案例研究:四个基准测试的性能指标分析
为了将本章到目前为止讨论的所有内容整合在一起,让我们来看一些真实世界的例子。我们运行了来自不同领域的四个基准测试(benchmark)并计算了它们的性能指标。首先,让我们介绍这些基准测试。
- Blender 3.4 - 一款开源 3D 创作和建模软件项目。该测试使用 BMW27 blend 文件测试 Blender 的 Cycles 性能。使用所有硬件线程。URL:https://download.blender.org/release。命令行:
./blender -b bmw27_cpu.blend -noaudio --enable-autoexec -o output.test -x 1 -F JPEG -f 1。 - Stockfish 15 - 一款先进的开源国际象棋引擎。该测试使用 Stockfish 内置基准测试。使用单个硬件线程。URL:https://stockfishchess.org。命令行:
./stockfish bench 128 1 24 default depth。 - Clang 15 自构建 - 该测试使用 Clang 15 从源代码构建 Clang 15 编译器。使用所有硬件线程。URL:https://www.llvm.org。命令行:
ninja -j16 clang。 - CloverLeaf 2018 - 一个拉格朗日-欧拉(Lagrangian-Eulerian)流体动力学(hydrodynamics)基准测试。使用所有硬件线程。该测试使用 clover_bm.in 输入文件(Problem 5)。URL:http://uk-mac.github.io/CloverLeaf。命令行:
./clover_leaf。
在这次练习中,我在具有以下特性的机器上运行了全部四个基准测试:
- 第 12 代 Alder Lake Intel® Core™ i7-1260P CPU @ 2.10GHz(4.70GHz 睿频),4P+8E 核心,18MB L3 缓存
- 16 GB RAM,DDR4 @ 2400 MT/s
- 256GB NVMe PCIe M.2 SSD
- 64 位 Ubuntu 22.04.1 LTS(Jammy Jellyfish)
- Clang-15 C++ 编译器,编译选项:
-O3 -march=core-avx2
为了收集性能指标,我使用了 Andi Kleen 的 pmu-tools 中的 toplev.py 脚本:1
{% math_inline %} ~/workspace/pmu-tools/toplev.py -m --global --no-desc -v -- <app with args>
表 perf_metrics_case_study 提供了四个基准测试的性能指标并排比较。仅通过查看这些指标,我们就可以了解很多关于这些工作负载特性的信息。
| 指标名称 | 核心类型 | Blender | Stockfish | Clang15-自构建 | CloverLeaf |
|---|---|---|---|---|---|
| Instructions | P-core | 6.02E+12 | 6.59E+11 | 2.40E+13 | 1.06E+12 |
| Core Cycles | P-core | 4.31E+12 | 3.65E+11 | 3.78E+13 | 5.25E+12 |
| IPC | P-core | 1.40 | 1.80 | 0.64 | 0.20 |
| CPI | P-core | 0.72 | 0.55 | 1.57 | 4.96 |
| Instructions | E-core | 4.97E+12 | 0 | 1.43E+13 | 1.11E+12 |
| Core Cycles | E-core | 3.73E+12 | 0 | 3.19E+13 | 4.28E+12 |
| IPC | E-core | 1.33 | 0 | 0.45 | 0.26 |
| CPI | E-core | 0.75 | 0 | 2.23 | 3.85 |
| L1MPKI | P-core | 3.88 | 21.38 | 6.01 | 13.44 |
| L2MPKI | P-core | 0.15 | 1.67 | 1.09 | 3.58 |
| L3MPKI | P-core | 0.04 | 0.14 | 0.56 | 3.43 |
| Br. Misp. Ratio | P-core | 0.02 | 0.08 | 0.03 | 0.01 |
| Code stlb MPKI | P-core | 0 | 0.01 | 0.35 | 0.01 |
| Ld stlb MPKI | P-core | 0.08 | 0.04 | 0.51 | 0.03 |
| St stlb MPKI | P-core | 0 | 0.01 | 0.06 | 0.1 |
| LdMissLat (Clk) | P-core | 12.92 | 10.37 | 76.7 | 253.89 |
| ILP | P-core | 3.67 | 3.65 | 2.93 | 2.53 |
| MLP | P-core | 1.61 | 2.62 | 1.57 | 2.78 |
| Dram Bw (GB/s) | All | 1.58 | 1.42 | 10.67 | 24.57 |
| IpCall | All | 176.8 | 153.5 | 40.9 | 2,729 |
| IpBranch | All | 9.8 | 10.1 | 5.1 | 18.8 |
| IpLoad | All | 3.2 | 3.3 | 3.6 | 2.7 |
| IpStore | All | 7.2 | 7.7 | 5.9 | 22.0 |
| IpMispredict | All | 610.4 | 214.7 | 177.7 | 2,416 |
| IpFLOP | All | 1.1 | 1.82E+06 | 286,348 | 1.8 |
| IpArith | All | 4.5 | 7.96E+06 | 268,637 | 2.1 |
| IpArith Scal SP | All | 22.9 | 4.07E+09 | 280,583 | 2.60E+09 |
| IpArith Scal DP | All | 438.2 | 1.22E+07 | 4.65E+06 | 2.2 |
| IpArith AVX128 | All | 6.9 | 0.0 | 1.09E+10 | 1.62E+09 |
| IpArith AVX256 | All | 30.3 | 0.0 | 0.0 | 39.6 |
| IpSWPF | All | 90.2 | 2,565 | 105,933 | 172,348 |
表:四个基准测试的性能指标。
以下是我们可以对这些基准测试性能做出的假设:
Blender。工作负载在 P 核和 E 核之间分配相当均匀,两种核心类型的 IPC 都不错。每千条指令的缓存未命中次数相当低(见
L*MPKI)。分支预测错误是一个小瓶颈:Br. Misp. Ratio指标为2%;每610条指令有 1 次预测错误(见IpMispredict指标),这相当不错。TLB 不是瓶颈,因为 STLB 未命中非常罕见。由于缓存未命中次数很少,我们忽略Load Miss Latency指标。ILP 相当高。Golden Cove 是 6-wide 架构;ILP 为3.67意味着该算法每个周期利用了近2/3的核心资源。内存带宽需求较低(仅 1.58 GB/s),远未达到该机器的理论最大值。查看Ip*指标,可以判断 Blender 是一个浮点算法(见IpFLOP指标),其中很大一部分是向量化 FP 操作(见IpArith AVX128)。但也有部分算法是非向量化的标量 FP 单精度指令(IpArith Scal SP)。另外,注意每 90 条指令有一条显式软件内存预取指令(IpSWPF);我们预计可以在 Blender 的源代码中看到这些提示。初步结论:Blender 的性能受 FP 计算限制。Stockfish。我们使用单个硬件线程运行,因此 E 核上没有工作,正如预期的那样。L1 未命中次数相对较高,但大多数被 L2 和 L3 缓存所容纳。分支预测错误比率较高;每
215条指令就会受到一次预测错误惩罚。我们可以估计每215(指令)/ 1.80(IPC)= 120个周期发生一次预测错误,这非常频繁。与 Blender 的分析类似,我们可以说 TLB 和 DRAM 带宽对 Stockfish 不是问题。进一步来看,工作负载中几乎没有 FP 操作(见IpFLOP指标)。初步结论:Stockfish 是一个整数计算工作负载,受分支预测错误的严重影响。Clang 15 自构建。C++ 代码编译是性能分布非常平坦的任务之一,即没有大的热点。你会发现运行时间分布在许多不同的函数上。首先引起注意的是 P 核的工作量比 E 核多 68%,IPC 高出 42%。但 P 核和 E 核的 IPC 都很低。
L*MPKI指标乍看并不令人担忧;但结合加载未命中实际延迟(LdMissLat,以核心周期计),我们可以看到缓存未命中的平均代价相当高(约 77 个周期)。现在,当我们查看*STLB_MPKI指标时,会注意到与其他任何基准测试的显著差异。这是由于 Clang 编译器(以及其他编译器)的另一个特性:二进制文件相对较大(超过 100 MB)。代码不断跳转到远处位置,对 TLB 子系统造成高压力。可以看出,这个问题同时存在于指令(见Code stlb MPKI)和数据(见Ld stlb MPKI)方面。继续分析,DRAM 带宽使用量高于前两个基准测试,但仍未达到我们平台最大内存带宽的一半(约 34 GB/s)。另一个值得关注的问题是每次调用的指令数(IpCall)非常少:每次函数调用仅约 41 条指令。这不幸是编译器代码库的本质:它有数千个小函数。编译器需要更激进地内联(inline)所有这些函数和包装器。3 尽管如此,我们仍怀疑与函数调用相关的性能开销对 Clang 编译器来说仍然是一个问题。另外,可以注意到较高的ipBranch和IpMispredict指标。在 Clang 编译中,每五条指令就有一条是分支,每约 35 个分支中就有一个预测错误。几乎没有 FP 或向量指令,但这并不令人惊讶。初步结论:Clang 有大型代码库、平坦的性能分布、许多小函数和"多分支"的代码;性能受数据缓存未命中、TLB 未命中和分支预测错误的影响。CloverLeaf。与之前一样,我们从分析指令和核心周期开始。P 核和 E 核完成的工作量大致相同,但 P 核需要更多时间完成这些工作,导致 P 核上单个逻辑线程的 IPC 低于 E 核单个物理核心的 IPC。2
L*MPKI指标很高,特别是每千条指令的 L3 未命中次数。加载未命中延迟(LdMissLat)异常高,表明缓存未命中的平均代价极高。接下来,我们查看DRAM BW use指标,发现内存带宽消耗接近极限。这就是问题所在:系统中所有核心共享同一内存总线,因此它们竞争访问主内存,有效地阻塞了执行。CPU 得不到充足的数据供应。进一步来看,CloverLeaf 不受预测错误或函数调用开销的影响。指令组合以 FP 双精度标量操作为主,部分代码被向量化。初步结论:多线程 CloverLeaf 受内存带宽限制。
从这项研究可以看出,仅仅通过查看指标就可以了解程序行为的很多信息。它回答了"是什么?"的问题,但没有告诉你"为什么?"。为此,你需要收集性能概要(performance profile),我们将在后续章节中介绍。在本书的第二部分,我们将讨论如何缓解我们分析的四个基准测试中疑似存在的性能问题。
请记住,表 perf_metrics_case_study 中的性能指标摘要只告诉你程序的平均行为。例如,我们可能会看到 CloverLeaf 的 IPC 为 0.2,但实际上它可能从来都不以这样的 IPC 运行。相反,它可能有两个持续时间相等的阶段,一个以 0.1 的 IPC 运行,另一个以 0.3 的 IPC 运行。性能工具通过报告每个指标的统计数据以及平均值来解决这个问题。通常,了解最小值、最大值、第 95 百分位数和变化(标准差/均值)就足以理解分布情况。此外,一些工具允许绘制数据图,以便查看特定指标在程序运行期间如何变化。例如,图 CloverMetricCharts 展示了 CloverLeaf 基准测试的 IPC、L*MPKI、DRAM BW 和平均频率的动态变化。pmu-tools 包可以在添加 --xlsx 和 --xchart 选项后自动构建这些图表。-I 10000 选项以 10 秒间隔聚合收集的样本。
{% endmath_inline %} ~/workspace/pmu-tools/toplev.py -m --global --no-desc -v --xlsx workload.xlsx –xchart -I 10000 -- ./clover_leaf
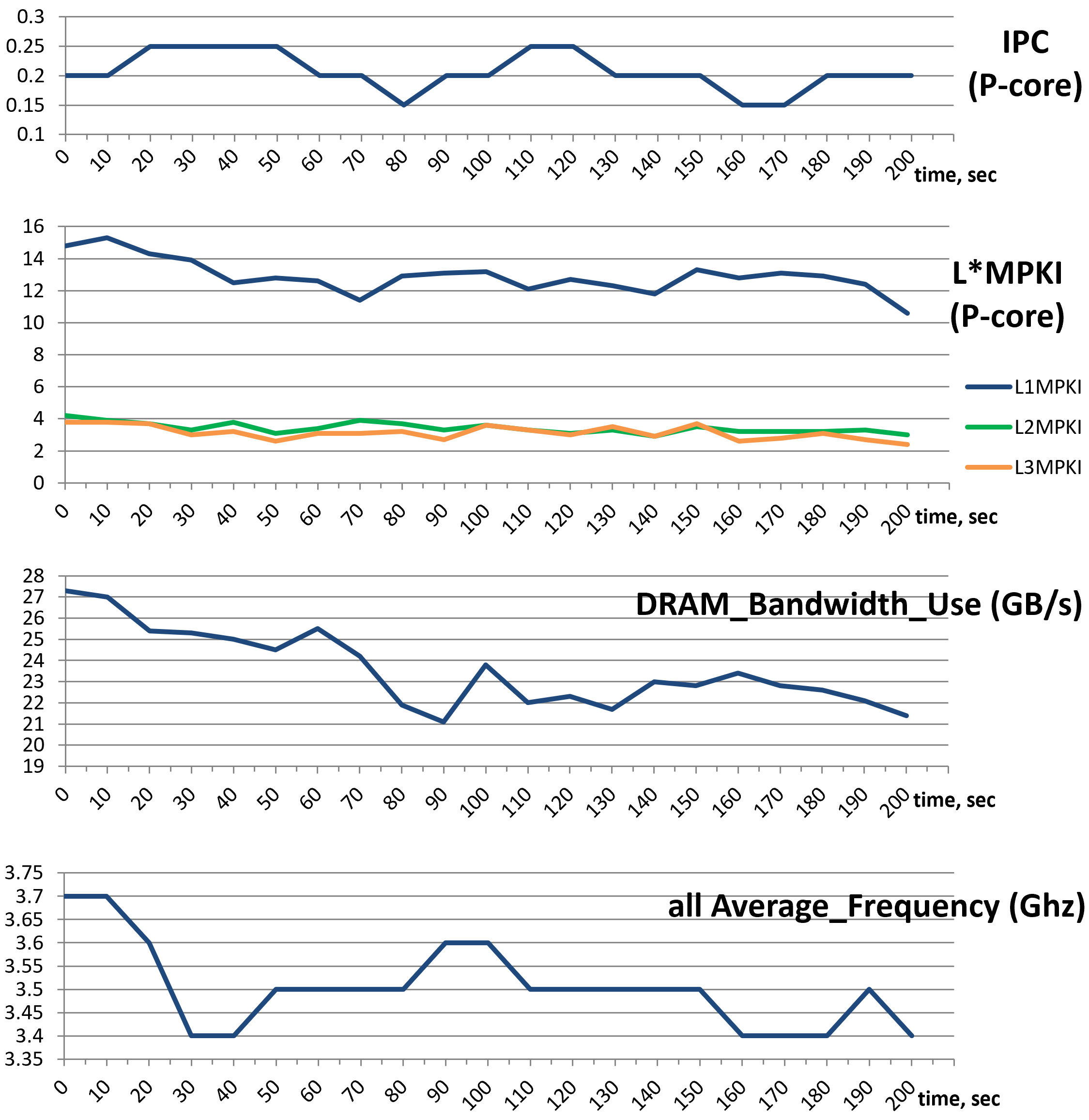
CloverLeaf 基准测试的性能指标图表,10 秒间隔。
尽管与摘要中报告的平均值的偏差并不太大,但我们可以看到工作负载并不稳定。查看 P 核的 IPC 图表后,我们可以假设工作负载中没有明显的阶段,变化是由性能事件多路复用(详见 [counting])引起的。然而,这只是一个需要被证实或证伪的假设。可能的后续步骤是通过以更高粒度运行收集来获取更多数据点(在我们的案例中为 10 秒)。绘制 L*MPKI 的图表表明所有三个指标都在其平均值附近波动,偏差不大。DRAM 带宽利用率图表显示存在对主内存压力不同的时段。最后一张图表显示了所有 CPU 核心的平均频率。从这张图表可以观察到,前 10 秒后开始出现降频(throttling)。我建议在仅根据汇总数据得出结论时要谨慎,因为汇总数据可能不能很好地反映工作负载行为。
请记住,收集性能指标并不能替代查看代码。始终尝试通过检查代码的相关部分来解释你看到的数字。
总之,性能指标帮助你建立关于程序中正在发生和没有发生什么的正确心智模型。在进一步分析中,这些数据将对你大有裨益。
1. pmu-tools - https://github.com/andikleen/pmu-tools ↩
2. 一种可能的解释是 CloverLeaf 非常受内存带宽限制。所有 P 核和 E 核都同样在等待内存时停顿。由于 P 核频率更高,它们浪费的 CPU 时钟比 E 核更多。 ↩
3. 也许可以使用链接时优化(LTO,Link Time Optimizations)。 ↩