任务调度
随着混合处理器的出现,任务调度(Task Scheduling)变得极具挑战性。例如,最近的 Intel Meteor Lake 芯片具有三种类型的核心,各自具有不同的性能特性。正如你将在本节中看到的,由于任务调度不优化,很容易导致多线程应用程序性能下降。实现通用任务调度策略很棘手,因为它在很大程度上取决于正在运行任务的性质。以下是一些例子:
- 计算密集型轻量线程工作负载(例如数据压缩)必须仅在 P 核上服务。
- 后台任务(例如视频通话)可以在 E 核上运行以节省电力。
- 对于需要高响应性的突发应用程序(例如生产力软件),系统应仅使用 P 核。
- 具有持续性能需求的多线程程序(例如视频渲染)应同时利用 P 核和 E 核。
在大多数情况下,现代操作系统中的任务调度器会处理这些以及许多其他边缘情况。例如,Intel 的 Thread Director 帮助实时监控和分析性能数据,将正确的应用程序线程无缝地放置在正确的核心上。我的一般建议是让操作系统完成其工作,不要过多限制它。操作系统知道如何调度任务以最小化竞争、最大化缓存中数据的重用,并最终最大化性能。如果你正在开发旨在运行在不同硬件配置上的跨平台软件,这将发挥重要作用。
下面我展示了非对称系统中任务调度的几个典型陷阱。我使用了与上一个案例研究中相同的系统:第 12 代 Alder Lake Intel® Core™ i7-1260P CPU,它有四个 P 核和八个 E 核。为简单起见,我只启用了两个 P 核和两个 E 核;其余核心被临时禁用。我还禁用了两个活跃 P 核上的 SMT 兄弟线程。我编写了一个简单的 OpenMP 应用程序,其中每个工作线程对一个大数组的每个 32 位整数元素运行几个位操作。工作线程完成处理后,它遇到一个屏障(barrier),被迫等待其他线程完成各自的部分。之后,主线程清理数组,处理重复。程序用 GCC 13.2 和 -O3 -march=core-avx2 编译,这会启用向量化。
图 OmpScheduling 展示了三种策略,这些策略突出了我在实践中经常看到的常见问题。这些截图是用 Intel VTune 捕获的。时间线上的条表示 CPU 时间,即线程正在运行的时段。对于每个软件线程,有一个或两个对应的 CPU 核心。使用此视图,我们可以看到每个线程在任何给定时刻在哪个核心上运行。
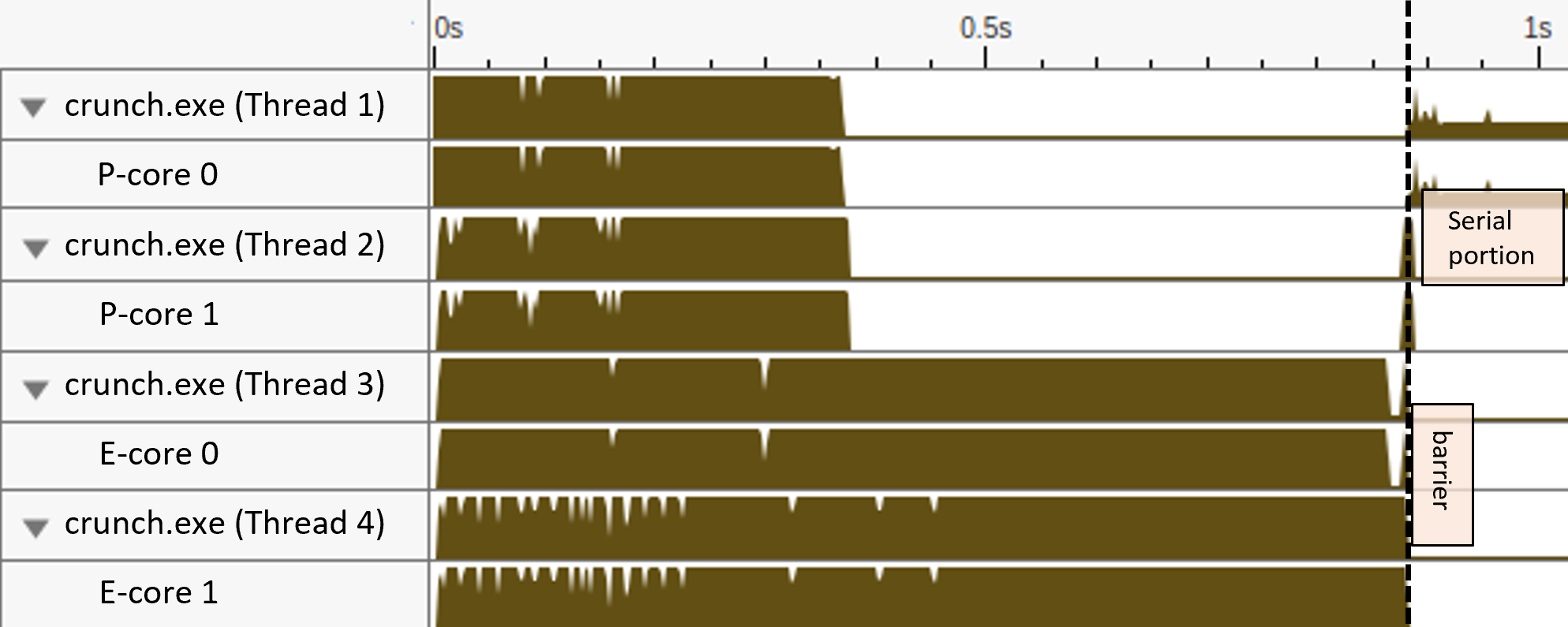
典型的任务调度陷阱:核心亲和性阻止线程迁移,大粒度分区作业无法最大化 CPU 利用率。
我们的第一个例子使用静态分区,将大数组的处理分成四个相等的块(因为我启用了四个核心)。对于每个块,OpenMP 运行时生成一个新线程。此外,我使用了 OMP_PROC_BIND=true,这指示 OpenMP 运行时将生成的线程固定到 CPU 核心。图 OmpAffinity 展示了效果:P 核在处理 SIMD 指令方面远优于 E 核,它们以两倍速度完成任务(见 Thread 1 和 Thread 2)。然而,线程亲和性不允许 Thread 3 和 Thread 4 迁移到正在屏障处等待的 P 核上。这导致高延迟,受 E 核速度的限制。
我的建议是避免将线程固定到核心。在工作不平衡的情况下,固定可能限制工作窃取,将长时间执行的尾部留给 E 核。在 macOS 上,无法将线程固定到核心,因为操作系统不提供相应的 API。
在第二个例子中,我不再固定线程,但分区方案保持不变(四个相等的块)。图 OmpStatic 展示了这一变化的效果。与之前的场景一样,Thread 1 和 Thread 4 提前完成任务,因为它们使用了 P 核。Thread 2 和 Thread 3 开始在 E 核上运行,但一旦 P 核可用,它们就迁移了。这解决了之前的问题,但现在 E 核在处理结束前保持空闲。
我的第二个建议是避免在具有非对称核心的系统上进行静态分区。等大小的块在 P 核上的处理速度可能比在 E 核上快,这将引入动态负载不平衡。
在最后一个例子中,我切换到使用动态分区。使用动态分区,块被动态分配给线程。每个线程处理一个元素块,然后请求另一个块,直到没有块需要分配。图 OmpDynamic 展示了通过将数组分成 16 个块来使用动态分区的结果。采用这种方案,每个任务变得更细粒度,这使 OpenMP 运行时能够在 P 核以两倍速度运行时平衡工作。然而,注意 E 核上仍有一些空闲时间。
如果我们将工作分成 128 个块而不是 16 个,性能可以略有提高。但不要让任务太小,否则会导致管理开销增加。我的实验结果摘要如表 TaskSchedulingResults 所示。将工作分成 128 个块被证明是我们示例的最优点。尽管这个例子非常简单,但从中得到的经验可以应用于生产级多线程软件。
| 亲和性 | 静态 | 动态, 4 块 | 动态, 16 块 | 动态, 128 块 | 动态, 1024 块 | |
|---|---|---|---|---|---|---|
| 10 次运行的平均延迟(ms) | 864 | 567 | 570 | 541 | 517 | 560 |
表:任务调度实验结果。