案例研究:对末级缓存大小的敏感性
在本案例研究中,我们以不同的 LLC 大小对同一组应用程序运行多次。现代服务器处理器允许用户控制 LLC 空间到处理器线程的分配。通过这种方式,用户可以限制每个线程只使用其分配的共享资源量。此类功能通常称为服务质量(QoS,Quality of Service)扩展。它们可用于优先保障性能关键应用程序,并减少同一系统中其他线程的干扰。除 LLC 分配外,QoS 扩展还支持限制内存读取带宽。
我们的分析将帮助我们识别当 LLC 大小减小时性能显著下降的应用程序。我们称此类应用程序对 LLC 大小敏感。此外,我们还识别了不敏感的应用程序,即 LLC 大小对性能没有影响。这一结果可用于合理确定处理器 LLC 的规格,尤其考虑到市场上 LLC 大小范围极广。例如,我们可以确定某个应用程序从更大的 LLC 中获益,那么也许对新硬件的投资是合理的。相反,如果某应用程序的性能不会因为拥有更大的 LLC 而提升,那么我们可以购买更便宜的处理器。
在本案例研究中,我们使用 AMD Milan 处理器,但其他服务器处理器,如 Intel Xeon [QoSXeon] 和 Arm ThunderX [QoSThunderX],同样包含硬件支持,允许用户控制 LLC 空间和内存读取带宽到处理器线程的分配。根据我们的测试,本节所述方法在基于 AMD Zen4 的台式机处理器(如 7950X 和 7950X3D)上同样有效。
目标机器:AMD EPYC 7313P
我们使用了一台配备 16 核 AMD EPYC 7313P 处理器(代号 Milan)的服务器系统,该处理器由 AMD 于 2021 年推出。该系统的主要特性如表 Table experimental_setup 所示。
| Feature | Value |
|---|---|
| Processor | AMD EPYC 7313P |
| Cores x threads | 16 2 |
| Configuration | 4 CCX 4 cores/CCX |
| Frequency | 3.0/3.7 GHz, base/max |
| L1 cache (I, D) | 8-ways, 32 KiB (per core), 64-byte lines |
| L2 cache | 8-ways, 512 KiB (per core), 64-byte lines |
| LLC | 16-ways, 32 MB, non-inclusive (per CCX), 64-byte lines |
| Main Memory | 512 GiB DDR4, 8 channels, nominal peak BW: 204.8 GB/s |
| TurboBoost | Disabled |
| Hyperthreading | Disabled (1 thread/core) |
| OS | Ubuntu 22.04, kernel 5.15.0-76 |
表:实验所用服务器的主要特性。
图 milan7313P 展示了 AMD Milan 7313P 处理器的集群内存层次结构。它由四个核心复合体裸片(CCD,Core Complex Die)组成,通过 I/O 芯片组相互连接并连接到片外内存。每个 CCD 集成了一个核心复合体(CCX,Core CompleX)和一个 I/O 连接。每个 CCX 包含四个 Zen3 核心,共享一个 32 MB 的受害者(victim)LLC。11
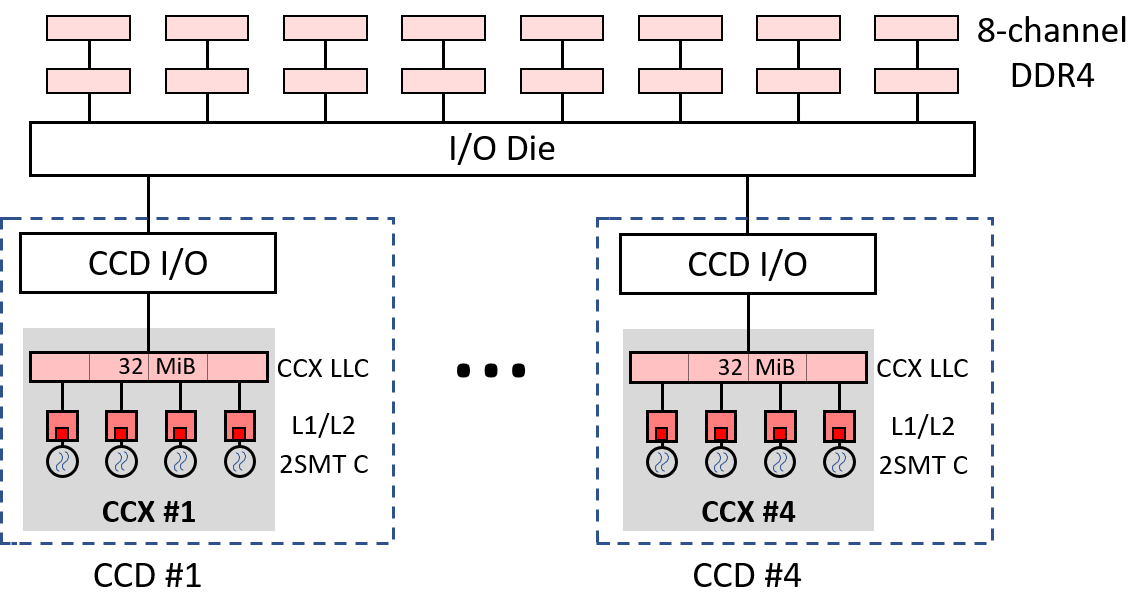
AMD Milan 7313P 处理器的集群内存层次结构。
尽管总共有 128 MB 的 LLC(32 MB/CCX × 4 CCX),一个 CCX 的四个核心无法在其自身 32 MB LLC 之外的 LLC 中存储缓存行。由于我们将运行单线程基准测试,因此可以专注于单个 CCX。我们实验中的 LLC 大小将从 0 到 32 MB 以 2 MB 为步长变化。这与 16 路 LLC 直接相关:每禁用 16 路中的一路,LLC 大小减少 2 MB。
工作负载:SPEC CPU2017
我们使用 SPEC CPU2017 套件4中的应用程序子集。SPEC CPU2017 包含一系列行业标准化工作负载,用于对处理器、内存子系统和编译器的性能进行基准测试。它被广泛用于比较高性能系统的性能及计算机架构研究。
具体地,我们按照 [MemCharacterizationSPEC2006] 的建议,从 SPEC CPU2017 中选取了 15 个内存密集型基准测试程序(6 个整数型,9 个浮点型)。这些应用程序使用 GCC 6.3.1 和以下编译器选项编译:-O3 -march=native -fno-unsafe-math-optimizations。
控制和监测 LLC 分配
为了监测和执行 LLC 分配及内存读取带宽的限制,我们将使用 AMD64 Technology Platform Quality of Service Extensions [QoSAMD]。用户可以通过模型特定寄存器(MSR,Model-Specific Registers)组来管理此 QoS 扩展。首先,必须通过写入 PQR_ASSOC 寄存器(MSR 0xC8F)为线程或线程组分配资源管理标识符(RMID,resource management identifier)和服务类别(COS,class of service)。以下是硬件线程 1 的示例命令:
# write PQR_ASSOC (MSR 0xC8F): RMID=1, COS=2 -> (COS << 32) + RMID
{% math_inline %} wrmsr -p 1 0xC8F 0x200000001
其中 -p 1 指硬件线程 1。我们展示的所有 rdmsr 和 wrmsr 命令都需要 root 权限。
LLC 空间管理通过写入一个 16 位的每线程二进制掩码来实现。掩码的每一位允许线程使用 LLC 的 1/16 份额(对于 AMD Milan 7313P,即 2 MB)。多个线程可以使用相同的份额,这意味着对 LLC 相同子集的竞争性共享使用。
要设置线程 1 的 LLC 使用限制,我们需要写入 L3_MASK_n 寄存器,其中 n 是 COS,即对应 COS 可以使用的缓存分区。例如,要将线程 1 限制为只使用 LLC 一半的可用空间,请运行以下命令:
# write L3_MASK_2 (MSR 0xC92): 0x00FF (half of the LLC space)
{% endmath_inline %} wrmsr -p 1 0xC92 0x00FF
同样,可以限制分配给线程的内存读取带宽。这通过向特定的 MSR 寄存器写入一个无符号整数来实现,该整数以 1/8 GB/s 为增量设置最大读取带宽。感兴趣的读者欢迎阅读 [QoSAMD] 了解更多详情。
度量指标
量化应用程序性能的最终度量指标是执行时间(execution time)。为了分析内存层次结构对系统性能的影响,我们还将使用以下三个度量指标:1) CPI(每指令周期数,cycles per instruction),2) DMPKI(每千条指令的 LLC 需求未命中数,demand misses in the LLC per thousand instructions),3) MPKI(每千条指令的总未命中数(需求 + 预取),total misses in the LLC per thousand instructions)。虽然 CPI 与应用程序性能直接相关,但 DMPKI 和 MPKI 不一定影响性能。表 metrics 显示了从特定硬件计数器计算每个度量指标的公式。每个计数器的详细描述可在 AMD 的处理器编程参考手册 [amd_ppr] 中找到。
| Metric | Formula |
|---|---|
| CPI | Cycles not in Halt (PMCx076) / Retired Instructions (PMCx0C0) |
| DMPKI | Demand Data Cache Fills9 (PMCx043) / (Retired Instr (PMCx0C0) / 1000) |
| MPKI | L3 Misses8 (L3PMCx04) / (Retired Instructions (PMCx0C0) / 1000) |
表:案例研究中使用的度量指标计算公式。
本案例研究使用的方法在 [Balancer2023] 中有更详细的描述,其中还解释了我们如何配置和读取硬件计数器。重现实验所需的代码和信息可在以下公开仓库中找到:https://github.com/agusnt/BALANCER。
结果
我们在系统中单独运行一组 SPEC CPU2017 基准测试程序,每次只运行一个实例和单个硬件线程。我们在 LLC 大小从 0 到 32 MB 以 2 MB 为步长变化的过程中重复这些运行。
图 characterization_llc 以图表形式展示了从左到右的 CPI、DMPKI 和 MPKI,针对每种分配的 LLC 大小。我们只展示三个工作负载,即 503.bwaves(蓝色)、520.omnetpp(绿色)和 554.roms(红色)。它们涵盖了在所有其他应用程序中观察到的三种主要趋势,因此我们不展示其余基准测试程序。
对于 CPI 图表,Y 轴值越低意味着性能越好。由于系统的频率是固定的,CPI 图表反映了绝对分数。例如,拥有 32 MB LLC 的 520.omnetpp(绿线)比拥有 0 MB LLC 的版本快 2.5 倍。对于 DMPKI 和 MPKI 图表,Y 轴值越低越好。
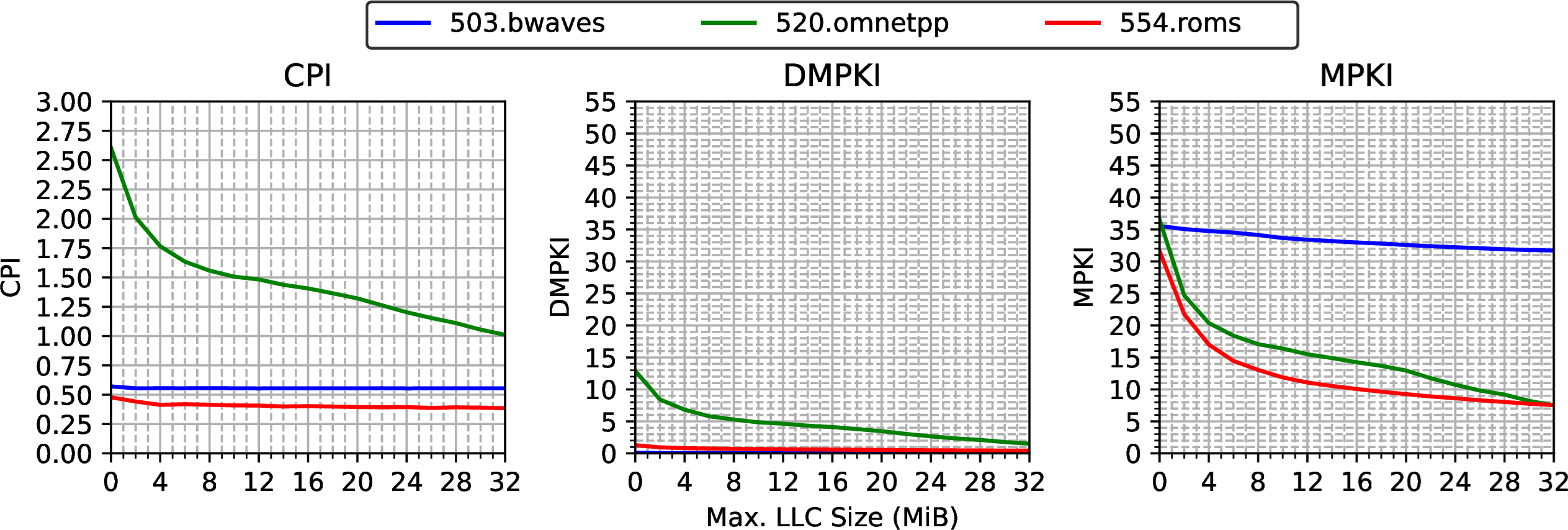
随 LLC 分配限制增加(2 MB 步长)的 CPI、DMPKI 和 MPKI。
在 CPI 和 DMPKI 图表中可以观察到两种不同的行为。一方面,520.omnetpp 充分利用了 LLC 中的可用空间:随着 LLC 中分配的空间增加,CPI 和 DMPKI 都显著下降。我们可以说 520.omnetpp 的行为对 LLC 中的可用大小敏感。增加分配的 LLC 空间可以提高性能,因为它避免了驱逐将来会被使用的缓存行。
相比之下,503.bwaves 和 554.roms 并没有利用所有可用的 LLC 空间。对于这两个基准测试程序,随着 LLC 分配限制的增长,CPI 和 DMPKI 大致保持不变。我们可以说这两个应用程序的性能对其在 LLC 中的可用空间不敏感。12 如果您的应用程序表现出类似的行为,您可以购买 LLC 较小的更便宜的处理器而不会牺牲性能。
现在让我们分析 MPKI 图表,它结合了 LLC 需求未命中和预取请求。首先,我们可以看到 MPKI 值始终远高于 DMPKI 值。也就是说,大多数数据块(cache lines)是由预取器(prefetcher)从内存加载到片上层次结构中的。这种行为是由于预取器在将私有缓存中要使用的数据预加载方面效率很高,从而消除了大多数需求未命中。
对于 503.bwaves,我们观察到 MPKI 大致保持在相同水平,与 CPI 和 DMPKI 图表类似。基准测试中可能没有太多数据复用,和/或内存流量非常低。520.omnetpp 工作负载的行为与我们之前识别的一致:随着可用空间的增加,MPKI 下降。
然而,对于 554.roms,MPKI 图表显示,随着可用空间的增加,总未命中数大幅下降,而 CPI 和 DMPKI 保持不变。在这种情况下,基准测试中存在数据复用,但这对性能没有实质影响。无论 LLC 中的可用空间如何,预取器都可以提前加载所需数据,消除需求未命中。然而,随着可用空间的减少,预取器在 LLC 中找不到数据块而不得不从内存加载的概率增加。因此,给予 554.roms 更多 LLC 容量不会直接提升其性能,但对系统有益,因为它减少了内存流量。所以,最好不要限制 554.roms 的可用 LLC 空间,因为这可能对系统中其他运行应用程序的性能产生负面影响。[Balancer2023]
4. SPEC CPU® 2017 - https://www.spec.org/cpu2017/。 ↩
8. 我们使用掩码专门计算 L3 未命中,具体为 L3Event[0x0300C00000400104]。 ↩
9. 我们使用了子事件MemIoRemote和MemIoLocal,它们计算来自远程/本地 NUMA 节点的 DRAM 或 IO 的需求数据缓存填充。 ↩
11. "受害者(Victim)"意味着 LLC 填充了从 CCX 的四个 L2 缓存驱逐的缓存行。 ↩
12. 然而,对于554.roms,我们可以观察到在 0-4 MB 范围内对 LLC 可用空间的敏感性。一旦 LLC 大小达到 4 MB 及以上,性能保持不变。这意味着554.roms不需要超过 4 MB 的 LLC 空间即可良好运行。 ↩