缓存友好的数据结构
编写缓存友好(cache-friendly)的算法和数据结构是高性能应用程序的关键要素之一。缓存友好代码的核心支柱是我们在 [MemHierar] 中介绍的时间局部性(temporal locality)和空间局部性(spatial locality)原则。目标是拥有可预测的内存访问模式并高效地存储数据。
缓存行(cache line)是缓存与主存之间可以传输的最小数据单位。在设计缓存友好的代码时,不仅要考虑单个变量及其在内存中的位置,还要考虑缓存行。
下面我们将讨论几种使数据结构更加缓存友好的技术。
顺序访问数据
利用缓存空间局部性的最佳方式是进行顺序内存访问。通过这样做,我们使硬件预取机制(hardware prefetching mechanism,参见 [HwPrefetch])能够识别内存访问模式并提前获取下一块数据。代码清单 CacheFriend 展示了行优先(Row-major)与列优先(Column-Major)遍历的示例。注意,代码中只有一个微小的变化(交换了 col 和 row 的下标),但对性能有很大影响。
左边的代码对缓存不友好,因为它在内循环的每次迭代中跳过了 NCOLS 个元素。这导致缓存利用效率非常低:在整个预取的缓存行被逐出之前,我们无法充分利用它。相反,右边的代码按照矩阵元素在内存中的布局顺序访问它们。这保证了缓存行在被逐出之前会被完全使用。行优先遍历充分利用了空间局部性,是缓存友好的。图 ColRowMajor 说明了两种遍历模式之间的差异。
代码清单:缓存友好的内存访问。
// Column-major order // Row-major order
for (row = 0; row < NROWS; row++) for (row = 0; row < NROWS; row++)
for (col = 0; col < NCOLS; col++) for (col = 0; col < NCOLS; col++)
matrix[col][row] = row + col; => matrix[row][col] = row + col;
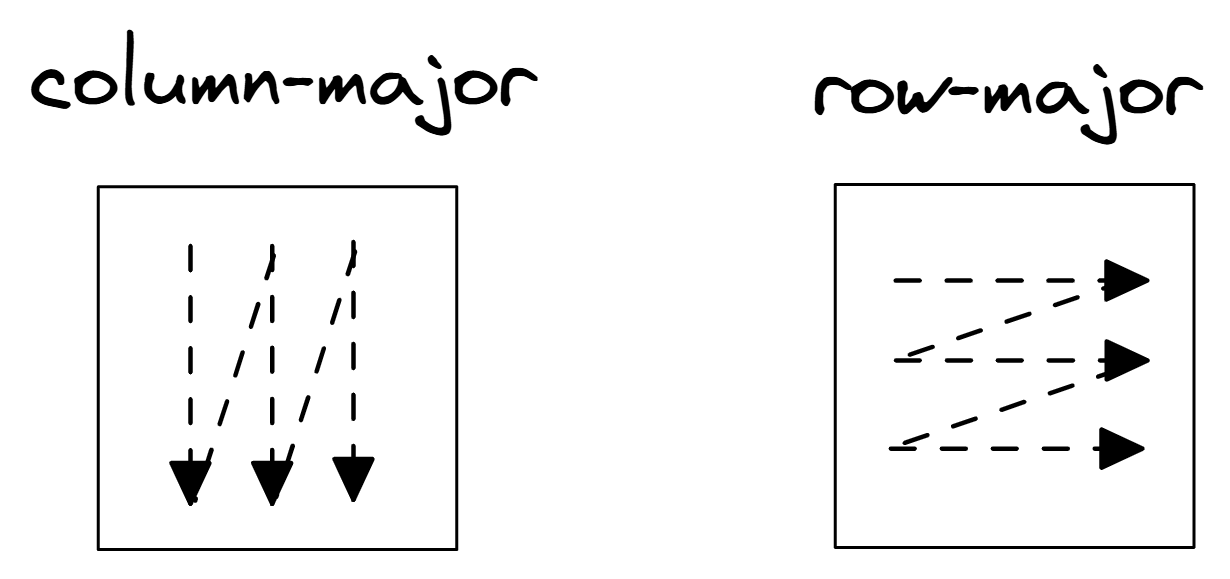
列优先与行优先遍历。
上面展示的示例是经典的,但通常真实世界的应用程序要复杂得多。有时需要付出额外的努力才能编写缓存友好的代码。如果数据在内存中的布局方式对算法来说不是最优的,可能需要先重新排列数据。
考虑在大型有序数组中进行二分搜索的标准实现,其中每次迭代都访问中间元素,将其与要搜索的值进行比较,然后向左或向右移动。该算法没有利用空间局部性,因为它测试的元素位于不同的位置,彼此相距很远,不共享同一缓存行。解决这个问题最著名的方法是使用 Eytzinger 布局(Eytzinger layout)[EytzingerArray] 存储数组元素。其思想是将二叉搜索树隐式地打包进一个数组中,采用类似 BFS 的布局,通常见于二叉堆(binary heap)。如果代码需要对数组执行大量二分搜索,将其转换为 Eytzinger 布局可能是有益的。
使用合适的容器
几乎任何语言都有大量现成的容器可供使用。但了解它们的底层存储和性能影响非常重要。要考虑数据将如何被访问和操作。不仅要考虑数据结构操作的时间和空间复杂度,还要考虑与之相关的硬件效应。
默认情况下,应避免使用依赖指针的数据结构,例如链表或树。遍历元素时,它们需要额外的内存访问来追踪指针。如果元素的最大数量相对较小且在编译时已知,C++ 的 std::array 可能比 std::vector 更好。如果需要关联容器但不需要按排序顺序存储元素,std::unordered_map 应该比 std::map 更快。在 [fogOptimizeCpp] 中可以找到选择合适 C++ 容器的分步指南。
有时,存储指向包含对象的指针比存储对象本身更高效。考虑这样一种情况:需要在数组中存储许多对象,而每个对象的大小很大,此外对象频繁地被洗牌、删除和插入。将对象存储在数组中,每次对象顺序发生变化时都需要移动大量内存,这代价昂贵。在这种情况下,最好在数组中存储指向对象的指针。这样,只需移动指针,代价小得多。然而,这种方法也有其缺点:它需要额外的指针内存,并引入了额外的间接层级。
数据压缩(Packing the Data)
通过使数据更紧凑,也可以提升数据缓存的利用率。有很多压缩数据的方法。一个经典示例是使用位域(bitfields)。代码清单 DataPacking 展示了数据压缩可能有益的代码示例。如果我们知道 a、b 和 c 表示需要一定位数编码的枚举值,我们可以减少结构体 S 的存储。
代码清单:数据压缩。
// S is 3 bytes // S is 1 byte
struct S { struct S {
unsigned char a; unsigned char a:4;
unsigned char b; => unsigned char b:2;
unsigned char c; unsigned char c:2;
}; };
注意,存储压缩版 S 对象所需的空间减少了三倍。这大大减少了来回传输的内存量,并节省了缓存空间。然而,使用位域会带来额外开销。15 由于 a、b 和 c 的位被压缩进一个字节,编译器需要执行额外的位操作来提取和插入它们。例如,要加载 b,需要将字节值右移(>>)2 位,然后与 0x3 进行逻辑与(&)操作。类似地,需要左移(<<)和逻辑或(|)操作将更新后的值存回压缩格式。在额外计算比低效内存传输引起的延迟更便宜的场合,数据压缩是有益的。
此外,程序员可以通过重新排列结构体或类中的字段来减少内存使用,从而避免编译器添加的填充(padding)。插入未使用的内存字节(填充)可以使结构体的各成员高效地存储和获取。在代码清单 AvoidPadding 的示例中,如果成员按大小递减的顺序声明,S 的大小可以减小。图 AvoidPadding 说明了重新排列结构体 S 字段的效果。
代码清单:避免编译器填充。
// S is `sizeof(int) * 3` bytes // S is `sizeof(int) * 2` bytes
struct S { struct S {
bool b; int i;
int i; => short s;
short s; bool b;
}; };

通过重新排列字段避免编译器填充。空白单元格表示编译器填充。
字段重排序(Field Reordering)
重新排列数据结构中的字段出于另一个原因也可能是有益的。考虑代码清单 FieldReordering 中的示例。假设 Soldier 结构体用于在游戏中跟踪战场上数千个单位中的每一个。游戏有三个阶段:战斗、移动和交易。在战斗阶段,使用 attack、defense 和 health 字段。在移动阶段,使用 coords 和 speed 字段。在交易阶段,只使用 money 字段。
左边代码中 Soldier 结构体的组织问题是字段没有按游戏阶段分组。例如,在战斗阶段,程序需要访问两个不同的缓存行来获取所需字段。attack 和 defense 字段很可能位于同一缓存行,但 health 字段总是被推到下一个缓存行。移动阶段也是如此(speed 和 coords 字段)。
通过如代码清单 FieldReordering 右边所示重新排列字段,可以使 Soldier 结构体更加缓存友好。通过这一改变,一起访问的字段被分组在一起。
代码清单:字段重排序。
struct Soldier { struct Soldier {
2DCoords coords; /* 8 bytes */ unsigned attack; // 1. battle
unsigned attack; unsigned defense; // 1. battle
unsigned defense; => unsigned health; // 1. battle
/* other fields */ /* 64 bytes */ 2DCoords coords; // 2. move
unsigned speed; unsigned speed; // 2. move
unsigned money; // other fields
unsigned health; unsigned money; // 3. trade
}; };
自 Linux 内核 6.8 起,perf 工具新增了一项功能,允许您发现数据结构重排序的机会。perf mem record 命令现在可用于分析数据结构访问模式。perf annotate --data-type 命令将显示数据结构布局以及归因于数据结构每个字段的性能分析样本。利用这些信息,您可以识别一起访问的字段。5
数据类型分析(Data-type profiling)在发现改善缓存利用率的机会方面非常有效。Linux 内核的近期历史中包含许多重新排列结构体1、填充字段3或压缩2字段以提升性能的提交示例。
其他数据结构重组技术
为了结束缓存友好数据结构这一主题,我们将简要提及另外两种可用于改善缓存利用率的技术:结构体分割(structure splitting) 和指针内联(pointer inlining)。
结构体分割。将一个大结构体分割成较小的结构体可以提升缓存利用率。例如,如果您有一个包含大量字段的结构体,但其中只有少数字段会一起访问,您可以将该结构体分割成两个或更多较小的结构体。这样,您可以避免将不必要的数据加载到缓存中。代码清单 StructureSplitting 展示了结构体分割的示例。通过将 Point 结构体分割为 PointCoords 和 PointInfo,我们可以在只需要 PointCoords 时避免将 PointInfo 数据加载到缓存中。这样,我们可以在单个缓存行上容纳更多点。
代码清单:结构体分割。
struct Point { struct PointCoords {
int X; int X;
int Y; int Y;
int Z; int Z;
/*many other fields*/ => };
}; struct PointInfo {
std::vector<Point> points; /*many other fields*/
};
std::vector<PointCoords> pointCoords;
std::vector<PointInfo> pointInfos;
指针内联。将指针内联到结构体中可以提升缓存利用率。例如,如果您有一个包含指向另一个结构体的指针的结构体,您可以将该指针内联到第一个结构体中。这样,您可以避免获取第二个结构体时的额外内存访问。代码清单 PointerInlining 展示了指针内联的示例。weight 参数在许多图算法中使用,因此经常被访问。然而,在左边的原始版本中,获取边权重需要额外的内存访问,可能导致缓存缺失。通过将 weight 参数移入 GraphEdge 结构体,我们避免了此类问题。
代码清单:将 weight 参数移入父结构体。
struct GraphEdge { struct GraphEdge {
unsigned int from; unsigned int from;
unsigned int to; unsigned int to;
GraphEdgeProperties* prop; float weight;
}; => GraphEdgeProperties* prop;
struct GraphEdgeProperties { };
float weight; struct GraphEdgeProperties {
std::string label; std::string label;
// ... // ...
}; };
1. Linux 提交 54ff8ad69c6e93c0767451ae170b41c000e565dd ↩
2. Linux 提交 e5598d6ae62626d261b046a2f19347c38681ff51 ↩
3. Linux 提交 aee79d4e5271cee4ffa89ed830189929a6272eb8 ↩
5. Linux perf 数据类型分析 - https://lwn.net/Articles/955709/ ↩
12. aligned_alloc - https://en.cppreference.com/w/c/memory/aligned_alloc ↩
13. Linux memalign 手册页 - https://linux.die.net/man/3/memalign ↩
14. 生成对齐内存 - https://embeddedartistry.com/blog/2017/02/22/generating-aligned-memory/ ↩
15. 此外,不能获取位域的地址。 ↩