS YMM3, YMM1, [R14+64];
VFMADD231PS YMM4, YMM1, [R14+96];" │ VFMADD231PS YMM4, YMM1, [R14+96];
-asm_init "<not shown>" │ VFMADD231PS YMM5, YMM1, [R14+128];
│ VFMADD231PS YMM6, YMM1, [R14+160];
Instructions retired: 4.00 │ VFMADD231PS YMM7, YMM1, [R14+192];
Core cycles: 4.00 │ VFMADD231PS YMM8, YMM1, [R14+224]"
│ -asm_init "<not shown>"
│
│ Instructions retired: 8.00
│ Core cycles: 4.00
根据经验,在这种情况下,循环必须展开 T * L 倍,其中 T 是指令的吞吐量(throughput),L 是其延迟(latency)。在我们的情况下,我们应该展开 2 * 4 = 8 次以实现最大 FMA 端口利用率,因为 Alder Lake 上 FMA 的吞吐量为 2,FMA 的延迟为 4 个周期。这创建了 8 条可以独立执行的独立数据流链。
值得一提的是,在实践中你不会总是看到 2 倍的加速。这只能在 UICA 或 nanoBench 这样的理想化环境中实现。在真实应用程序中,即使你最大化了 FMA 的执行吞吐量,由于最终出现的缓存缺失和其他流水线冒险(pipeline hazards),收益可能会受到影响。当这种情况发生时,缓存缺失的影响超过了次优 FMA 端口利用率的影响,这很容易导致仅有 5% 的令人失望的加速。但不要担心;你仍然做了正确的事情。
作为结语,让我们提醒你,UICA 或任何其他静态性能分析工具都不适合分析大量代码。但它们非常适合探索微架构效应。此外,它们帮助你建立 CPU 工作方式的心智模型(mental model)。UICA 的另一个非常重要的用例是查找循环中的关键依赖链(critical dependency chains),如 Easyperf 博客上的一篇帖子中所述。8
2. UICA - https://uica.uops.info/ ↩
3. LLVM MCA - https://llvm.org/docs/CommandGuide/llvm-mca.html ↩
4. uarch-bench - https://github.com/travisdowns/uarch-bench ↩
5. nanoBench - https://github.com/andreas-abel/nanoBench ↩
7. C++ 性能工具链接集合 - https://github.com/MattPD/cpplinks/blob/master/performance.tools.md#microarchitecture。 ↩
8. Easyperf 博客 - https://easyperf.net/blog/2022/05/11/Visualizing-Performance-Critical-Dependency-Chains ↩
9. 顺便说一句,可以先对a中的所有元素求和,然后在循环外将其乘以一次B。这是程序员的一个疏忽,但希望编译器将来能够处理它。 ↩