手动性能测试
在上一节中,我们讨论了 CI 系统如何帮助评估代码变更的性能影响。然而,由于硬件不可用、测试基础设施搭建过于复杂、需要收集额外指标等原因,并不总能利用此类系统。本节为本地性能评估提供基本建议。
我们通常通过以下步骤来测量代码变更的性能影响:1)测量基线(baseline)性能;2)测量修改后程序的性能;3)将两者进行比较。例如,我们有一个递归计算斐波那契数列的程序(基线),并决定用循环重写它(修改后版本)。两个版本在功能上都是正确的,且产生相同的斐波那契数。现在我们需要比较两个版本的性能。
强烈建议不要仅进行一次测量,而是多次运行基准测试。如果仅基于单次测量进行比较,就会增加数字被测量偏差(在 [secFairExperiments] 中讨论过)所扭曲的风险。因此,我们为基线程序收集了 N 次性能测量,为修改后版本也收集了 N 次。我们将一组性能测量数据称为性能分布(performance distribution)。现在我们需要聚合并比较这两个分布,以决定哪个版本的程序更快。
比较两个性能分布最直接的方法是取两个分布各 N 次测量的平均值,然后计算比率。对于本书中讨论的代码改进类型,这种简单方法在大多数情况下效果很好。然而,比较性能分布相当微妙,有很多方法会让你被测量数据所欺骗并得出错误结论。本书不涉及统计分析的细节,建议你阅读相关教材。对于性能工程师来说,Dror G. Feitelson 的《计算机系统性能评估的工作负载建模》("Workload Modeling for Computer Systems Performance Evaluation")12 是一个很好的参考,其中包含有关模态分布、偏度等相关主题的更多信息。
数据科学家通常通过绘图来呈现测量数据,这消除了有偏见的结论,并允许读者自行解读数据。一种流行的分布绘图方法是使用箱线图(box plot,也称为箱须图)。在图 BoxPlot 中,我们将同一功能程序的两个版本("变更前"和"变更后")的性能分布可视化。每个分布中有 70 个性能数据点。
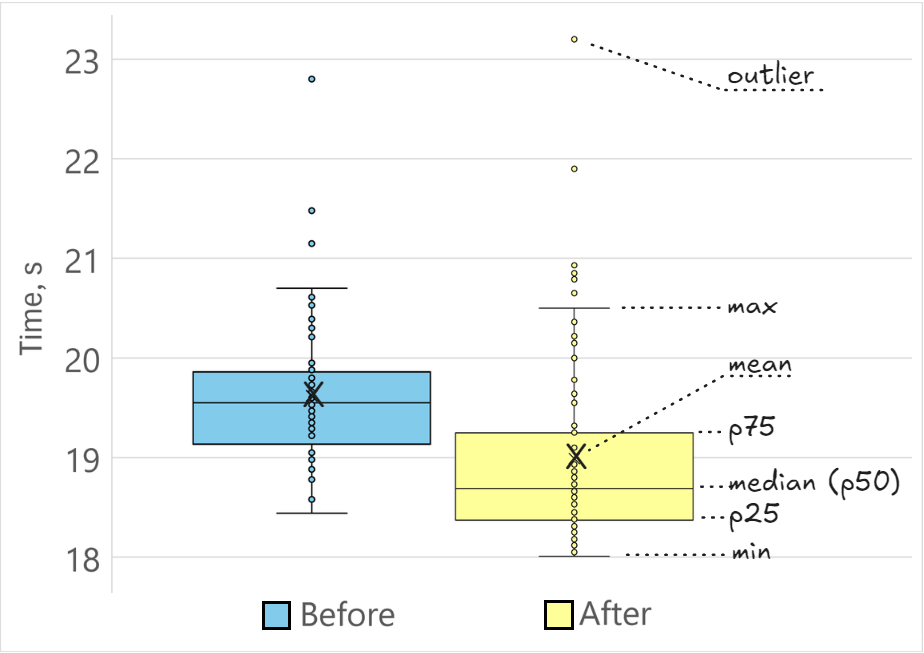
以箱线图形式呈现的程序"变更前"和"变更后"两个版本的性能测量数据(越低越好)。
让我们描述图中所示的术语:
- 均值(mean)(通常称为平均值,average)是数据集中所有值之和除以值的数量。用 X 标示。
- 中位数(median) 是数据集排序后的中间值,与第 50 百分位数(p50)相同。
- 第 25 百分位数(p25) 将最低 25% 的数据与最高 75% 的数据分开。
- 第 75 百分位数(p75) 将最低 75% 的数据与最高 25% 的数据分开。
- 异常值(outlier) 是数据集中与其他样本差异显著的数据点。异常值可能由数据中的变异性或实验误差引起。
- 最小值和最大值(min 和 max)(须线,whiskers)代表不被视为异常值的最极端数据点。
通过查看图 BoxPlot 中的箱线图,我们可以感受到代码变更对性能有积极影响,因为"变更后"的样本通常比"变更前"更快。然而,也存在一些"变更前"的测量结果比"变更后"更快。箱线图允许在同一图表上对多个分布进行比较。使用箱线图可视化性能分布的好处在 Stefan Marr 的一篇博客文章中有详细描述。13
性能加速比可以通过取两个均值的比率来计算。在某些情况下,你可以使用其他指标来计算加速比,包括中位数、最小值和第 95 百分位数,具体取决于哪个指标对你的分布更具代表性。
标准差(standard deviation) 量化了数据集中的值平均偏离均值的程度。低标准差表示数据点接近均值,而高标准差表示数据点分布在更宽的范围内。除非分布具有低标准差,否则不要计算加速比。如果测量数据的标准差与均值处于同一数量级,则平均值不是一个具有代表性的指标。考虑采取措施减少测量中的噪声。如果做不到,则以均值、中位数、标准差、百分位数、最小值、最大值等关键指标的组合来呈现结果。
性能提升通常以两种方式表示:加速比(speedup factor)或百分比提升。如果一个程序最初需要 10 秒运行,你优化到 1 秒,那就是 10 倍加速。我们从原始程序运行时间中节省了 9 秒,时间减少了 90%。计算百分比提升的公式如下所示。本书将同时使用两种方式表示加速比。
计算准确加速比的最重要因素之一是收集丰富的样本集,即多次运行基准测试。这听起来显而易见,但并不总是可行的。例如,SPEC CPU 2017 基准测试1 中的某些测试在现代机器上运行超过 10 分钟。这意味着只需产生 3 个样本就需要 1 小时:每个版本的程序各 30 分钟。想象一下,你的套件中不是只有一个基准测试,而是数百个。即使将工作分发到多台机器上,收集统计上足够的数据也会变得非常昂贵。
如果获取新测量值的成本很高,不要急于收集大量样本。通常,仅从三次运行中就能学到很多。如果你看到这三个样本之间的标准差非常低,收集更多测量值可能不会带来新信息。这对于具有潜在一致性的程序(例如静态基准测试)来说非常典型。然而,如果你看到异常高的标准差,我不建议启动新的运行,寄希望于"更好的统计数据"。你应该弄清楚是什么导致了性能差异以及如何减少它。
在自动化环境中,你可以根据标准差动态限制基准测试迭代次数来实施自适应策略,即持续收集样本直到标准差处于特定范围内。分布中的标准差越低,所需的样本数量就越少。一旦标准差低于阈值,你可以停止收集测量数据。这种策略在 [Akinshin2019] 中有更详细的说明。
需要注意的一个重要事项是异常值的存在。可以丢弃某些样本(例如,冷启动运行),但不要故意从测量集中丢弃不需要的样本。对于某些类型的基准测试,异常值可能是最重要的指标之一。例如,当对具有实时约束的软件进行基准测试时,第 99 百分位数可能非常有意义。
我建议使用基准测试工具,因为它们能自动化性能测量。例如,Hyperfine4 是一款流行的跨平台命令行基准测试工具,它能自动确定运行次数,并可将结果可视化为包含均值、最小值、最大值的表格,或箱线图。
在接下来的两节中,我们将讨论如何测量挂钟时间(wall clock time,即延迟),这是最常见的情况。然而,有时我们也可能想要测量其他内容,例如每秒请求数(吞吐量)、堆分配、上下文切换等。
1. SPEC CPU 2017 基准测试 - http://spec.org/cpu2017/Docs/overview.html#benchmarks ↩
12. "计算机系统性能评估的工作负载建模" - https://www.cs.huji.ac.il/~feit/wlmod/ ↩
13. Stefan Marr 关于箱线图的博客文章 - https://stefan-marr.de/2024/06/5-reasons-for-box-plots-as-default/ ↩
4. hyperfine - https://github.com/sharkdp/hyperfine ↩