数据依赖(Data Dependencies)
当一条程序语句引用前一条语句的输出时,我们称这两条语句之间存在数据依赖。有时人们也使用依赖链(dependency chain)或数据流依赖(data flow dependencies)等术语。我们最熟悉的例子是遍历链表(见图 LinkedListChasing)。要访问节点 N+1,必须先解引用指针 N->next。对于右侧的循环,这是一种循环(recurrent)数据依赖,意味着它跨越了循环的多次迭代。遍历链表就是一条非常长的依赖链。

遍历链表时的数据依赖
传统程序是基于顺序执行模型(sequential execution model)编写的。在该模型下,指令按照程序指定的顺序依次、原子地执行。然而,正如我们已知的,现代 CPU 并非如此设计——它们被设计为乱序、并行地执行指令,以最大化可用执行单元的利用率。
当出现较长的数据依赖时,处理器被迫顺序执行代码,只能利用其全部能力的一部分。长依赖链阻碍了并行性,这正是现代超标量(superscalar)CPU 主要优势的对立面。例如,指针追逐(pointer chasing)无法从乱序执行(OOO execution)中获益,因此只能以顺序 CPU 的速度运行。正如本节所展示的,依赖链是性能瓶颈的主要来源之一。
数据依赖是无法消除的,它们是程序的基本属性。任何程序都需要接受输入来完成计算。事实上,人们已经开发了在语句之间发现数据依赖并构建数据流图(data flow graphs)的技术,这称为依赖性分析(dependence analysis),更适合编译器开发者,而非性能工程师。我们不需要为整个程序构建数据流图,而是希望在热点代码(如循环或函数)中找到关键依赖链。
你可能会问:"如果无法消除依赖链,能做什么呢?"有时这确实是性能的限制因素,遗憾地你只能接受它。但在某些情况下,你可以打断不必要的数据依赖链,或使其执行相互重叠。清单 DepChain 展示了这样一个例子。与其他几个示例类似,我们在左侧展示源代码,在右侧展示对应的 ARM 汇编代码。此外,此代码示例包含在 Performance Ninja 在线课程的 dep_chains_2 实验任务中,你可以亲自尝试。2
这个小程序模拟随机粒子运动。我们有 1000 个粒子在二维曲面上运动,没有任何约束,这意味着它们可以从起始位置任意移动。每个粒子由其在二维曲面上的 x 和 y 坐标以及速度定义。初始 x 和 y 坐标在 [-1000,1000] 范围内,速度在 [0,1] 范围内且保持不变。程序为每个粒子模拟 1000 步运动。对于每一步,我们使用随机数生成器(RNG)产生一个角度,为粒子设置运动方向,然后相应地调整粒子的坐标。
鉴于手头的任务,你决定自己实现 RNG、正弦和余弦函数,以牺牲一些精度来尽可能地提高速度。毕竟,这是随机运动,所以这是一个合理的权衡。你选择了一个中等质量的 XorShift RNG,因为它内部只有 3 次移位和 3 次异或操作。还有什么比这更简单的呢?此外,你在网上找到了使用多项式近似正弦和余弦的算法,它们足够精确且非常快速。
清单:二维曲面上的随机粒子运动
struct Particle { │
float x; float y; float velocity; │
}; │
│
class XorShift32 { │
uint32_t val; │
public: │
XorShift32 (uint32_t seed) : val(seed) {} │
uint32_t gen() { │
val ^= (val << 13); │
val ^= (val >> 17); │
val ^= (val << 5); │
return val; │ .loop:
} │ eor w0, w0, w0, lsl #13
}; │ eor w0, w0, w0, lsr #17
│ eor w0, w0, w0, lsl #5
static float sine(float x) { │ ucvtf s1, w0
const float B = 4 / PI_F; │ fmov s2, w9
const float C = -4 / ( PI_F * PI_F); │ fmul s2, s1, s2
return B * x + C * x * std::abs(x); │ fmov s3, w10
} │ fadd s3, s2, s3
static float cosine(float x) { │ fmov s4, w11
return sine(x + (PI_F / 2)); │ fmul s5, s3, s3
} │ fmov s6, w12
│ fmul s5, s5, s6
/* Map degrees [0;UINT32_MAX) to radians [0;2*pi)*/ │ fmadd s3, s3, s4, s5
float DEGREE_TO_RADIAN = (2 * PI_D) / UINT32_MAX; │ ldp s6, s4, [x1, #0x4]
│ ldr s5, [x1]
void particleMotion(vector<Particle> &particles, │ fmadd s3, s3, s4, s5
uint32_t seed) { │ fmov s5, w13
XorShift32 rng(seed); │ fmul s5, s1, s5
for (int i = 0; i < STEPS; i++) │ fmul s2, s5, s2
for (auto &p : particles) { │ fmadd s1, s1, s0, s2
uint32_t angle = rng.gen(); │ fmadd s1, s1, s4, s6
float angle_rad = angle * DEGREE_TO_RADIAN; │ stp s3, s1, [x1], #0xc
p.x += cosine(angle_rad) * p.velocity; │ cmp x1, x16
p.y += sine(angle_rad) * p.velocity; │ b.ne .loop
} │
} │
我使用 Clang-17 C++ 编译器编译了该代码,并在 Mac mini(Apple M1,2020 年款)上运行。让我们检查生成的 ARM 汇编代码:
- 前三条
eor(按位异或)指令与lsl(左移)或lsr(右移)组合,对应于XorShift32::gen函数。 - 接下来的
ucvtf(将无符号整数转换为浮点数)和fmul(浮点乘法)用于将角度从度转换为弧度(代码第 35 行)。 - 正弦和余弦函数各有两条
fmul指令和一条fmadd(浮点融合乘加)指令。余弦还额外有一条fadd(浮点加法)指令。 - 最后,还有一对
fmadd指令分别计算 x 和 y,以及一条stp指令用于存储坐标对。
你期望这段代码"飞速运行",然而存在一个非常棘手的性能问题拖慢了程序。在阅读后文之前,你能在代码中找到一条循环递归依赖链吗?
如果你找到了,恭喜你。XorShift32::val 上存在一条循环递归依赖。为了生成下一个随机数,生成器必须先产生前一个随机数。XorShift32::gen 方法的下一次调用将基于前一个值生成数字。图 DepChain 可视化了有问题的循环携带依赖(loop-carry dependency)。注意,计算粒子坐标的代码(将角度转换为弧度、正弦、余弦、乘以速度)在对应的随机数准备好后立即开始执行,但不能更早。
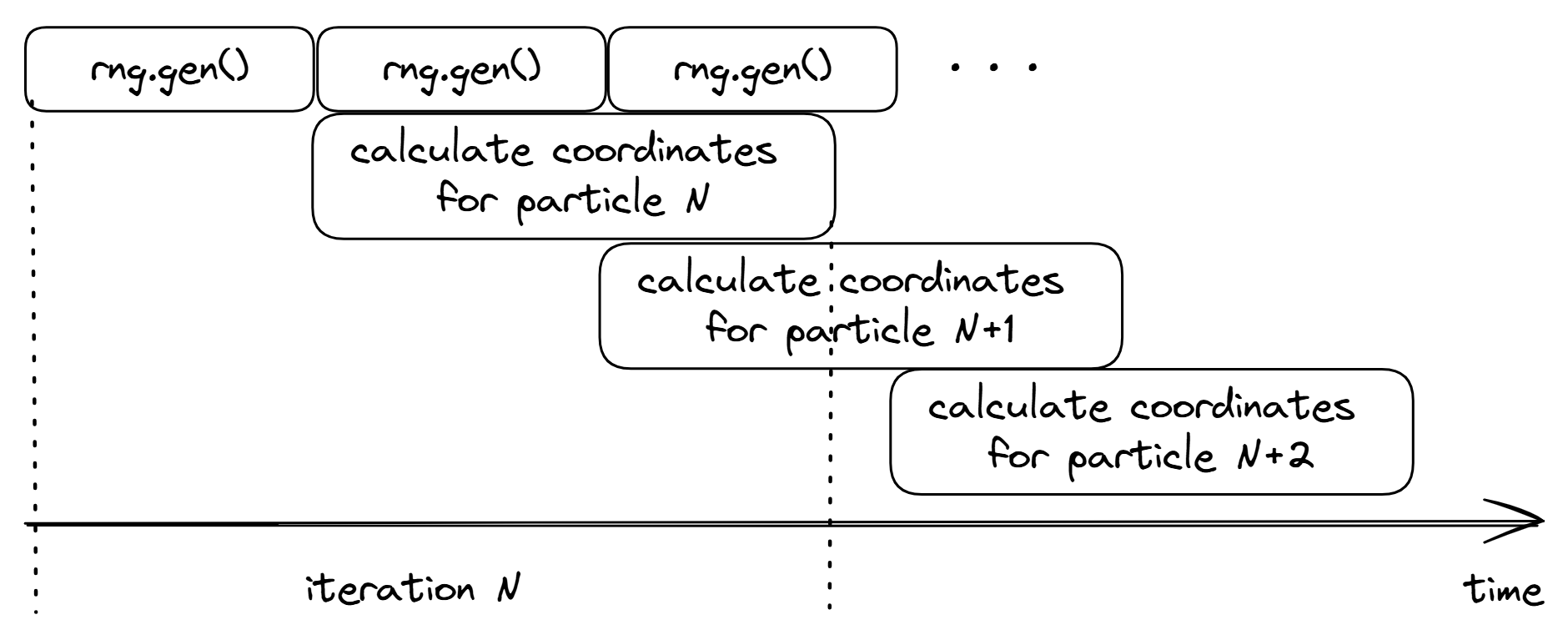
清单 DepChain 中依赖执行的可视化
计算粒子 N 坐标的代码不依赖于粒子 N-1,因此将它们向左拉以进一步重叠执行可能是有益的。你可能想问:"但是这三条(或六条)指令怎么能拖累整个循环的性能呢?"确实,循环中还有许多其他"重量级"指令,如 fmul 和 fmadd。然而,它们不在关键路径上,因此可以与其他指令并行执行。由于现代 CPU 非常宽(wide),它们会同时执行来自多个迭代的指令,这使得乱序执行引擎能够有效地在循环的不同迭代中找到并行性(独立指令)。
让我们做一些粗略估算。1 每条 eor 和 lsl 指令产生 2 个周期的延迟(latency):移位操作 1 个周期,异或操作 1 个周期。我们有三对相互依赖的 eor + lsl 指令,因此生成下一个随机数需要 6 个周期。这是该循环的绝对最小值:我们不可能做到每次迭代少于 6 个周期。后续代码需要至少 20 个周期的延迟来完成所有 fmul 和 fmadd 指令。但这并不重要,因为它们不在关键路径上。重要的是这些指令的吞吐量(throughput)。一个有用的经验法则:如果一条指令在关键路径上,关注其延迟;否则关注其吞吐量。每次循环迭代中,我们有 5 条 fmul 和 4 条 fmadd 指令在同一组执行单元上服务。M1 处理器每个周期可以运行 4 条此类指令,因此至少需要 9/4 = 2.25 个周期来发射所有 fmul 和 fmadd 指令。因此,我们有两个性能限制:第一个由软件施加(每次迭代 6 个周期,由于依赖链),第二个由硬件施加(每次迭代 2.25 个周期,由于执行单元的吞吐量)。目前我们受第一个限制约束,但可以尝试打断依赖链以接近第二个限制。
解决这个问题的方法之一是增加一个 RNG 对象,使一个对象为偶数次迭代提供随机数,另一个为奇数次迭代提供随机数,如清单 DepChainFixed 所示。注意,我们还手动展开了循环。现在我们有两条独立的依赖链,可以并行执行。你可能会认为这改变了程序的功能,但用户不会注意到差异,因为粒子运动本来就是随机的。另一种解决方案是选择一个内部依赖链开销更小的不同 RNG。
清单:二维曲面上的随机粒子运动
void particleMotion(vector<Particle> &particles,
uint32_t seed1, uint32_t seed2) {
XorShift32 rng1(seed1);
XorShift32 rng2(seed2);
for (int i = 0; i < STEPS; i++) {
for (int j = 0; j + 1 < particles.size(); j += 2) {
uint32_t angle1 = rng1.gen();
float angle_rad1 = angle1 * DEGREE_TO_RADIAN;
particles[j].x += cosine(angle_rad1) * particles[j].velocity;
particles[j].y += sine(angle_rad1) * particles[j].velocity;
uint32_t angle2 = rng2.gen();
float angle_rad2 = angle2 * DEGREE_TO_RADIAN;
particles[j+1].x += cosine(angle_rad2) * particles[j+1].velocity;
particles[j+1].y += sine(angle_rad2) * particles[j+1].velocity;
}
// remainder (not shown)
}
}
完成这一变换后,编译器开始对循环体进行自动向量化(autovectorizing),即将两条依赖链合并,并使用 SIMD 指令并行处理它们。为了隔离打断依赖链的效果,我禁用了编译器向量化。
为了衡量此改变的性能影响,我分别运行了"修改前"和"修改后"的版本,观察到运行时间从每次迭代 19ms 下降到 10ms。这几乎是 2 倍的加速。IPC(每周期指令数)也从 4.0 提升到 7.1。为了确保严谨,我还测量了其他指标,以确认性能改善不是偶然由其他原因造成的。在原始代码中,MPKI 为 0.01,BranchMispredRate 为 0.2%,这意味着程序最初没有受到缓存未命中或分支预测错误的困扰。还有一个数据点:在 Intel Alder Lake 系统上运行相同代码时,显示 74% Retiring 和 24% Core Bound,这确认了性能受计算约束。
通过一些额外的修改,你可以将此解决方案泛化为拥有任意数量的依赖链。对于 M1 处理器,测量结果表明拥有 2 条依赖链足以非常接近硬件极限。拥有超过 2 条依赖链带来的性能提升可以忽略不计。然而,有一个趋势是 CPU 正变得越来越宽(wider),即它们越来越能够并行运行多条依赖链。这意味着未来的处理器可能受益于超过 2 条依赖链。一如既往,你应该进行测量,并为你的代码将运行的平台找到最佳平衡点。
有时仅仅打断依赖链是不够的。想象一下,不是一个简单的 RNG,而是一个非常复杂的加密算法,长达 10,000 条指令。因此,我们不再是一条很短的 6 条指令的依赖链,而是 10,000 条指令站在关键路径上。你立刻做了上面同样的修改,预期获得不错的 2 倍加速,但只看到了 5% 的性能提升。发生了什么?
问题在于 CPU 根本无法"看到"第二条依赖链以开始执行它。回顾第 3 章,保留站(Reservation Station,RS)的容量不足以提前看到 10,000 条指令,因为其条目数量远小于此。因此,CPU 将无法重叠两条依赖链的执行。要解决这个问题,我们需要交错(interleave)这两条依赖链。采用这种方法,你需要修改代码,使 RNG 对象同时生成两个数字,函数 XorShift32::gen 内的每一条语句都被复制并交错。即使编译器内联了所有代码并能清楚地看到两条依赖链,它也不会自动交错它们,所以你需要注意这一点。另一个可能遇到的限制是寄存器压力(register pressure)。并行运行多条依赖链需要保存更多状态,因此需要更多寄存器。如果架构寄存器不够用,编译器将开始将它们溢出(spilling)到栈上,这会降低程序速度。
值得一提的是,数据依赖也可以通过内存创建。例如,如果你在循环迭代 N 中向内存位置 M 写入,并在迭代 N+1 中从该位置读取,则实际上会存在一条依赖链。存储的值可能被转发给加载操作,但这些指令不能被重新排序和并行执行。
作为结语,我想强调找到关键依赖链的重要性。这并不总是容易的,但了解循环、函数或其他代码块中关键路径上的内容至关重要。否则,你可能会发现自己在修复几乎没有差别的次要问题。
1. Apple 在 [AppleOptimizationGuide] 中发布了指令延迟和吞吐量数据。 ↩
2. Performance Ninja:依赖链 2 - https://github.com/dendibakh/perf-ninja/tree/main/labs/core_bound/dep_chains_2 ↩