配置文件引导优化(Profile Guided Optimizations)
编译程序并生成最优汇编代码完全依赖于启发式方法(heuristics)。代码变换算法有许多边界情况,旨在针对特定情况实现最优性能。对于编译器做出的许多决策,它会尝试基于一些典型情况猜测最佳选择。例如,在决定是否应该内联某个特定函数时,编译器可能会考虑该函数将被调用的次数。问题在于编译器事先并不知道这一点,它需要先运行程序才能知道。在没有任何运行时信息的情况下,编译器只能猜测。
这时性能分析信息就派上用场了。有了性能分析信息,编译器可以做出更好的优化决策。大多数编译器中都有一组变换,可以根据提供给它们的性能分析数据来调整算法。这组变换被称为配置文件引导优化(Profile Guided Optimizations,PGO)。当性能分析数据可用时,编译器可以使用它来指导优化;否则,它将回退到使用其标准算法和启发式方法。在文献中,有时也能看到反馈导向优化(Feedback Directed Optimizations,FDO)这一术语,与 PGO 含义相同。
图 PGO_flow 展示了使用 PGO 的传统工作流程,也称为插桩 PGO(instrumented PGO)。首先,你编译程序并告知编译器自动插桩代码。这将在函数中插入一些记录代码以收集运行时统计信息。第二步是使用代表应用程序典型工作负载的输入数据运行插桩后的二进制文件。这将生成性能分析数据,即一个包含运行时统计信息的新文件。这是一个原始转储文件,包含有关函数调用计数、循环迭代计数和其他基本块命中计数的信息。此工作流程的最后一步是使用性能分析数据重新编译程序,以生成优化后的可执行文件。
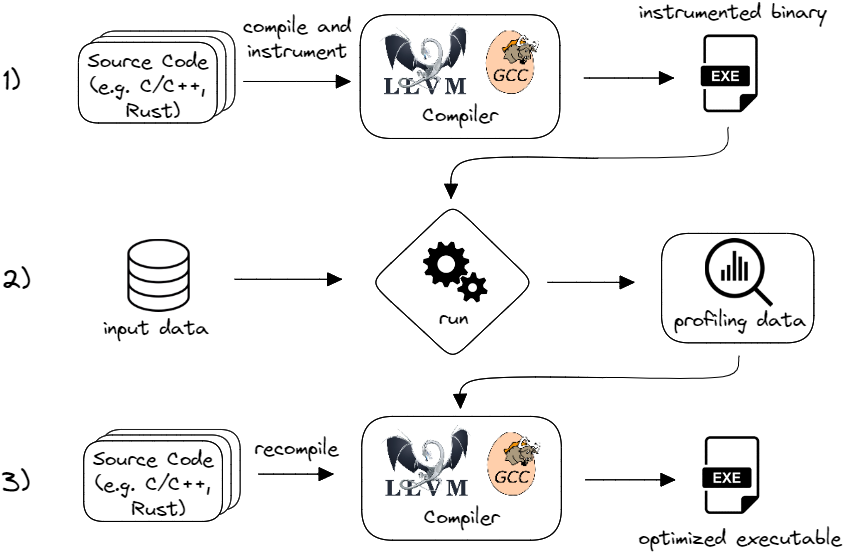
插桩 PGO 工作流程。
开发者可以在 LLVM 编译器中通过使用 -fprofile-instr-generate 选项构建程序来启用 PGO 插桩(步骤 1)。这将指示编译器添加插桩代码,以在运行时收集性能分析信息。此类信息通常包括程序中每个基本块被进入的次数。
之后,LLVM 编译器可以使用 -fprofile-instr-use 选项消费性能分析数据,重新编译程序并输出经过 PGO 调优的二进制文件。在 Clang 中使用 PGO 的指南在文档中有描述。7 GCC 编译器使用不同的选项集:-fprofile-generate 和 -fprofile-use,如文档所述。10
PGO 帮助编译器改进函数内联、代码放置、寄存器分配和其他代码变换。PGO 主要用于代码量庞大的项目,例如 Linux 内核、编译器、数据库、网络浏览器、视频游戏、生产力工具等。对于拥有数百万行代码的应用程序,这是改善机器码布局的唯一实用方法。
并非所有工作负载都能从 PGO 中受益。前端瓶颈严重的工作负载使用 PGO 可能获得高达 30% 的加速。然而,计算密集型工作负载(如科学计算)可能根本看不到任何收益。
虽然一些软件项目已将插桩 PGO 作为其构建过程的一部分,但采用率仍然很低。原因有几点。主要原因是插桩可执行文件的巨大运行时开销。运行插桩二进制文件并收集性能分析数据通常会导致 5-10 倍的性能下降,这使构建步骤更长,并阻碍了直接从生产系统(无论是客户端设备还是云端)收集分析数据。遗憾的是,你无法只收集一次性能分析数据并将其用于所有未来的构建。随着应用程序源代码的演进,分析数据会变得过时(不同步),需要重新收集。
PGO 流程的另一个注意事项是,编译器应该仅使用能代表应用程序使用方式的典型场景进行训练。否则,你可能最终会降低程序的性能。编译器会"盲目地"使用你提供的分析数据,假定程序无论输入数据如何都始终表现相同。PGO 用户应仔细选择用于收集性能分析数据(步骤 2)的输入数据,因为在改善应用程序的一个使用场景的同时,可能会使其他场景变差。幸运的是,并不必须只有一个工作负载,来自不同工作负载的性能分析数据可以合并,以代表应用程序的多个使用场景。
2016 年,Google 率先推出了基于采样的 PGO 替代方案。[AutoFDO] 无需对代码进行插桩,性能分析数据可以从 Linux perf 等标准分析工具的输出中获取。Google 开发了一个名为 AutoFDO8 的开源工具,可将 Linux perf 生成的采样数据转换为 GCC 和 LLVM 等编译器能够理解的格式。
这种方法比插桩 PGO 有几个优点。首先,它从 PGO 构建工作流程中省去了一个步骤,即步骤 1,因为不需要构建插桩二进制文件。其次,性能分析数据收集运行在已优化的二进制文件上,因此运行时开销要低得多。这使得在生产环境中长时间收集性能分析数据成为可能。由于这种方法基于硬件收集,它还支持插桩 PGO 无法实现的新型优化。一个例子是分支转条件移动(branch-to-cmov)转换,这是一种将条件跳转替换为条件移动的变换,以避免分支预测错误的开销(参见 [BranchlessSelection])。为了有效地执行此变换,编译器需要知道原始分支被错误预测的频率。这些信息在现代 CPU(Intel Skylake+)上可通过基于采样的 PGO 获取。
2018 年中期,Meta 开源了其二进制优化工具 BOLT9,该工具作用于已编译的二进制文件。它首先反汇编代码,然后使用 Linux perf 等采样分析器收集的性能分析信息进行各种布局变换,最后重新链接二进制文件。[BOLT] 截至今日,BOLT 拥有超过 15 个优化 pass,包括基本块重排、函数拆分和重排等。与传统 PGO 类似,BOLT 优化的主要候选对象是受指令缓存和 ITLB 缺失影响的程序。自 2022 年 1 月起,BOLT 已成为 LLVM 项目的一部分,作为独立工具提供。
在 BOLT 推出几年后,Google 开源了其二进制重链接工具 Propeller。它的用途相似,但它不是反汇编原始二进制文件,而是依赖链接器输入,因此可以分布在多台机器上,以实现更好的扩展性和更低的内存消耗。BOLT 和 Propeller 等后链接优化器可以与传统 PGO(以及链接时优化,LTO)结合使用,通常能额外提供 5-10% 的性能提升。这些技术开启了基于硬件遥测的新型二进制重写优化方式。
7. Clang 中的 PGO - https://clang.llvm.org/docs/UsersManual.html#profiling-with-instrumentation ↩
8. AutoFDO - https://github.com/google/autofdo ↩
9. BOLT - https://code.fb.com/data-infrastructure/accelerate-large-scale-applications-with-bolt/ ↩
10. GCC 中的 PGO - https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html#Optimize-Options ↩