附录 C. Intel 处理器追踪(Intel Processor Traces)
Intel 处理器追踪(Intel Processor Traces,PT)是一项 CPU 功能,它以高度压缩的二进制格式记录程序执行过程中的数据包,可用于重建每条指令的执行流程和时间戳。PT 的覆盖范围广、开销相对较小1,通常低于 5%。其主要用途是事后分析(postmortem analysis)和定位性能毛刺(performance glitches)的根本原因。
Workflow
与采样技术(sampling techniques)类似,PT 无需对源代码进行任何修改。收集追踪信息只需在支持 PT 的工具下运行程序即可。启用 PT 并启动基准测试后,分析工具开始将 PT 数据包写入 DRAM。
与 LBR(Last Branch Records,最后分支记录)类似,Intel PT 通过记录分支(branches)来工作。在运行时,每当 CPU 遇到任何分支指令时,PT 就会记录该分支的结果。对于简单的条件跳转指令,CPU 仅用 1 位来记录其是否发生跳转(T 表示跳转,NT 表示未跳转)。对于间接调用(indirect call),PT 会记录目标地址。注意,无条件分支(unconditional branches)因为目标地址可以静态确定而被忽略。
图 PT_encoding 展示了一段小指令序列的编码示例。PUSH、MOV、ADD 和 CMP 等指令因不改变控制流而被忽略。但 JE 指令可能跳转到 .label,因此需要记录其结果。之后还有一个间接调用,其目标地址会被保存。
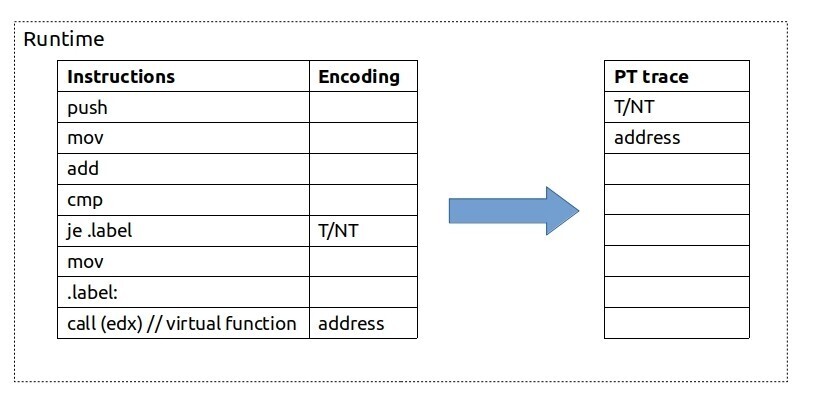
Intel Processor Traces encoding
在分析阶段,我们将应用程序二进制文件与收集到的 PT 追踪数据结合起来。软件解码器需要应用程序的二进制文件来重建程序的执行流程。它从程序入口点开始,将收集到的追踪数据作为查找参考来确定控制流。
图 PT_decoding 展示了解码 Intel 处理器追踪的示例。假设 PUSH 指令是应用程序二进制文件的入口点,则 PUSH、MOV、ADD 和 CMP 会被原样重建,无需查阅已编码的追踪数据。之后软件解码器遇到 JE 指令——这是一个条件分支,需要查找其结果。根据图 PT_decoding 中的追踪数据,JE 发生了跳转(T),因此跳过下一条 MOV 指令,转到 CALL 指令。同样,CALL(edx) 是改变控制流的指令,需要在已编码追踪中查找目标地址,即 0x407e1d8。
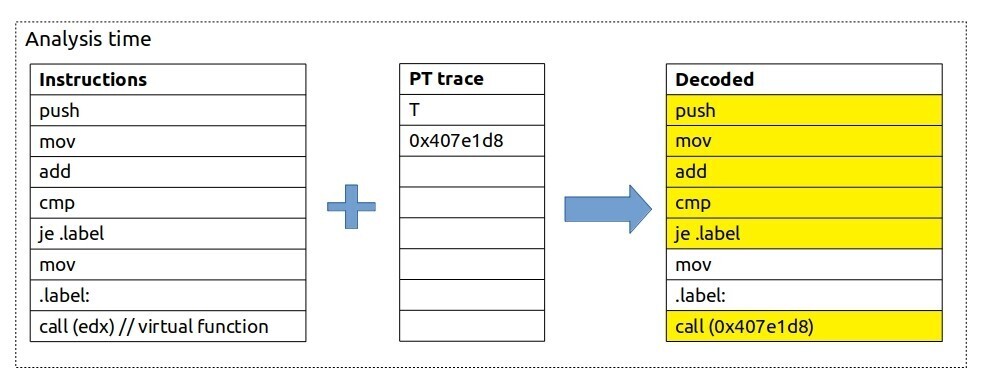
Intel Processor Traces decoding
黄色高亮的指令是程序运行时实际执行的指令。注意,这是对程序执行的精确重建,没有跳过任何指令。之后可以利用调试信息将汇编指令映射回源代码,从而获得逐行执行的源代码日志。
Timing Packets
借助 Intel PT,不仅可以追踪执行流程,还可以追踪时序信息(timing information)。除了保存跳转目标,PT 还可以发出时序数据包(timing packets)。图 PT_timings 展示了如何利用时序数据包为指令恢复时间戳。与前面的示例类似,首先看到 JNZ 未发生跳转(NT),因此将其及其上方的所有指令的时间戳更新为 0ns。接着看到 2ns 的时序更新,以及 JE 发生跳转,因此将 JE 及其上方(JNZ 下方)的所有指令时间戳更新为 2ns。之后有一个间接调用(CALL(edx)),但没有附带时序数据包,因此不更新时间戳。然后看到经过了 100ns,JB 未发生跳转,因此将其上方的所有指令时间戳更新为 102ns。
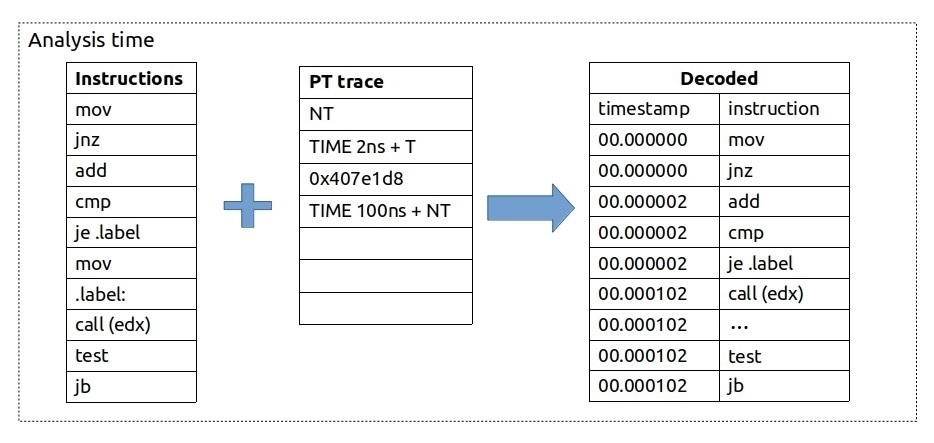
Intel Processor Traces timings
图 PT_timings 所示示例中,指令数据(控制流)是完全精确的,但时序信息精度稍低。显然,CALL(edx)、TEST 和 JB 指令并非同时发生,但我们没有更精确的时序信息。时间戳使我们能够将程序的时间区间与系统中的其他事件对齐,并且便于与挂钟时间(wall clock time)进行比较。某些实现中可以通过周期精确模式(cycle-accurate mode)进一步提升追踪时序精度,该模式下硬件会记录相邻正常数据包之间的时钟周期数(详见 [IntelOptimizationManual])。
Collecting and Decoding Traces
使用 Linux perf 工具可以轻松收集 Intel PT 追踪数据:
{% math_inline %} perf record -e intel_pt/cyc=1/u -- ./a.out
上述命令行中,我要求 PT 机制每个时钟周期更新一次时序信息。但这可能不会大幅提升精度,因为时序数据包只有在与另一个控制流数据包配对时才会发送。
收集完成后,可通过以下命令获取原始 PT 追踪数据:
{% endmath_inline %} perf report -D > trace.dump
PT 最多捆绑 6 个条件分支后才发出一个时序数据包。自 Intel Skylake CPU 架构起,时序数据包包含自上一个数据包以来经过的时钟周期数。查看 trace.dump,可能会看到如下内容:
000073b3: 2d 98 8c TIP 0x8c98 // target address (IP)
000073b6: 13 CYC 0x2 // timing update
000073b7: c0 TNT TNNNNN (6) // 6 conditional branches
000073b8: 43 CYC 0x8 // 8 cycles passed
000073b9: b6 TNT NTTNTT (6)
上述原始 PT 数据包对于性能分析用处不大。要将处理器追踪解码为人类可读的形式,可以执行:
$ perf script --ns --itrace=i1t -F time,srcline,insn,srccode
以下是解码后追踪数据的示例:
timestamp srcline instruction srccode
...
253.555413143: a.cpp:24 call 0x35c foo(arr, j);
253.555413143: b.cpp:7 test esi, esi for (int i = 0; i <= n; i++)
253.555413508: b.cpp:7 js 0x1e
253.555413508: b.cpp:7 movsxd rsi, esi
...
这里只展示了长执行日志中的一小片段。在这份日志中,我们拥有程序运行时每条已执行指令的追踪信息,可以逐步观察程序所做的每一步操作。这是进行功能分析和性能分析的强有力基础。
Use Cases
- 分析性能毛刺:由于 PT 捕获了完整的指令流,可以分析应用程序在无响应的短暂时间内发生了什么。更详细的示例可以在 Easyperf 博客的文章2中找到。
- 事后调试(Postmortem debugging):PT 追踪数据可以被
gdb等传统调试器重放。此外,PT 提供调用栈(call stack)信息,即便调用栈损坏也始终有效。3 PT 追踪数据可以在远程机器上一次性收集,然后离线分析。这在问题难以复现或系统访问受限时尤为有用。 - 内省程序执行过程:
- 可以立即判断某条代码路径是否从未被执行。
- 借助时间戳,可以计算在自旋锁(spin lock)等待尝试期间花费了多少时间等。
- 通过检测特定指令模式进行安全防护。
Disk Space and Decoding Time
即使考虑到追踪数据的压缩格式,已编码数据仍可能占用大量磁盘空间。通常每条指令不足 1 字节,但考虑到 CPU 执行指令的速度,这仍然相当可观。根据工作负载的不同,CPU 以 100 MB/s 的速度编码 PT 数据是很常见的。解码后的追踪数据量可能达到其十倍之多(约 1 GB/s)。这使得 PT 不适合用于长时间运行的工作负载。但对于短时间运行来说是可行的,即便是大型工作负载也可以。在这种情况下,用户可以在毛刺发生期间临时附加到运行中的进程。或者使用循环缓冲区(circular buffer),新追踪数据会覆盖旧数据,即始终保留最近约 10 秒的追踪数据。
用户还可以通过多种方式进一步限制收集范围:可以仅收集用户态/内核态代码的追踪数据;还有地址范围过滤器(address range filter),可以动态选择进入或退出追踪,以限制内存带宽占用。这样就可以仅追踪单个函数甚至单个循环。
解码 PT 追踪数据可能需要较长时间,因为它必须跟随二进制文件的反汇编指令并重建执行流程。在 Intel Core i5-8259U 机器上,对于运行 7 毫秒的工作负载,编码后的 PT 追踪数据约占 1 MB 磁盘空间。使用 perf script -F time,ip,sym,symoff,insn 解码该追踪数据需要约 20 秒4,输出结果占用约 1.3 GB 磁盘空间。
Tools
除 Linux perf 外,还有其他几款工具支持 Intel PT。首先,Intel VTune Profiler 有使用 Intel PT 的异常检测(Anomaly Detection)分析类型。另一款值得一提的流行工具是 magic-trace5,可收集并显示进程的高分辨率追踪数据。
Intel PT References and links
- Intel® 64 and IA-32 Architectures Software Developer Manuals [IntelOptimizationManual].
- Whitepaper "Hardware-assisted instruction profiling and latency detection" [IntelPTPaper].
- Andi Kleen article on LWN, URL: https://lwn.net/Articles/648154.
- Intel PT Micro Tutorial, URL: https://sites.google.com/site/intelptmicrotutorial/.
- Intel PT documentation in the Linux kernel, URL: https://github.com/torvalds/linux/blob/master/tools/perf/Documentation/intel-pt.txt.
- Cheatsheet for Intel Processor Trace, URL: http://halobates.de/blog/p/410.
1. See more information about Intel PT overhead in [IntelPTPaper]. ↩
2. Analyze performance glitches with Intel PT - https://easyperf.net/blog/2019/09/06/Intel-PT-part3 ↩
3. Postmortem debugging with Intel PT - https://easyperf.net/blog/2019/08/30/Intel-PT-part2 ↩
4. When you decode traces withperf script -Fwith+srclineor+srccodeto emit source code, it gets even slower. ↩
5. magic-trace - https://github.com/janestreet/magic-trace ↩
6. Notice that there are instructions executed as a result of the function call (denoted with ...). ↩