缓存一致性
多处理器系统包含确保每个核心在共享内存使用期间数据一致性的机制,每个核心包含其自己的独立缓存实体。如果没有这样的协议,如果 CPU A 和 B 都将内存位置 L 读入各自的缓存,而 CPU B 随后修改了其缓存中 L 的值,那么 CPU 将拥有同一内存位置 L 的不一致值。缓存一致性协议(Cache Coherency Protocols)确保对缓存条目的任何更新都会在同一位置的任何其他缓存条目中被适当更新或失效。
缓存一致性协议
最广为人知的缓存一致性协议之一是 MESI(Modified Exclusive Shared Invalid),它被用于支持现代 CPU 中使用的写回缓存(writeback caches)。其首字母缩写表示可以标记缓存行的四种状态(见图 MESI):
- 已修改(Modified):缓存行仅存在于当前缓存中,并且已从其 RAM 中的值被修改
- 独占(Exclusive):缓存行仅存在于当前缓存中,并且与其 RAM 中的值匹配
- 共享(Shared):缓存行存在于此处以及其他缓存行中,并且与其 RAM 中的值匹配
- 无效(Invalid):缓存行未使用(即不包含任何 RAM 位置)
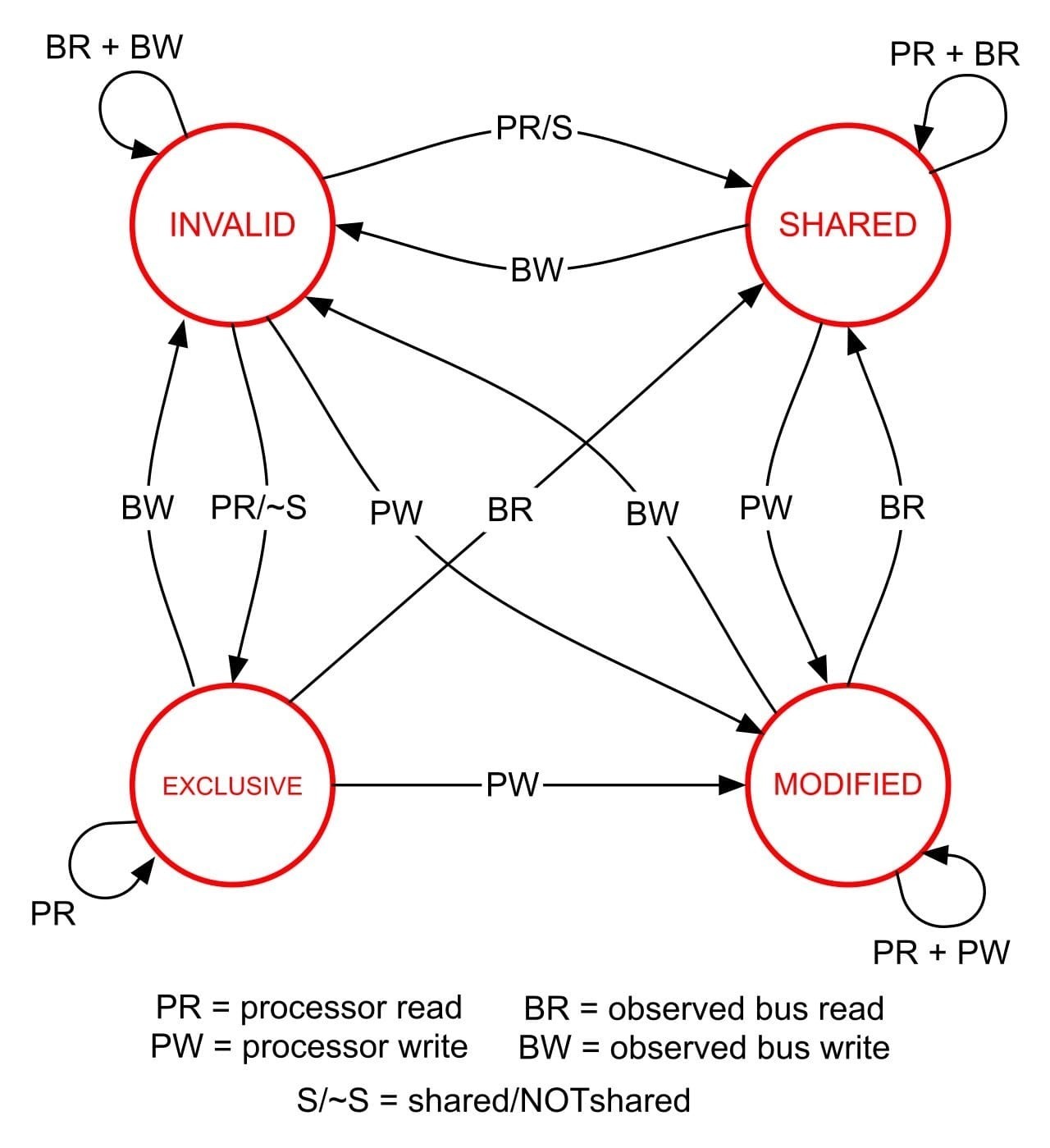
MESI 状态图。© 来源:华盛顿大学,via courses.cs.washington.edu。
从内存中获取时,每个缓存行都有一个编码到其标记中的状态。然后缓存行状态不断从一种状态转变到另一种状态。25 实际上,CPU 供应商通常实现 MESI 的略微改进变体。例如,Intel 使用 MESIF,26它添加了一个转发(Forwarding,F)状态,而 AMD 采用 MOESI,27它添加了所有权(Owning,O)状态。然而,这些协议仍然保持了基础 MESI 协议的本质。
缺乏缓存一致性可能导致顺序不一致的程序。这个问题可以通过让侦听(snoop)缓存监视所有内存事务并相互协作来维护内存一致性来缓解。不幸的是,这是有代价的,因为一个核心所做的修改会使另一个核心缓存中对应的缓存行失效。这会导致内存停顿并浪费系统带宽。与只能给应用程序性能设置上限的序列化和锁定问题相比,一致性问题可能如 [secAmdahl] 中 USL 所解释的那样,导致倒退效应。两种广为人知的一致性问题类型是真共享(true sharing)和假共享(false sharing),我们接下来将探讨这两种问题。
真共享
真共享发生在两个不同核心访问同一个变量时(见代码清单 TrueSharing)。
代码清单:真共享示例。
unsigned int sum; // 在所有线程之间共享
{ // 线程 A 执行的代码 │ { // 线程 B 执行的代码
for (int i = 0; i < N; i++) │ for (int i = 0; i < N; i++)
sum += a[i]; │ sum += b[i];
} │ }
首先,除了真共享之外,我们还有一个更大的问题。我们实际上存在数据竞争(data race),有时很难检测到。注意,我们没有适当的同步机制,这可能导致不可预测或不正确的程序行为,因为对共享数据的操作可能相互干扰。幸运的是,有工具可以帮助识别此类问题。来自 Clang 的线程检查器30(Thread sanitizer)和 helgrind31 就是这类工具。为了防止代码清单 TrueSharing 中的数据竞争,你应该将 sum 变量声明为 std::atomic<unsigned int> sum。
使用 C++ 原子操作可以帮助解决真共享发生时的数据竞争问题。然而,它有效地序列化了对原子变量的访问,这可能会损害性能。解决真共享问题的更好方法是使用线程本地存储(Thread Local Storage,TLS)。TLS 是一种方法,允许给定多线程进程中的每个线程分配内存来存储线程特定的数据。这样,线程修改其本地副本,而不是竞争全局可用的内存位置。代码清单 TrueSharing 中的示例可以通过使用 TLS 类说明符声明 sum 来修复:thread_local unsigned int sum(自 C++11 起)。主线程然后应合并每个工作线程的所有本地副本的结果。
假共享
如果不小心,你可能会尝试如代码清单 FalseSharing 所示解决真共享问题。这个解决方案引入了另一个问题:假共享(false sharing)。它发生在两个不同核心修改恰好驻留在同一缓存行上的不同变量时。在代码清单 FalseSharing 所示的代码示例中,即使线程 A 和 B 更新结构 S 的不同字段,它们很可能驻留在同一缓存行上,这将触发假共享问题。图 FalseSharing 说明了这个问题。
代码清单:假共享示例。
struct S {
int sumA; // sumA 和 sumB 很可能
int sumB; // 驻留在同一缓存行中
};
S s;
{ // 线程 A 执行的代码 │ { // 线程 B 执行的代码
for (int i = 0; i < N; i++) │ for (int i = 0; i < N; i++)
s.sumA += a[i]; │ s.sumB += b[i];
} │ }
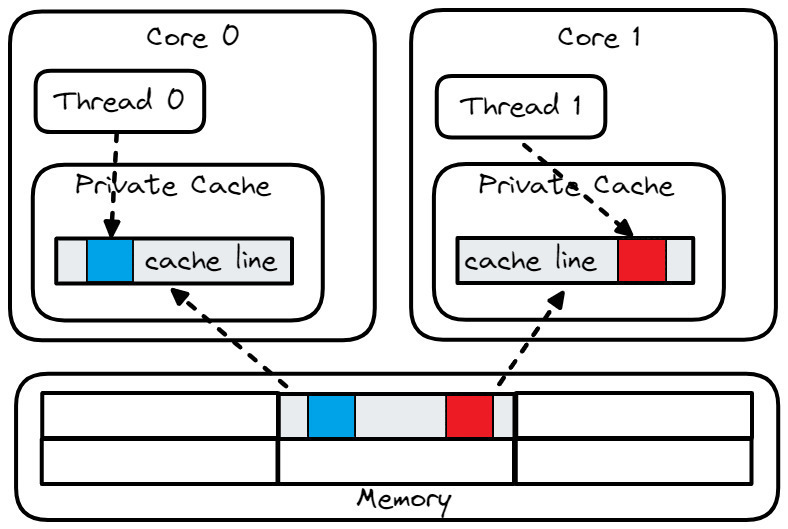
假共享:两个线程访问同一缓存行。
假共享是多线程应用程序性能问题的频繁来源。因此,现代分析工具内置了对检测此类情况的支持。对于遇到真共享/假共享的应用程序,TMA 可能会显示较高的 Memory Bound → L3 Bound → Contested Accesses 指标。18
使用 Intel VTune Profiler 时,我建议运行两种类型的分析来查找和消除假共享问题。首先,运行实现 TMA 方法的微架构探索(Microarchitecture Exploration)分析,以检测应用程序中假共享的存在。如前所述,Contested Accesses 指标的高值提示我们需要深入挖掘,并运行启用分析动态内存对象复选框的内存访问(Memory Access)分析。此分析有助于找出导致竞争问题的数据结构的内存访问。通常,此类内存访问具有较高延迟,分析将揭示这一点。请参阅 Intel Developer Zone 中使用 Intel VTune Profiler 修复假共享问题的示例。20
Linux perf 也支持查找假共享。与 Intel VTune 分析器一样,首先运行 TMA(见 [secTMA_Intel])以查明程序是否遇到假共享/真共享问题。如果是这种情况,使用 perf c2c 工具检测具有高缓存一致性成本的内存访问。perf c2c 匹配不同线程的存储/加载地址,并检查是否在已修改缓存行中发生命中。读者可以在专门的博客文章中找到该过程的详细说明和工具使用方法。21
可以通过对内存对象进行对齐/填充来消除假共享。[secTrueSharing] 中的示例可以通过确保 sumA 和 sumB 不共享同一缓存行来修复,如代码清单 PadFalseSharing 所示。32
代码清单:数据填充以避免假共享。
constexpr int CacheLineAlign = 64;
struct S { struct S {
int sumA; => int sumA;
int sumB; alignas(CacheLineAlign) int sumB;
}; };
假共享不仅可以在 C 和 C++ 等原生语言中观察到,也可以在 Java 和 C# 等托管语言中观察到。从一般性能角度来看,最重要的考虑因素是可能的状态转换成本。在所有缓存状态中,唯一在 CPU 读/写操作期间不涉及代价高昂的跨缓存子系统通信和数据传输的状态是已修改(M)和独占(E)状态。因此,缓存行保持 M 或 E 状态的时间越长(即跨缓存的数据共享越少),多线程应用程序所产生的一致性成本就越低。可以在 Nitsan Wakart 的博客文章"深入缓存一致性"中找到演示如何利用此属性的示例。28
18. 有关 Contested Accesses 指标的说明,请参阅 Intel VTune 用户指南。 ↩
20. VTune cookbook: false-sharing - https://software.intel.com/en-us/vtune-cookbook-false-sharing. ↩
21. An article on perf c2c - https://joemario.github.io/blog/2016/09/01/c2c-blog/. ↩
25. 有一个 MESI 协议的动画演示 - https://www.scss.tcd.ie/Jeremy.Jones/vivio/caches/MESI.htm. ↩
26. MESIF - https://en.wikipedia.org/wiki/MESIF_protocol ↩
27. MOESI - https://en.wikipedia.org/wiki/MOESI_protocol ↩
28. Blog post "Diving Deeper into Cache Coherency" - http://psy-lob-saw.blogspot.com/2013/09/diving-deeper-into-cache-coherency.html ↩
30. Clang's thread sanitizer tool: https://clang.llvm.org/docs/ThreadSanitizer.html. ↩
31. Helgrind, a thread error detector tool: https://www.valgrind.org/docs/manual/hg-manual.html. ↩
32. 不要将缓存行的大小视为常数。例如,在 Apple M1、M2 及以后的处理器中,L2 缓存以 128B 缓存行运行。 ↩