线程数扩展案例研究
线程数扩展分析也许是你可以在多线程应用程序上执行的最有价值的分析。它展示了应用程序利用现代多核系统的能力。正如你将看到的,在这一过程中可以学到大量信息。无需过多介绍,让我们直接开始。在本案例研究中,我们将分析以下基准测试的线程数扩展情况,其中一些你应该在前几章中已经有所了解:
- Blender 3.4 - 一款开源 3D 创作和建模软件项目。本测试使用 BMW27 blend 文件测试 Blender 的 Cycles 性能。URL:https://download.blender.org/release。命令行:
./blender -b bmw27_cpu.blend -noaudio --enable-autoexec -o output.test -x 1 -F JPEG -f 1 -t N,其中N为线程数。 - Clang 17 构建 - 本测试使用 Clang 15 从源代码构建 Clang 17 编译器。URL:https://www.llvm.org。命令行:
ninja -jN clang,其中N为线程数。 - Zstandard v1.5.5,一种快速无损压缩算法。URL:https://github.com/facebook/zstd。压缩所用数据集:http://wanos.co/assets/silesia.tar。命令行:
./zstd -TN -3 -f -- silesia.tar,其中N为压缩工作线程数。 - CloverLeaf 2018 - 一个 Lagrangian-Eulerian 流体动力学基准测试。使用所有硬件线程。本测试使用输入文件
clover_bm.in(问题 5)。URL:http://uk-mac.github.io/CloverLeaf。命令行:export OMP_NUM_THREADS=N; ./clover_leaf,其中N为线程数。 - CPython 3.12,Python 编程语言的参考实现。URL:https://github.com/python/cpython。我运行了一个用 Python 编写的简单多线程二分查找脚本,该脚本在一个包含
1,000,000个元素的有序列表(haystack)中搜索10,000个随机数(needles)。命令行:./python3 binary_search.py N,其中N为线程数。needles 在线程之间均等分配。
基准测试在具有以下配置的机器上执行:
- 第 12 代 Alder Lake Intel® Core™ i7-1260P CPU @ 2.10GHz(4.70GHz Turbo),4P+8E 核心,18MB L3 缓存。
- 16 GB RAM,DDR4 @ 2400 MT/s。
- Clang 15 编译器,编译选项:
-O3 -march=core-avx2。 - 256GB NVMe PCIe M.2 SSD。
- 64 位 Ubuntu 22.04.1 LTS(Jammy Jellyfish,Linux 内核 6.5)。
这显然不是顶级硬件配置,而是一台主流电脑,不一定专为处理媒体、开发或 HPC 工作负载而设计。然而,它是我们案例研究的绝佳平台,因为它展示了线程数扩展的各种效应。由于资源有限,应用程序即使在线程数较少时也会遇到性能瓶颈。请记住,在更好的硬件上,扩展结果会有所不同。
我的处理器有四个 P 核(P-cores)和八个 E 核(E-cores)。P 核支持 SMT(超线程技术),这意味着该平台上的线程总数为十六个。默认情况下,Linux 调度器会首先尝试使用空闲的物理 P 核。前四个线程将利用四个空闲 P 核上的四个线程。当它们完全被利用后,调度器将开始在 E 核上调度线程。因此,接下来的八个线程将被调度到八个 E 核上。最后,剩余的四个线程将被调度到 P 核的 4 个 SMT 兄弟线程上。
除 Zstd 和 CPython 外,我在运行基准测试时使用了上述方案对线程进行亲和性绑定(affinitizing)。不使用亲和性更能代表真实场景,但线程亲和性使线程数扩展分析更为清晰。由于性能数字非常相似,本案例研究中展示了使用线程亲和性时的结果。
基准测试执行固定数量的工作。无论线程数如何,退役指令数(retired instructions)几乎相同。在所有基准测试中,算法的最大部分都采用分治范式(divide-and-conquer paradigm)实现,其中工作被分成相等的部分,每个部分可以独立处理。理论上,这允许应用程序随核心数量良好扩展。然而实际上,扩展效果往往远非最优。
图 ScalabilityMainChart 显示了所选基准测试的线程数可扩展性。X 轴表示线程数,Y 轴显示相对于单线程执行的加速比。加速比计算为单线程执行时间除以多线程执行时间。加速比越高,应用程序随线程数的扩展越好。
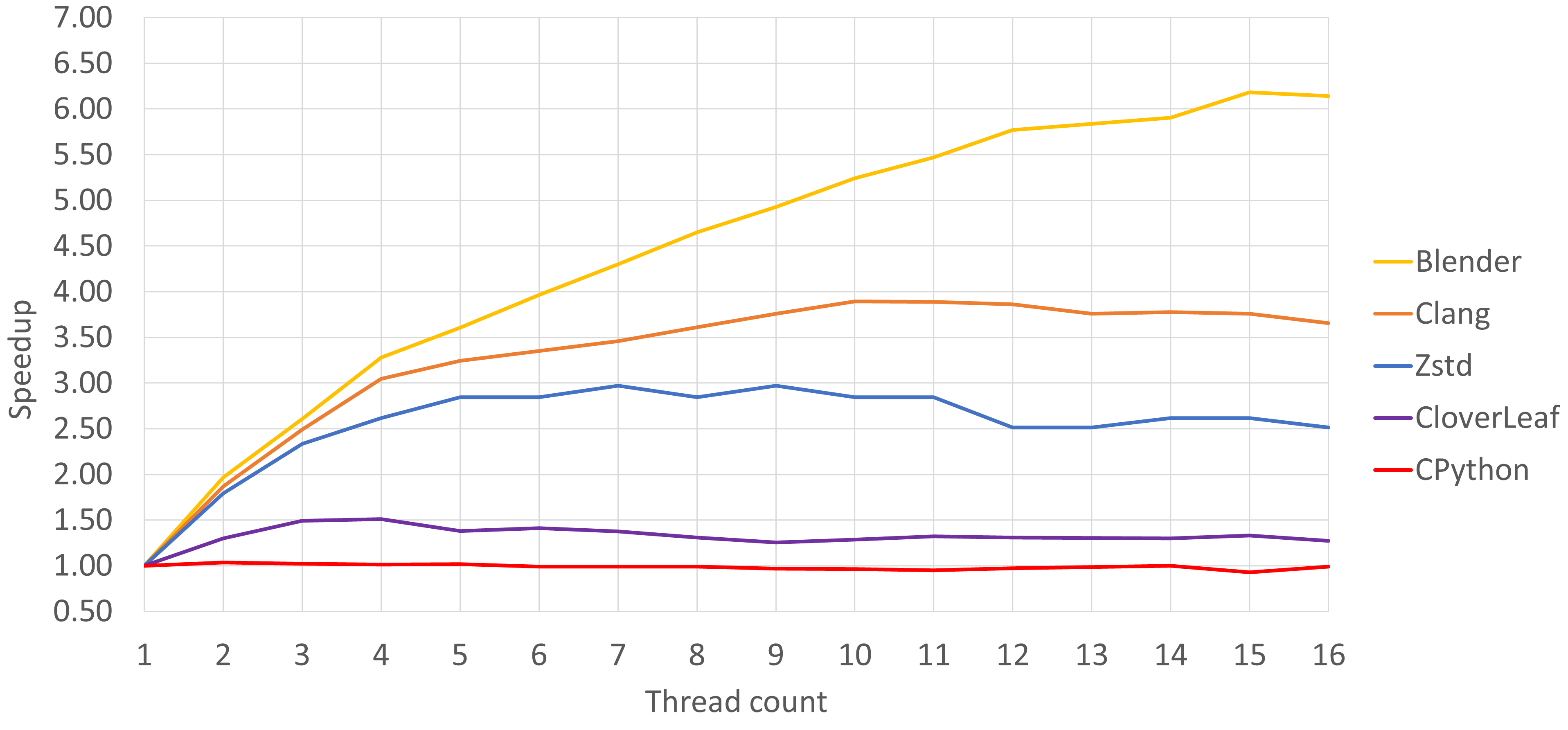
五个所选基准测试的线程数可扩展性图表。
如你所见,大多数基准测试距离线性扩展还差得很远,这相当令人失望。本案例研究中扩展性最佳的基准测试——Blender,在使用 16 倍线程时仅实现了 6 倍加速比。例如,CPython 完全没有线程数扩展。当线程数超过 10 时,Clang 和 Zstd 的性能开始下降。为了理解原因,让我们深入了解每个基准测试的细节。
Blender
Blender 是我们测试套件中唯一能够持续扩展到系统中所有 16 个线程的基准测试。原因在于该工作负载具有高度可并行性。渲染过程被分成小块,每块可以独立渲染。然而,即使具有如此高的并行度,扩展性也只有 6.1x 加速比 / 16 线程 = 38%。造成这种次优扩展的原因是什么?
从 [PerfMetricsCaseStudy] 中我们知道,Blender 的性能受浮点计算限制。它的 SIMD 指令比例也相对较高。P 核在处理此类指令方面远优于 E 核。这就是为什么当 E 核开始被使用时,我们看到加速比曲线的斜率在 4 个线程后下降。性能扩展以相同的速度持续到 12 个线程,之后再次开始下降。这是使用 SMT 兄弟线程的效应。两个活跃的兄弟 SMT 线程争夺有限数量的 FP/SIMD 执行单元。为了测量 SMT 扩展,我们需要将两个 SMT 线程的性能(2T1C - 双线程单核)除以单个 P 核的性能(1T1C)。5 对于 Blender,SMT 扩展约为 1.3x。
还有另一个也适用于 Blender 的扩展下降方面,我们将在讨论 Clang 的线程数扩展时提及。
Clang
虽然 Blender 使用多线程来利用并行性,但 C++ 编译中的并发性通常通过多进程来实现。Clang 17 有超过 2,500 个翻译单元,为编译每个翻译单元都会生成一个新进程。与 Blender 类似,我们将 Clang 编译归类为大规模并行,但它们的扩展方式不同。我们建议你重新查看 [PerfMetricsCaseStudy] 以了解 Clang 编译器性能瓶颈的概述。简而言之,它有一个庞大的代码库、扁平的性能剖析、许多小函数和"分支密集"(branchy)的代码。其性能受 D-Cache、I-Cache 和 TLB 未命中以及分支预测错误的影响。Clang 的线程数扩展受到与 Blender 相同的扩展问题影响:P 核比 E 核更有效,P 核 SMT 扩展约为 1.1x。然而,还有更多原因。注意扩展在约 10 个线程时停止,并开始下降。让我们理解为什么会发生这种情况。
问题与频率降速(frequency throttling)有关。当多个核心同时被利用时,由于每个核心上的工作负载增加,处理器会产生更多热量。为了防止过热并保持稳定性,CPU 通常会根据使用核心的数量降低时钟速度。此外,同时将所有核心提升到最大 Turbo 频率将需要显著更多的功耗,这可能超过 CPU 的电力传输能力。我的系统没有高级液冷解决方案,只有一个单独的处理器风扇。这就是为什么当多个核心被同时利用时,它无法维持高频率。
图 FrequencyThrotlingClang 显示了 Clang 工作负载的性能扩展与我们平台上使用不同线程数时 CPU 频率的叠加情况。注意,当我们同时开始使用两个 P 核时,持续频率就会下降。当你开始使用所有 16 个线程时,P 核的频率被限制到 3.2GHz,而 E 核运行在 2.6GHz。我使用 Intel VTune 的平台视图来捕获 CPU 频率,如 [IntelVtuneOverview] 所示。
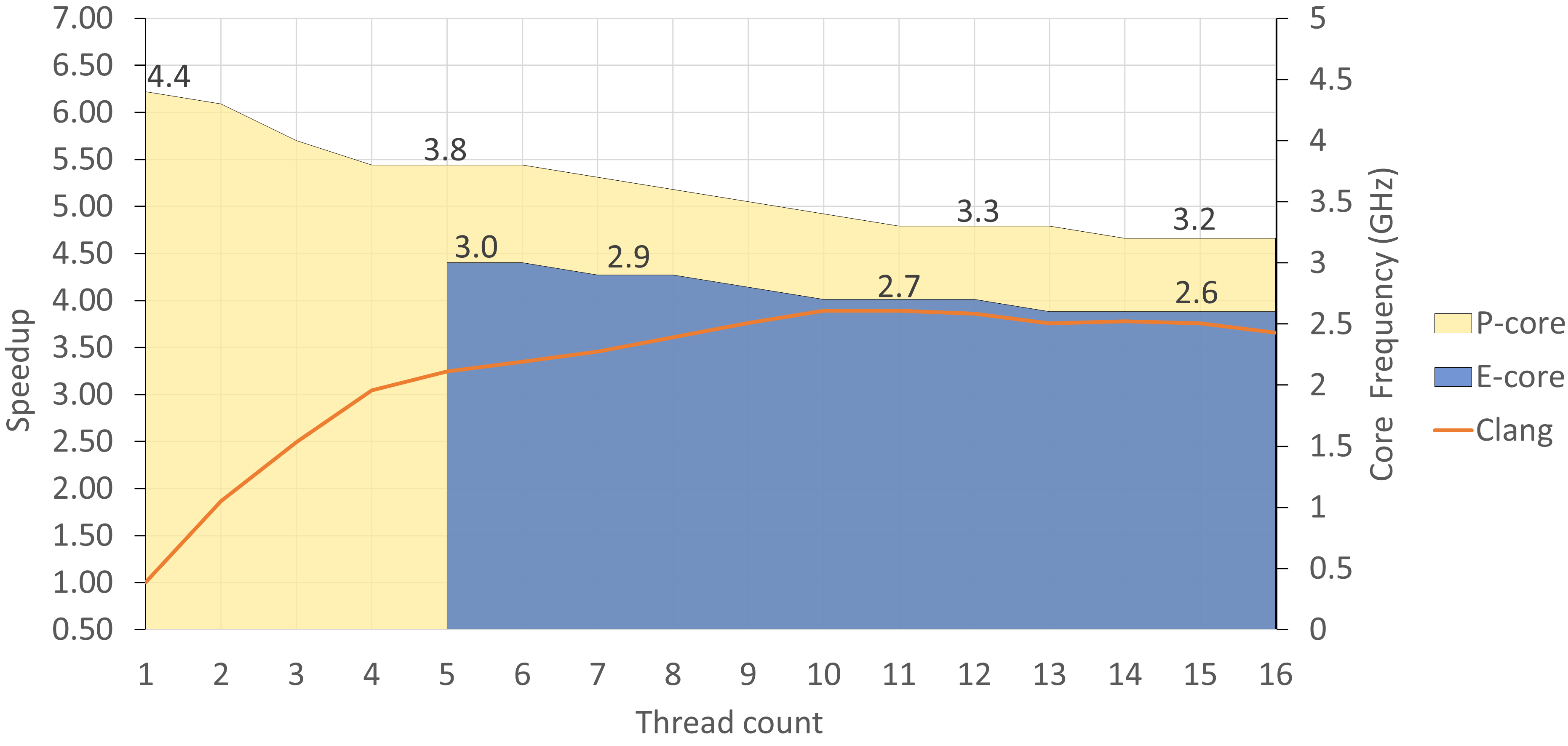
在 Intel® Core™ i7-1260P 上运行 Clang 编译时的频率降速。E 核只有在 P 核上使用了四个线程后才会变得活跃。
Clang 工作负载的性能扩展临界点约在 10 个线程处。这是频率降速开始对性能产生重大影响的点,添加额外线程的收益小于在较低频率下运行的惩罚。
请记住,此频率图表不能自动应用于所有其他工作负载。大量使用 SIMD 指令的应用程序通常在较低频率下运行,因此 Blender 例如可能会比 Clang 看到稍多的频率降速。然而,这样的图表可以让你对平台上发生的频率降速问题有良好的直觉。
为了确认频率降速是性能下降的主要原因之一,我在平台上临时禁用了 Turbo Boost,并重复了 Blender 和 Clang 的扩展研究。禁用 Turbo Boost 时,所有核心在其基础频率下运行,P 核为 2.1 GHz,E 核为 1.5 GHz。结果如图 ScalabilityNoTurboChart 所示。如你所见,当使用所有 16 个线程且禁用 TurboBoost 时,线程数扩展几乎翻倍,对 Blender(38% → 69%)和 Clang(21% → 41%)都是如此。这让我们直观地了解了如果频率降速没有发生,线程数扩展会是什么样子。事实上,频率降速占据了现代系统中大量未实现性能扩展的原因。
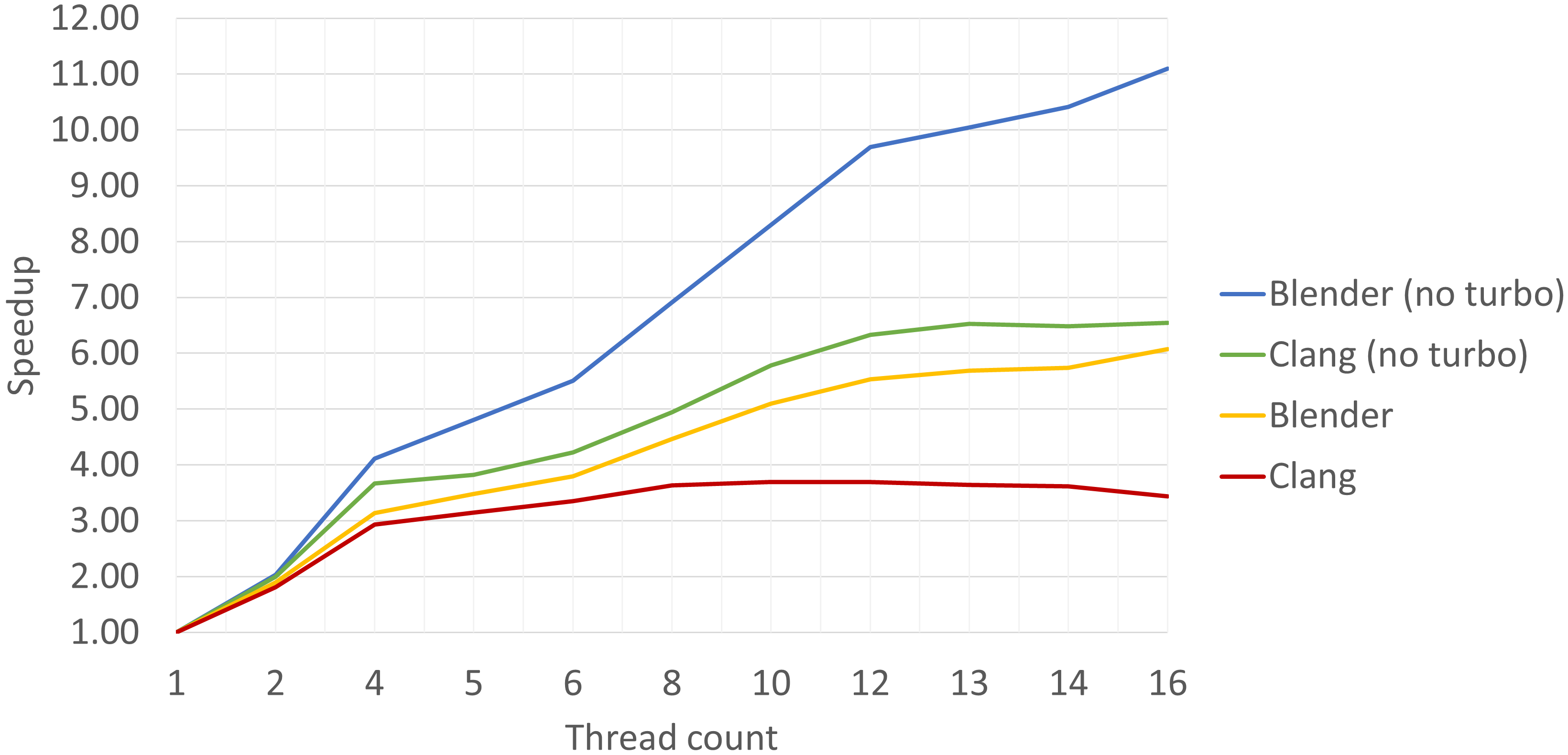
禁用 Turbo Boost 后 Blender 和 Clang 的线程数可扩展性图表。频率降速是实现良好线程数扩展的主要障碍。
Zstandard
接下来是 Zstandard 压缩算法,简称 Zstd。压缩数据时,Zstd 将输入分成块,每块可以独立压缩。这意味着多个线程可以同时压缩不同的块。尽管看起来 Zstd 应该能随线程数良好扩展,但实际并非如此。性能扩展在约 5 个线程时停止,比前两个基准测试更早。正如你将看到的,Zstd 工作线程之间的动态交互相当复杂。
首先,Zstd 的性能取决于压缩级别。压缩级别越高,结果越紧凑。较低的压缩级别提供更快的压缩,而较高的级别产生更好的压缩比。在本案例研究中,我使用了压缩级别 3(这也是默认级别),因为它在速度和压缩比之间提供了良好的权衡。
以下是 Zstd 压缩的高级算法:
- 输入文件被分成块,块大小取决于压缩级别。每个任务负责压缩一块数据。当 Zstd 接收到要压缩的数据时,主线程将一小块数据复制到其内部缓冲区之一,并发布一个新的压缩任务,由一个工作线程接取。类似地,主线程为所有工作线程填充所有输入缓冲区,并按顺序将它们发送去工作。工作线程共享一个公共队列,从中并发地接取任务。
- 任务始终按顺序开始,但可以以任何顺序完成。压缩速度可能是可变的,取决于要压缩的数据。有些块比其他块更容易压缩。
- 工作线程完成压缩块后,它向主线程发出信号,表明压缩数据已准备好刷新到输出文件。主线程负责将压缩数据刷新到输出文件。注意,刷新必须按顺序进行,这意味着只有在第一个任务完全刷新后,第二个任务才允许刷新。主线程可以"部分刷新"正在进行的任务,即不必等待任务完全完成就可以开始刷新。
为了在时间线上可视化 Zstd 算法的工作,我使用 VTune 的 ITT(Instrumentation and Tracing Technology,仪器化与追踪技术)标记2对 Zstd 源代码进行了仪器化。它们使我们能够在时间线上可视化仪器化代码区域和事件的持续时间,并控制执行期间的跟踪数据收集。
使用 8 个线程压缩 Silesia 语料库的时间线如图 ZstdTimeline 所示。使用 8 个工作线程足以观察 Zstd 中的线程交互,同时使图像比所有 16 个线程活跃时的噪音更少。时间线的后半部分被截断以使图像适合页面。
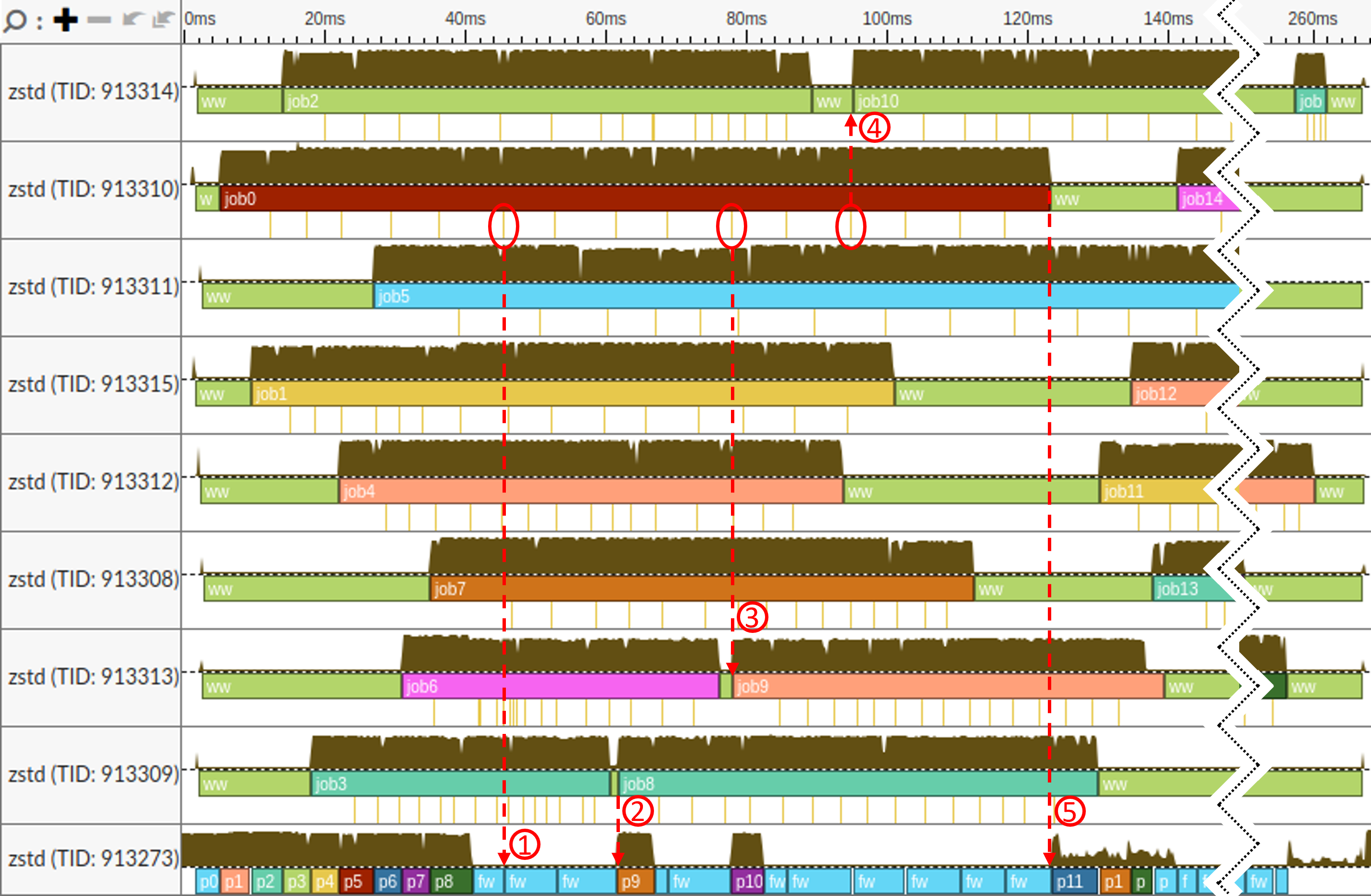
使用 8 个线程压缩 Silesia 语料库的 Zstandard 时间线视图。
在图像中,底部是主线程(TID 913273),顶部是八个工作线程。工作线程在压缩过程开始时创建,并被多个压缩任务重复使用。
在工作线程时间线(顶部 8 行)上,我们有以下标记:
job0--job25条表示任务的开始和结束。ww("worker wait"的缩写,绿色条)条表示工作线程等待新任务的时段。- 任务期间下方的缺口表示线程刚刚完成压缩输入块的一部分,并向主线程发出信号,表明有数据可以刷新(部分刷新)。
在主线程时间线(底部行,TID 913273)上,我们有以下标记:
p0--p25框表示准备新任务的时段。从主线程开始填充输入缓冲区到缓冲区填满开始(但此新任务不一定立即发布到工作队列中)。fw("flush wait"的缩写,蓝色条)标记表示主线程等待已生产数据以开始刷新的时段。这发生在主线程已准备好下一个任务且无其他事情可做的情况下。在此期间,主线程被阻塞。
快速浏览图像,我们可以看到有很多 ww 时段,工作线程在等待。这对 Zstandard 压缩的性能有负面影响。让我们按时间线推进并尝试理解发生了什么。
- 首先,工作线程创建后没有工作可做,因此它们等待主线程发布新任务。
- 然后主线程开始为工作线程填充输入缓冲区。它准备了任务 0 到 7(见条
p0--p7),工作线程立即接取了这些任务。注意,主线程还准备了job8(p8),但尚未将其发布到工作队列中。这是因为所有工作线程仍然繁忙。 - 主线程完成
p8后,刷新了job0已生产的数据。注意,此时job0已经传递了五部分压缩数据(job0条下方的前五个缺口)。现在,主线程进入第一个fw时段,开始等待来自job0的更多数据。 - 在时间戳
45ms时,job0又生产了一块压缩数据,主线程短暂唤醒来刷新它,见 ①。之后它再次进入睡眠(fw)。 Job3首先完成,但在 TID 913309 接取新任务之前有几毫秒的延迟,见 ②。这是因为job8尚未被主线程发布到队列中。此时,主线程正在等待来自job0的新块压缩数据。几毫秒后数据到达时,主线程唤醒,刷新数据,并注意到有一个空闲工作线程(TID 913309,刚完成job3的那个)。因此,主线程将job8发布到工作队列并开始准备下一个任务(p9)。- TID 913313(见 ③)和 TID 913314(见 ④)也发生了同样的情况。但这次延迟更大。有趣的是,
job10本可以被 TID 913314 或 TID 913312 接取,因为当job10被推送到任务队列时,它们都处于空闲状态。 - 我们本应预期主线程会在
job10发布到队列后立即开始准备job11,就像之前一样。但它没有。这是因为没有可用的输入缓冲区。我们将很快详细讨论这个问题。 - 只有当
job0完成时,主线程才能获取新的输入缓冲区并开始准备job11(见 ⑤)。
正如我们刚才所说,任务之间(例如 job4 和 job11 之间)20--40ms 延迟的原因是缺乏输入缓冲区,而启动新任务准备需要这些缓冲区。Zstd 维护一个单一内存池,为输入和输出缓冲区分配空间。该内存池容易出现碎片化问题,因为它必须提供连续的内存块。当工作线程完成任务时,输出缓冲区等待刷新,但仍占用内存。要开始处理另一个任务,需要另一对缓冲区(一个输入缓冲区和一个输出缓冲区)。
限制内存池容量是减少内存消耗的设计决策。在最坏情况下,可能存在许多"失控"缓冲区,由完成任务非常快的工作线程留下,这些工作线程继续处理下一个任务;同时,刷新队列仍被一个慢任务阻塞,缓冲区无法释放。在这种情况下,内存消耗将会很高,这是不可取的。然而,当前实现的缺点是增加了任务之间的等待时间。
Zstd 压缩算法是线程间复杂交互的一个很好的例子。在时间线上可视化工作线程对于理解线程如何通信和同步极为有帮助,并且对于识别瓶颈很有用。这也是一个很好的提醒:即使你拥有可并行化的工作负载,应用程序的性能也可能受到线程间同步和资源可用性的限制。
CloverLeaf
CloverLeaf 是一个流体动力学工作负载。我们不会深入研究底层算法的细节,因为它与本案例研究无关。CloverLeaf 使用 OpenMP 来并行化工作负载。HPC 工作负载通常扩展良好,因此我们期望 CloverLeaf 也能良好扩展。然而,在我的平台上,使用 3 个线程后性能停止增长。发生了什么?
为了确定扩展不佳的根本原因,我在四个数据点中收集了 TMA 指标(见 [TMA]):分别用 1 个、2 个、3 个和 4 个线程运行 CloverLeaf。一旦我们比较这些性能剖析的性能特征,一件事立即变得清晰:CloverLeaf 的性能受内存带宽限制。表 CloverLeaf_metrics 显示了这些剖析中突出显示使用多线程时内存带宽需求不断增加的相关指标。
| 指标 | 1 线程 | 2 线程 | 3 线程 | 4 线程 |
|---|---|---|---|---|
| TMA::Memory Bound(流水线槽位百分比) | 34.6 | 53.7 | 59.0 | 65.4 |
| TMA::DRAM Memory Bandwidth(周期百分比) | 71.7 | 83.9 | 87.0 | 91.3 |
| 内存带宽利用率(范围,GB/s) | 20-22 | 25-28 | 27-30 | 27-30 |
表:CloverLeaf 工作负载的性能指标。
从这些数字可以看出,随着我们添加更多线程,内存子系统的压力不断增加。TMA::Memory Bound 指标的增加表明线程越来越多地花时间等待数据,完成的有效工作减少。DRAM Memory Bandwidth 指标的增加进一步强调了由于接近带宽限制而损害了性能。内存带宽利用率(Memory Bandwidth Utilization)指标显示了 CloverLeaf 运行时总内存带宽利用率的范围。我通过查看 VTune 平台视图中的内存带宽利用率图表来捕获这些数字,如图 CloverLeafMemBandwidth 所示。
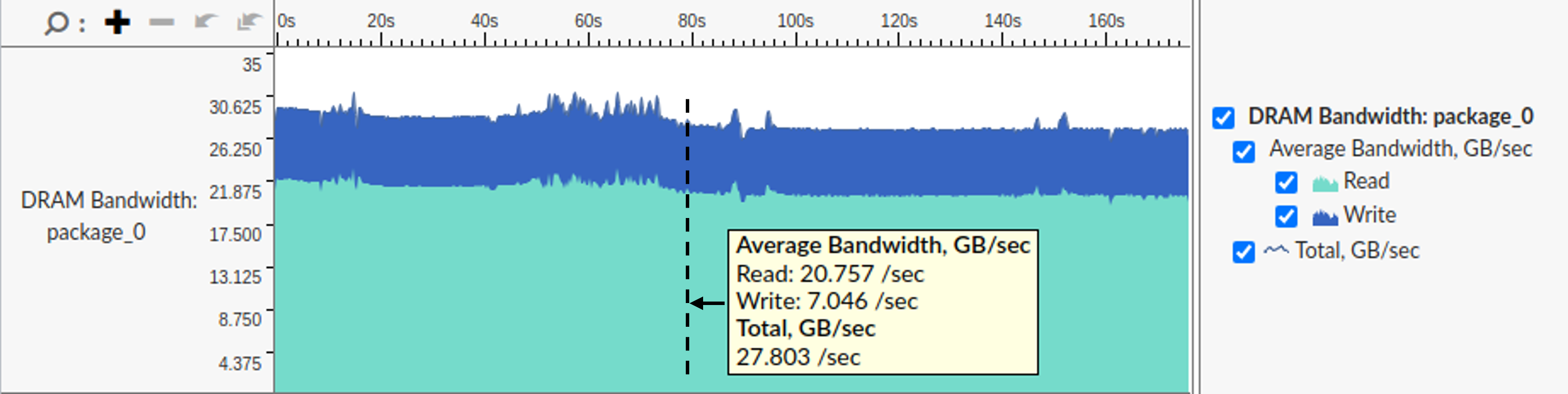
使用 3 个线程运行 CloverLeaf 的 VTune 平台视图。
让我们将这些数字放在上下文中。我平台的最大理论内存带宽为 38.4 GB/s。然而,如我在 [MemLatBw] 中测量的,实际可实现的最大内存带宽为 35 GB/s。仅使用单线程,内存带宽利用率就达到了实际限制的 2/3。CloverLeaf 用三个线程完全饱和了内存带宽。即使所有 16 个线程都活跃时,内存带宽利用率也不超过 30 GB/s,这是实际限制的 86%。
为了验证我的假设,我将两个 8 GB DDR4 2400 MT/s 内存模块替换为相同容量但速度更快的 DDR4 模块:3200 MT/s。这将系统的理论内存带宽提升到 51.2 GB/s,实际最大值提升到 45 GB/s。由此带来的性能提升随着使用线程数的增加而增长,范围在 10% 到 33% 之间。使用 16 个线程运行 CloverLeaf 时,更快的内存模块提供了预期的 33% 性能提升,这与内存带宽增加的比例一致(3200 / 2400 = 1.33)。但即使使用单线程,也有 10% 的性能提升。这意味着在原始配置中,CloverLeaf 有时会以单线程完全饱和内存带宽。
有趣的是,对于 CloverLeaf,当使用所有 16 个线程时,TurboBoost 不提供任何性能优势,即无论是否启用 Turbo,性能都相同,或者让核心以基础频率运行。这怎么可能?答案是:16 个活跃线程足以饱和两个内存控制器,即使 CPU 核心以一半频率运行。由于大多数时候线程只是在等待数据,当你禁用 Turbo 时,它们只是开始"更慢地等待"。
CPython
案例研究中的最后一个基准测试是 CPython。我编写了一个简单的多线程 Python 脚本,使用二分查找在有序列表(haystack)中查找数字(needles)。needles 在工作线程之间均等分配。我写的脚本完全没有扩展。你能猜到为什么吗?
为了解决这个谜题,我从源代码构建了带调试信息的 CPython 3.12,并在使用两个线程时运行了 Intel VTune 的线程分析(Threading Analysis)收集。图 CPythontimeline 可视化了 Python 脚本执行时间线的一小部分。如你所见,CPU 时间在两个线程之间交替。它们工作 5 毫秒,然后让给另一个线程。事实上,如果你向左或向右滚动,你会发现它们从不同时运行。

使用两个工作线程运行 Python 脚本时 VTune 的时间线视图(其他线程已过滤掉)。
让我们尝试理解为什么两个工作线程轮流而不是一起运行。一旦线程完成其轮次,Linux 内核调度器就会切换到另一个线程,如图 CPythontimeline 中突出显示的那样。它还给出了上下文切换的原因。如果我们查看 pthread_cond_wait.c 源代码3的第 652 行,我们会发现函数 ___pthread_cond_timedwait64,它等待条件变量被通知。许多其他非活跃等待时段也以相同的原因等待。
在自下而上(Bottom-up)页面(见图 CPythonBottomUp 的左侧面板),VTune 报告 ___pthread_cond_timedwait64 函数负责大部分非活跃同步等待时间(Inactive Sync Wait Time)。在右侧面板中,你可以看到相应的调用堆栈。使用此调用堆栈,我们可以确定导致 ___pthread_cond_timedwait64 函数和后续上下文切换的最常用代码路径。
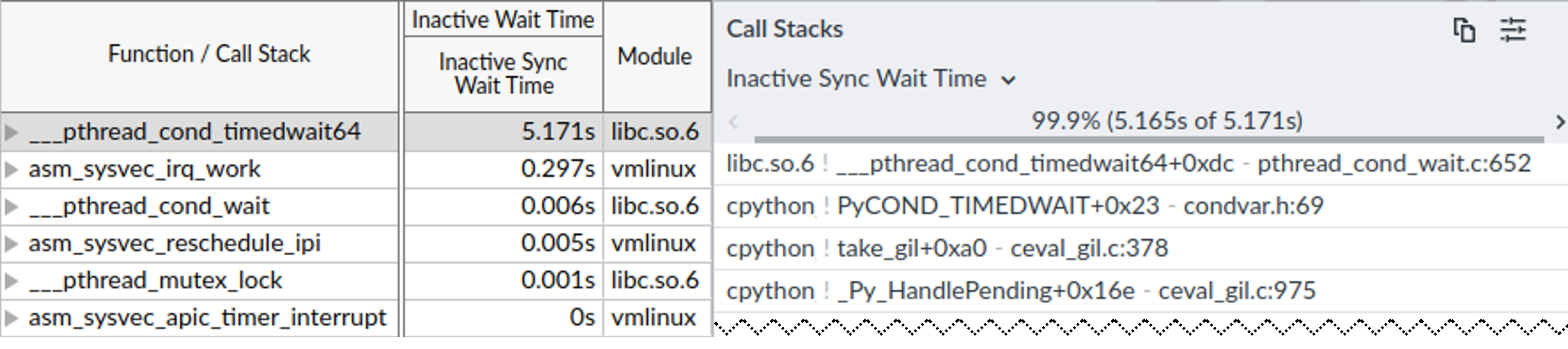
使用两个线程运行 Python 脚本时 VTune 的时间线视图(其他线程已过滤掉)。
此调用堆栈引导我们到 take_gil 函数,该函数负责获取全局解释器锁(Global Interpreter Lock,GIL)。GIL 通过在任何给定时间只允许一个线程运行来阻止我们并行运行工作线程的尝试,从而有效地将我们的多线程程序变成单线程程序。如果你查看 take_gil 函数的实现,你会发现它使用了带有 5ms 超时的条件变量等待版本。一旦超时到达,等待线程会要求持有 GIL 的线程释放它。一旦另一个线程响应请求,等待线程获取 GIL 并开始运行。它们一直保持这种角色切换,直到执行结束。
有经验的 Python 程序员会立即理解这个问题,但在这个例子中,我演示了如何在没有 CPython 内部知识的情况下找到竞争锁。CPython 是默认且迄今为止使用最广泛的 Python 解释器。不幸的是,它带有 GIL,这会破坏计算密集型多线程 Python 程序的性能。
尽管如此,有一些方法可以绕过 GIL,例如,使用 GIL 免疫库(如 NumPy),将代码的性能关键部分编写为 C 扩展模块,或使用替代运行时环境(如 nogil)。4 此外,在 Python 3.13 中,有实验性支持在禁用全局解释器锁的情况下运行。6
总结
在本案例研究中,我们分析了几个具有不同线程数扩展特性的面向吞吐量的应用程序。以下是我们发现的快速摘要:
- 频率降速是实现良好线程数扩展的主要障碍。任何使用多个硬件线程的应用程序都会因热限制而遭受频率下降。具有更高 TDP(热设计功耗,Thermal Design Power)处理器和高级液冷解决方案的平台更不容易受到频率降速的影响。
- 混合处理器(具有高性能核心和能效核心)上的线程数扩展受到惩罚,因为 E 核的性能低于 P 核。一旦 E 核开始被使用,性能扩展就会放缓。兄弟 SMT 线程也不能提供良好的性能扩展。
- 面向吞吐量工作负载中的工作线程共享一组公共资源,这些资源可能成为瓶颈。正如我们在 CloverLeaf 示例中所看到的,由于内存带宽限制,性能无法扩展。这是许多 HPC 和 AI 工作负载的常见问题。一旦达到该限制,其他一切都变得不那么重要,包括代码优化甚至 CPU 频率。L3 缓存和 I/O 是通常成为瓶颈的共享资源的其他例子。
- 最后,并发应用程序的性能可能受到线程间同步的限制,正如我们在 Zstd 和 CPython 示例中所看到的。一些程序的线程间交互非常复杂,因此在时间线上可视化工作线程非常有用。此外,你应该了解如何使用性能分析工具找到竞争锁。
为了确认次优扩展是常见情况而非例外,让我们看看 SPEC CPU 2017 基准测试套件。在套件的 rate 部分,每个硬件线程运行自己的单线程工作负载,因此没有因线程同步引起的减速。根据 [MICRO23DebbieMarr],具有整数代码(常规通用程序)的基准测试的线程数扩展在 40% - 70% 范围内,而具有浮点代码(科学、媒体和工程程序)的基准测试的扩展在 20% - 65% 范围内。这些数字代表仅由硬件平台引起的低效率。多线程程序中线程同步引起的低效率进一步降低了性能扩展。
在延迟导向型应用程序中,你通常有几个性能关键线程,其余线程做后台工作,不一定需要很快。我们讨论的许多问题也适用于延迟导向型应用程序。我们在 [LowLatency] 中介绍了一些低延迟调优技术。
2. VTune ITT instrumentation - https://www.intel.com/content/www/us/en/docs/vtune-profiler/user-guide/2023-1/instrumenting-your-application.html ↩
3. Glibc source code - https://sourceware.org/git/?p=glibc.git;a=tree ↩
4. Nogil - https://github.com/colesbury/nogil ↩
5. 你也可以将 SMT 扩展测量为4T2C/2T2C、6T3C/3T3C,以此类推。 ↩
6. Python 3.13 release notes - https://docs.python.org/3/whatsnew/3.13.html ↩