AMD uProf
uProf 是 AMD 开发的一款性能分析工具,用于监控运行在 AMD 处理器上的应用程序的性能。虽然 uProf 也可以在 Intel 处理器上使用,但届时只能使用与 CPU 无关的功能。该分析工具可免费下载,支持在 Windows、Linux 和 FreeBSD 上使用。AMD uProf 可用于在多种虚拟机(VM)上进行性能分析,包括 Microsoft Hyper-V、KVM、VMware ESXi 和 Citrix Xen,但并非所有功能在所有虚拟机上都可用。此外,uProf 支持分析多种语言编写的应用程序,包括 C、C++、Java、.NET/CLR。
如何配置
在 Linux 上,uProf 使用 Linux perf 进行数据收集。在 Windows 上,uProf 使用其自有的采样驱动程序,该驱动程序在安装 uProf 时自动安装,无需额外配置。AMD uProf 同时支持命令行界面(CLI)和图形界面。CLI 界面需要两个独立步骤——采集(collect)和报告(report),与 Linux perf 类似。
可以用它做什么
- 查找热点:函数、语句、指令。
- 监控各种硬件性能事件并定位这些事件发生的代码行。
- 针对特定函数或线程过滤数据。
- 观察工作负载随时间的行为:在时间线图表中查看各种性能事件。
- 分析热调用路径(hot callpaths):调用图(call graph)、火焰图(flame graph)和自底向上图表。
此外,uProf 还可以监控 Linux 上的各种操作系统事件:线程状态、线程同步、系统调用、缺页错误(page faults)等。可以使用它分析 OpenMP 应用程序以检测线程不均衡,以及分析 MPI3 应用程序以检测 MPI 集群各节点之间的负载不均衡。有关 uProf 各种功能的更多详细信息,请参阅用户指南1。
不能用它做什么
由于该工具的采样特性,它最终会错过持续时间非常短的事件。报告的样本是统计估算数字,在大多数情况下足以分析性能,但并非事件的精确计数。
示例
为了展示 AMD uProf 工具的外观和使用感受,我们在运行 Windows 11、配备 64 GB RAM 的 AMD Ryzen 9 7950X 上,运行了来自 Scimark22 基准测试的稠密 LU 矩阵分解(dense LU matrix factorization)组件。
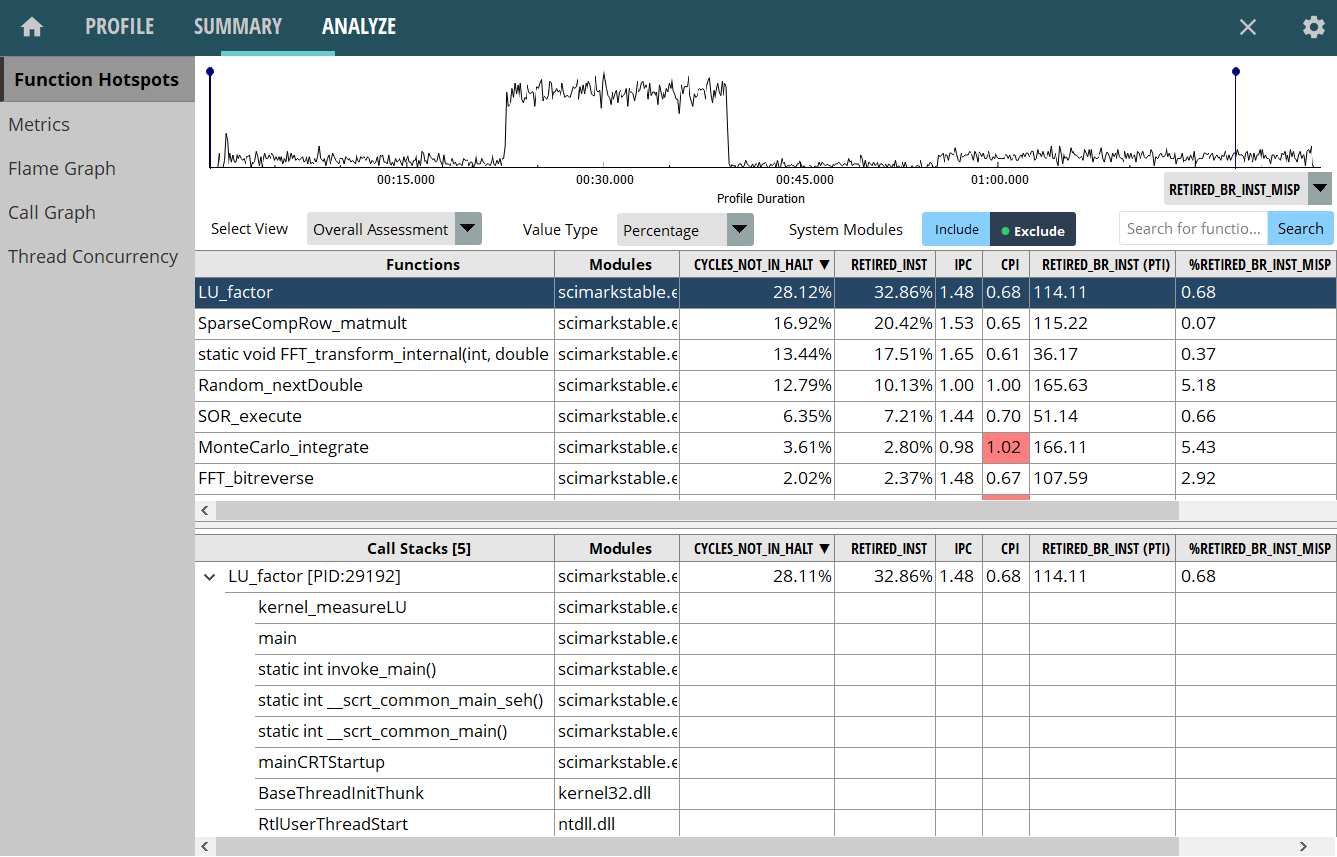
uProf 的函数热点视图。
图 uProfHotspots 展示了函数热点(Function Hotpots)分析(在图像左侧的菜单列表中选中)。图像顶部显示了一个事件时间线,展示了应用程序执行各时刻观察到的事件数量。在右侧可以选择要绘制的指标;我们选择了 RETIRED_BR_INST_MISP。注意在 20s 到 40s 的时间范围内出现了分支预测错误的峰值。可以选择该区域来仔细分析其中发生了什么。一旦执行此操作,底部面板将更新为仅显示该时间区间的统计信息。
在时间线图表下方,可以看到热函数列表,以及对应的采样性能事件和计算的指标。事件计数可以以样本计数、原始事件计数或百分比形式查看。有许多有趣的数字可以研究,但我们不会深入分析。相反,鼓励读者自行探究分支预测错误的性能影响并找出其来源。
在函数表下方,可以看到函数表中所选函数的自底向上调用栈视图。如我们所见,所选的 LU_factor 函数由 kernel_measureLU 调用,后者又由 main 调用。在 Scimark2 基准测试中,这是 LU_factor 的唯一调用栈,尽管它显示 Call Stacks [5]。这是采集过程中的一个假象,可以忽略。但在其他应用程序中,热函数可能从很多不同的地方被调用,因此你也会想检查其他调用栈。
如果双击任意函数,uProf 将为该函数打开源代码/汇编视图。为简洁起见,我们不展示此视图。在左侧面板中,还有其他可用视图,如 Metrics(指标)、Flame Graph(火焰图)、Call Graph(调用图)视图和 Thread Concurrency(线程并发)。它们对分析也很有用,但我们决定跳过。读者可以自行实验并查看这些视图。
1. AMD uProf User Guide - https://www.amd.com/en/developer/uprof.html#documentation ↩
2. Scimark2 - https://math.nist.gov/scimark2/index.html ↩
3. MPI - Message Passing Interface,分布式内存系统上并行编程的标准。 ↩